 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized multi-class classification under system constraints: a unified approach via post-processing
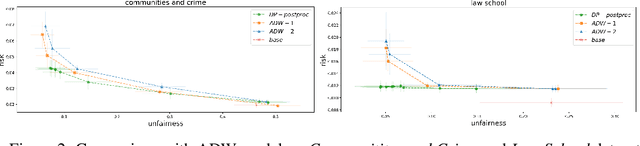
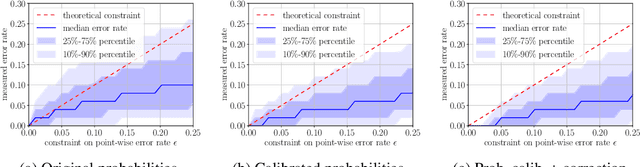
Dec 16, 2025We study the problem of multi-class classification under system-level constraints expressible as linear functionals over randomized classifiers. We propose a post-processing approach that adjusts a given base classifier to satisfy general constraints without retraining. Our method formulates the problem as a linearly constrained stochastic program over randomized classifiers, and leverages entropic regularization and dual optimization techniques to construct a feasible solution. We provide finite-sample guarantees for the risk and constraint satisfaction for the final output of our algorithm under minimal assumptions. The framework accommodates a broad class of constraints, including fairness, abstention, and churn requirements.
Set to Be Fair: Demographic Parity Constraints for Set-Valued Classification
Oct 06, 2025



Set-valued classification is used in multiclass settings where confusion between classes can occur and lead to misleading predictions. However, its application may amplify discriminatory bias motivating the development of set-valued approaches under fairness constraints. In this paper, we address the problem of set-valued classification under demographic parity and expected size constraints. We propose two complementary strategies: an oracle-based method that minimizes classification risk while satisfying both constraints, and a computationally efficient proxy that prioritizes constraint satisfaction. For both strategies, we derive closed-form expressions for the (optimal) fair set-valued classifiers and use these to build plug-in, data-driven procedures for empirical predictions. We establish distribution-free convergence rates for violations of the size and fairness constraints for both methods, and under mild assumptions we also provide excess-risk bounds for the oracle-based approach. Empirical results demonstrate the effectiveness of both strategies and highlight the efficiency of our proxy method.
Regression under demographic parity constraints via unlabeled post-processing
Jul 22, 2024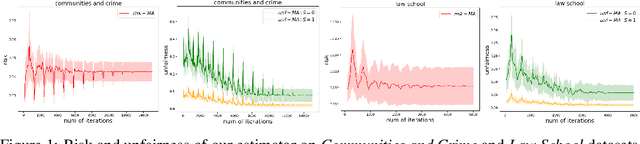

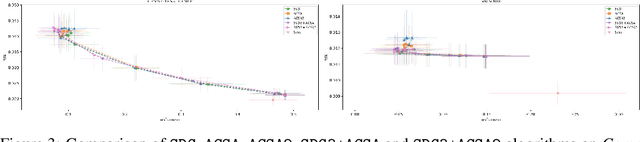
We address the problem of performing regression while ensuring demographic parity, even without access to sensitive attributes during inference. We present a general-purpose post-processing algorithm that, using accurate estimates of the regression function and a sensitive attribute predictor, generates predictions that meet the demographic parity constraint. Our method involves discretization and stochastic minimization of a smooth convex function. It is suitable for online post-processing and multi-class classification tasks only involving unlabeled data for the post-processing. Unlike prior methods, our approach is fully theory-driven. We require precise control over the gradient norm of the convex function, and thus, we rely on more advanced techniques than standard stochastic gradient descent. Our algorithm is backed by finite-sample analysis and post-processing bounds, with experimental results validating our theoretical findings.
EERO: Early Exit with Reject Option for Efficient Classification with limited budget
Feb 06, 2024The increasing complexity of advanced machine learning models requires innovative approaches to manage computational resources effectively. One such method is the Early Exit strategy, which allows for adaptive computation by providing a mechanism to shorten the processing path for simpler data instances. In this paper, we propose EERO, a new methodology to translate the problem of early exiting to a problem of using multiple classifiers with reject option in order to better select the exiting head for each instance. We calibrate the probabilities of exiting at the different heads using aggregation with exponential weights to guarantee a fixed budget .We consider factors such as Bayesian risk, budget constraints, and head-specific budget consumption. Experimental results, conducted using a ResNet-18 model and a ConvNext architecture on Cifar and ImageNet datasets, demonstrate that our method not only effectively manages budget allocation but also enhances accuracy in overthinking scenarios.
Set-valued classification -- overview via a unified framework
Feb 24, 2021
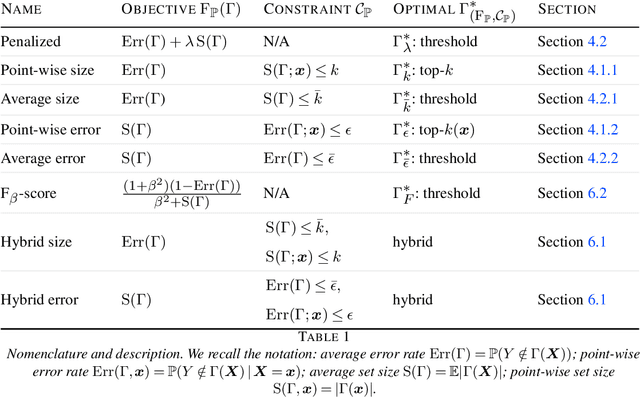

Multi-class classification problem is among the most popular and well-studied statistical frameworks. Modern multi-class datasets can be extremely ambiguous and single-output predictions fail to deliver satisfactory performance. By allowing predictors to predict a set of label candidates, set-valued classification offers a natural way to deal with this ambiguity. Several formulations of set-valued classification are available in the literature and each of them leads to different prediction strategies. The present survey aims to review popular formulations using a unified statistical framework. The proposed framework encompasses previously considered and leads to new formulations as well as it allows to understand underlying trade-offs of each formulation. We provide infinite sample optimal set-valued classification strategies and review a general plug-in principle to construct data-driven algorithms. The exposition is supported by examples and pointers to both theoretical and practical contributions. Finally, we provide experiments on real-world datasets comparing these approaches in practice and providing general practical guidelines.
Regression with reject option and application to kNN
Jun 30, 2020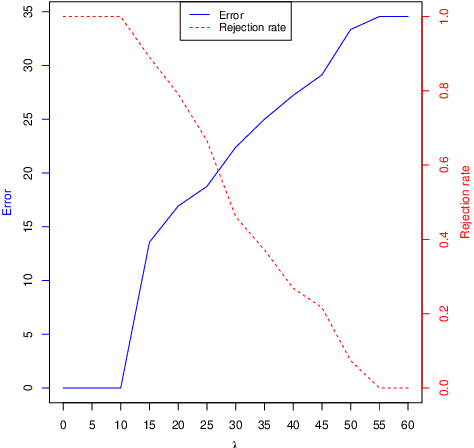
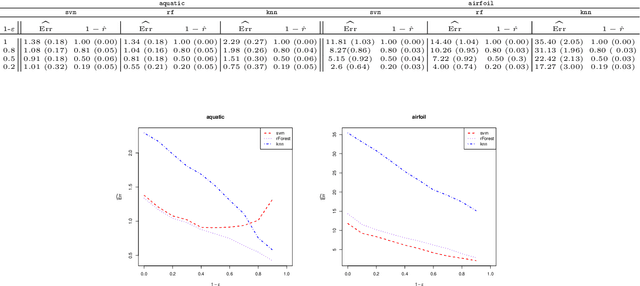
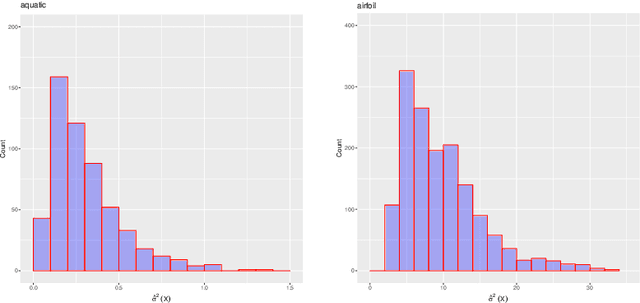
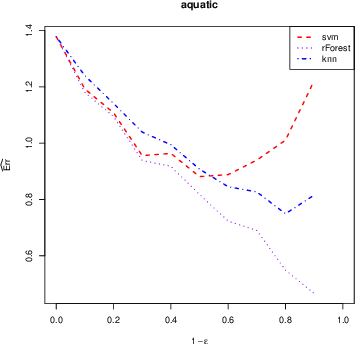
We investigate the problem of regression where one is allowed to abstain from predicting. We refer to this framework as regression with reject option as an extension of classification with reject option. In this context, we focus on the case where the rejection rate is fixed and derive the optimal rule which relies on thresholding the conditional variance function. We provide a semi-supervised estimation procedure of the optimal rule involving two datasets: a first labeled dataset is used to estimate both regression function and conditional variance function while a second unlabeled dataset is exploited to calibrate the desired rejection rate. The resulting predictor with reject option is shown to be almost as good as the optimal predictor with reject option both in terms of risk and rejection rate. We additionally apply our methodology with kNN algorithm and establish rates of convergence for the resulting kNN predictor under mild conditions. Finally, a numerical study is performed to illustrate the benefit of using the proposed procedure.
Layer Sparsity in Neural Networks
Jun 28, 2020

Sparsity has become popular in machine learning, because it can save computational resources, facilitate interpretations, and prevent overfitting. In this paper, we discuss sparsity in the framework of neural networks. In particular, we formulate a new notion of sparsity that concerns the networks' layers and, therefore, aligns particularly well with the current trend toward deep networks. We call this notion layer sparsity. We then introduce corresponding regularization and refitting schemes that can complement standard deep-learning pipelines to generate more compact and accurate networks.
Fair Regression with Wasserstein Barycenters
Jun 23, 2020

We study the problem of learning a real-valued function that satisfies the Demographic Parity constraint. It demands the distribution of the predicted output to be independent of the sensitive attribute. We consider the case that the sensitive attribute is available for prediction. We establish a connection between fair regression and optimal transport theory, based on which we derive a close form expression for the optimal fair predictor. Specifically, we show that the distribution of this optimum is the Wasserstein barycenter of the distributions induced by the standard regression function on the sensitive groups. This result offers an intuitive interpretation of the optimal fair prediction and suggests a simple post-processing algorithm to achieve fairness. We establish risk and distribution-free fairness guarantees for this procedure. Numerical experiments indicate that our method is very effective in learning fair models, with a relative increase in error rate that is inferior to the relative gain in fairness.
Leveraging Labeled and Unlabeled Data for Consistent Fair Binary Classification
Jun 12, 2019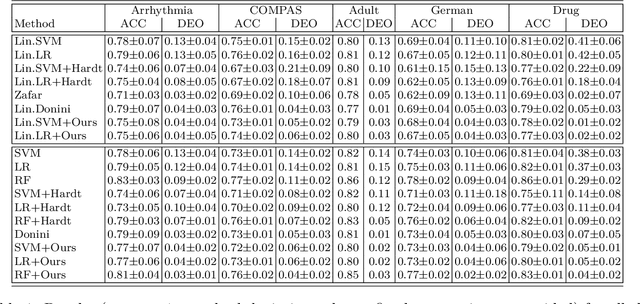
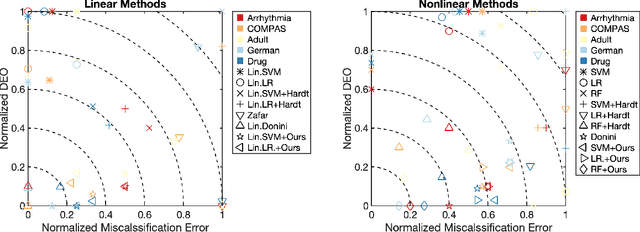
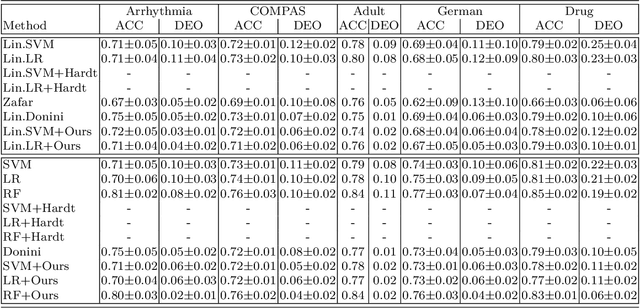
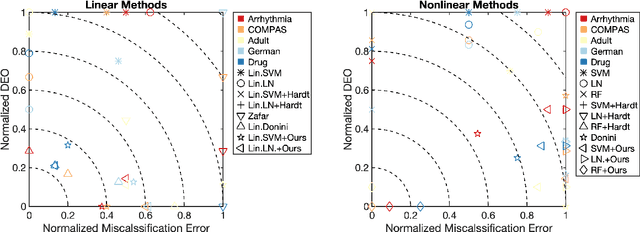
We study the problem of fair binary classification using the notion of Equal Opportunity. It requires the true positive rate to distribute equally across the sensitive groups. Within this setting we show that the fair optimal classifier is obtained by recalibrating the Bayes classifier by a group-dependent threshold. We provide a constructive expression for the threshold. This result motivates us to devise a plug-in classification procedure based on both unlabeled and labeled datasets. While the latter is used to learn the output conditional probability, the former is used for calibration. The overall procedure can be computed in polynomial time and it is shown to be statistically consistent both in terms of classification error and fairness measure. Finally, we present numerical experiments which indicate that our method is often superior or competitive with the state-of-the-art methods on benchmark datasets.
On the benefits of output sparsity for multi-label classification
Mar 14, 2017



The multi-label classification framework, where each observation can be associated with a set of labels, has generated a tremendous amount of attention over recent years. The modern multi-label problems are typically large-scale in terms of number of observations, features and labels, and the amount of labels can even be comparable with the amount of observations. In this context, different remedies have been proposed to overcome the curse of dimensionality. In this work, we aim at exploiting the output sparsity by introducing a new loss, called the sparse weighted Hamming loss. This proposed loss can be seen as a weighted version of classical ones, where active and inactive labels are weighted separately. Leveraging the influence of sparsity in the loss function, we provide improved generalization bounds for the empirical risk minimizer, a suitable property for large-scale problems. For this new loss, we derive rates of convergence linear in the underlying output-sparsity rather than linear in the number of labels. In practice, minimizing the associated risk can be performed efficiently by using convex surrogates and modern convex optimization algorithms. We provide experiments on various real-world datasets demonstrating the pertinence of our approach when compared to non-weighted techniques.