 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALPOLON: A Framework for Deep Species Distribution Modeling
Sep 26, 2024This paper describes a deep-SDM framework, MALPOLON. Written in Python and built upon the PyTorch library, this framework aims to facilitate training and inferences of deep species distribution models (deep-SDM) and sharing for users with only general Python language skills (e.g., modeling ecologists) who are interested in testing deep learning approaches to build new SDMs. More advanced users can also benefit from the framework's modularity to run more specific experiments by overriding existing classes while taking advantage of press-button examples to train neural networks on multiple classification tasks using custom or provided raw and pre-processed datasets. The framework is open-sourced on GitHub and PyPi along with extensive documentation and examples of use in various scenarios. MALPOLON offers straightforward installation, YAML-based configuration, parallel computing, multi-GPU utilization, baseline and foundational models for benchmarking, and extensive tutorials/documentation, aiming to enhance accessibility and performance scalability for ecologists and researchers.
Classification Under Ambiguity: When Is Average-K Better Than Top-K?
Dec 16, 2021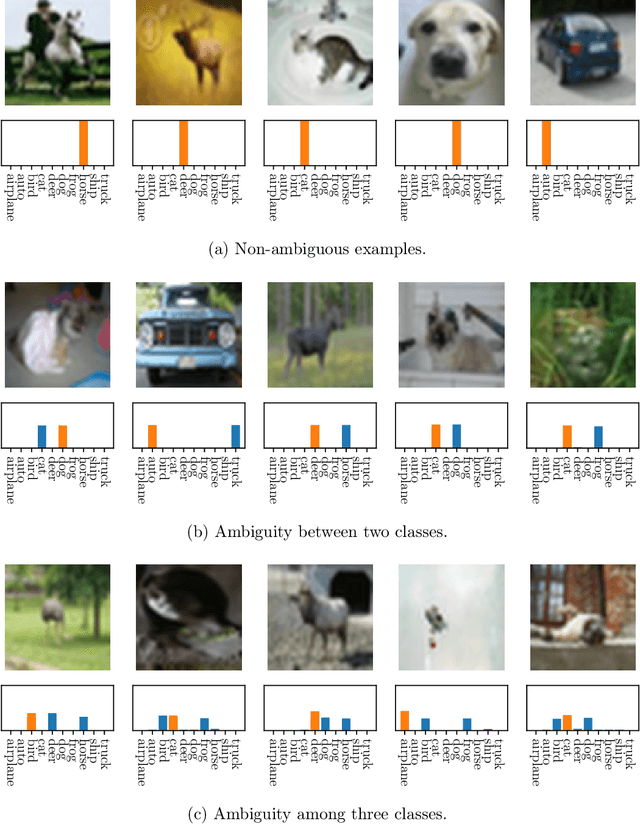

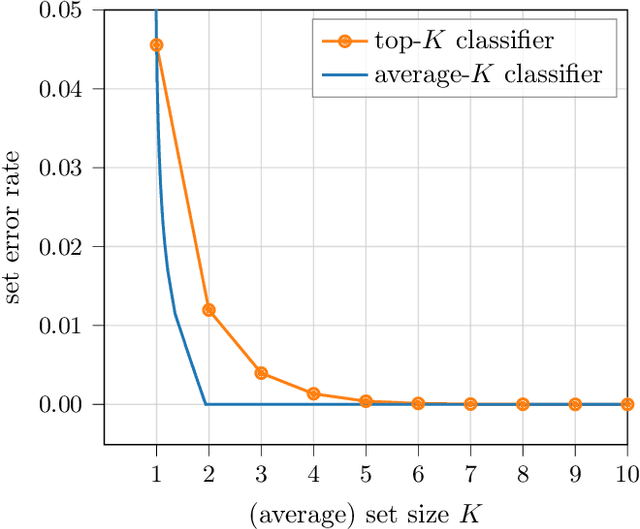
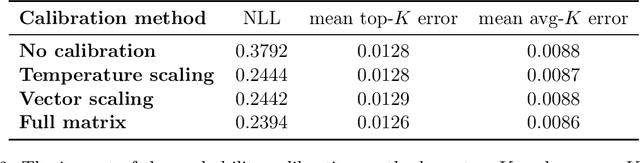
When many labels are possible, choosing a single one can lead to low precision. A common alternative, referred to as top-$K$ classification, is to choose some number $K$ (commonly around 5) and to return the $K$ labels with the highest scores. Unfortunately, for unambiguous cases, $K>1$ is too many and, for very ambiguous cases, $K \leq 5$ (for example) can be too small. An alternative sensible strategy is to use an adaptive approach in which the number of labels returned varies as a function of the computed ambiguity, but must average to some particular $K$ over all the samples. We denote this alternative average-$K$ classification. This paper formally characterizes the ambiguity profile when average-$K$ classification can achieve a lower error rate than a fixed top-$K$ classification. Moreover, it provides natural estimation procedures for both the fixed-size and the adaptive classifier and proves their consistency. Finally, it reports experiments on real-world image data sets revealing the benefit of average-$K$ classification over top-$K$ in practice. Overall, when the ambiguity is known precisely, average-$K$ is never worse than top-$K$, and, in our experiments, when it is estimated, this also holds.
Multi-Label Learning from Single Positive Labels
Jun 17, 2021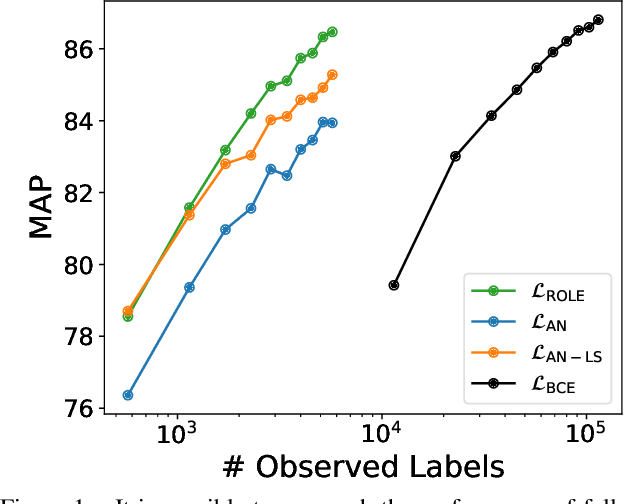
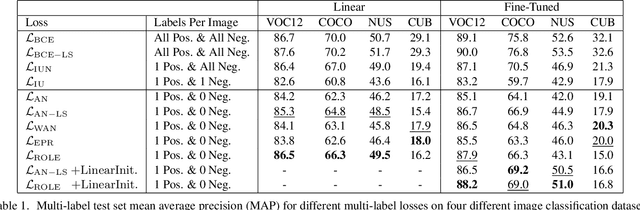
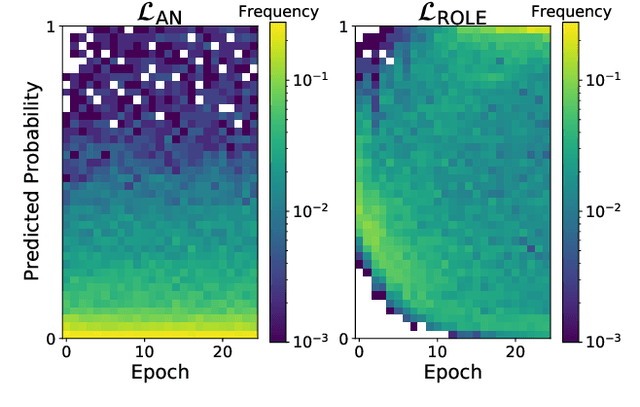
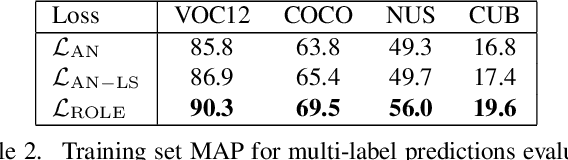
Predicting all applicable labels for a given image is known as multi-label classification. Compared to the standard multi-class case (where each image has only one label), it is considerably more challenging to annotate training data for multi-label classification. When the number of potential labels is large, human annotators find it difficult to mention all applicable labels for each training image. Furthermore, in some settings detection is intrinsically difficult e.g. finding small object instances in high resolution images. As a result, multi-label training data is often plagued by false negatives. We consider the hardest version of this problem, where annotators provide only one relevant label for each image. As a result, training sets will have only one positive label per image and no confirmed negatives. We explore this special case of learning from missing labels across four different multi-label image classification datasets for both linear classifiers and end-to-end fine-tuned deep networks. We extend existing multi-label losses to this setting and propose novel variants that constrain the number of expected positive labels during training. Surprisingly, we show that in some cases it is possible to approach the performance of fully labeled classifiers despite training with significantly fewer confirmed labels.
Set-valued classification -- overview via a unified framework
Feb 24, 2021
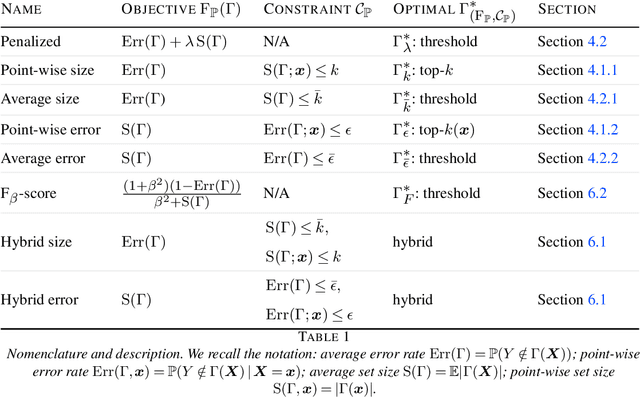

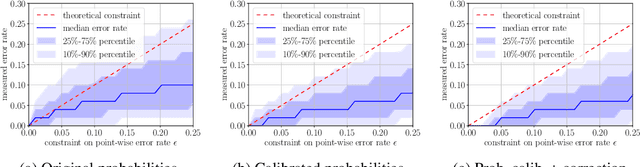
Multi-class classification problem is among the most popular and well-studied statistical frameworks. Modern multi-class datasets can be extremely ambiguous and single-output predictions fail to deliver satisfactory performance. By allowing predictors to predict a set of label candidates, set-valued classification offers a natural way to deal with this ambiguity. Several formulations of set-valued classification are available in the literature and each of them leads to different prediction strategies. The present survey aims to review popular formulations using a unified statistical framework. The proposed framework encompasses previously considered and leads to new formulations as well as it allows to understand underlying trade-offs of each formulation. We provide infinite sample optimal set-valued classification strategies and review a general plug-in principle to construct data-driven algorithms. The exposition is supported by examples and pointers to both theoretical and practical contributions. Finally, we provide experiments on real-world datasets comparing these approaches in practice and providing general practical guidelines.
The GeoLifeCLEF 2020 Dataset
Apr 08, 2020
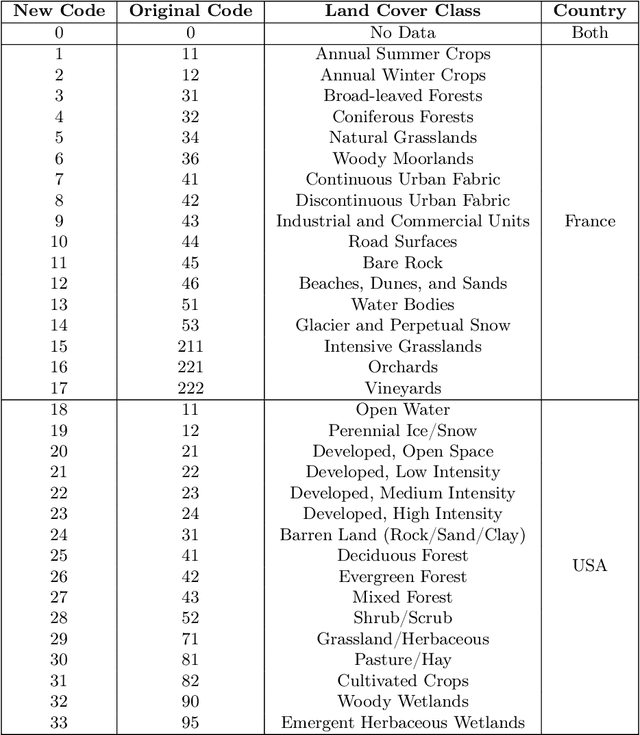
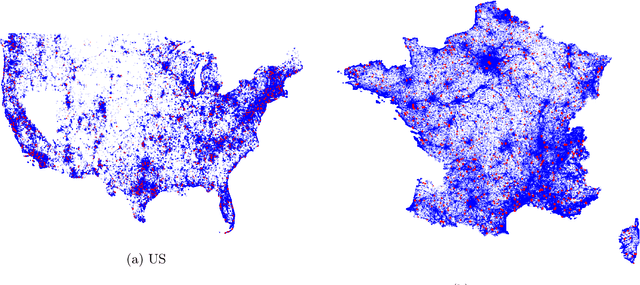
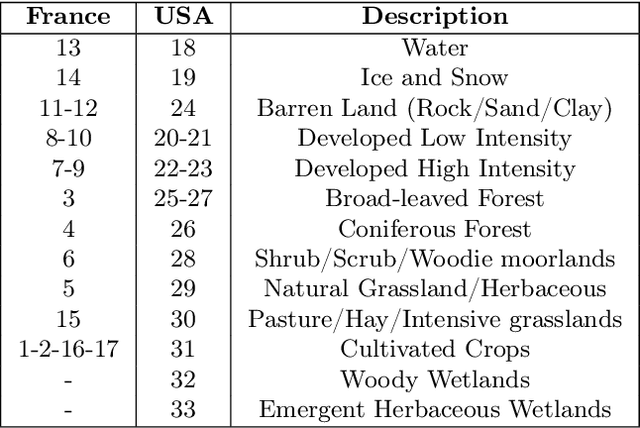
Understanding the geographic distribution of species is a key concern in conservation. By pairing species occurrences with environmental features, researchers can model the relationship between an environment and the species which may be found there. To facilitate research in this area, we present the GeoLifeCLEF 2020 dataset, which consists of 1.9 million species observations paired with high-resolution remote sensing imagery, land cover data, and altitude, in addition to traditional low-resolution climate and soil variables. We also discuss the GeoLifeCLEF 2020 competition, which aims to use this dataset to advance the state-of-the-art in location-based species recommendation.