 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the calibration of compartmental epidemiological models
Dec 09, 2023



Epidemiological compartmental models are useful for understanding infectious disease propagation and directing public health policy decisions. Calibration of these models is an important step in offering accurate forecasts of disease dynamics and the effectiveness of interventions. In this study, we present an overview of calibrating strategies that can be employed, including several optimization methods and reinforcement learning (RL). We discuss the benefits and drawbacks of these methods and highlight relevant practical conclusions from our experiments. Optimization methods iteratively adjust the parameters of the model until the model output matches the available data, whereas RL uses trial and error to learn the optimal set of parameters by maximizing a reward signal. Finally, we discuss how the calibration of parameters of epidemiological compartmental models is an emerging field that has the potential to improve the accuracy of disease modeling and public health decision-making. Further research is needed to validate the effectiveness and scalability of these approaches in different epidemiological contexts. All codes and resources are available on \url{https://github.com/Nikunj-Gupta/On-the-Calibration-of-Compartmental-Epidemiological-Models}. We hope this work can facilitate related research.
Planning Multiple Epidemic Interventions with Reinforcement Learning
Jan 30, 2023Combating an epidemic entails finding a plan that describes when and how to apply different interventions, such as mask-wearing mandates, vaccinations, school or workplace closures. An optimal plan will curb an epidemic with minimal loss of life, disease burden, and economic cost. Finding an optimal plan is an intractable computational problem in realistic settings. Policy-makers, however, would greatly benefit from tools that can efficiently search for plans that minimize disease and economic costs especially when considering multiple possible interventions over a continuous and complex action space given a continuous and equally complex state space. We formulate this problem as a Markov decision process. Our formulation is unique in its ability to represent multiple continuous interventions over any disease model defined by ordinary differential equations. We illustrate how to effectively apply state-of-the-art actor-critic reinforcement learning algorithms (PPO and SAC) to search for plans that minimize overall costs. We empirically evaluate the learning performance of these algorithms and compare their performance to hand-crafted baselines that mimic plans constructed by policy-makers. Our method outperforms baselines. Our work confirms the viability of a computational approach to support policy-makers
Forgetful Forests: high performance learning data structures for streaming data under concept drift
Dec 15, 2022Database research can help machine learning performance in many ways. One way is to design better data structures. This paper combines the use of incremental computation and sequential and probabilistic filtering to enable "forgetful" tree-based learning algorithms to cope with concept drift data (i.e., data whose function from input to classification changes over time). The forgetful algorithms described in this paper achieve high time performance while maintaining high quality predictions on streaming data. Specifically, the algorithms are up to 24 times faster than state-of-the-art incremental algorithms with at most a 2% loss of accuracy, or at least twice faster without any loss of accuracy. This makes such structures suitable for high volume streaming applications.
Classification Under Ambiguity: When Is Average-K Better Than Top-K?
Dec 16, 2021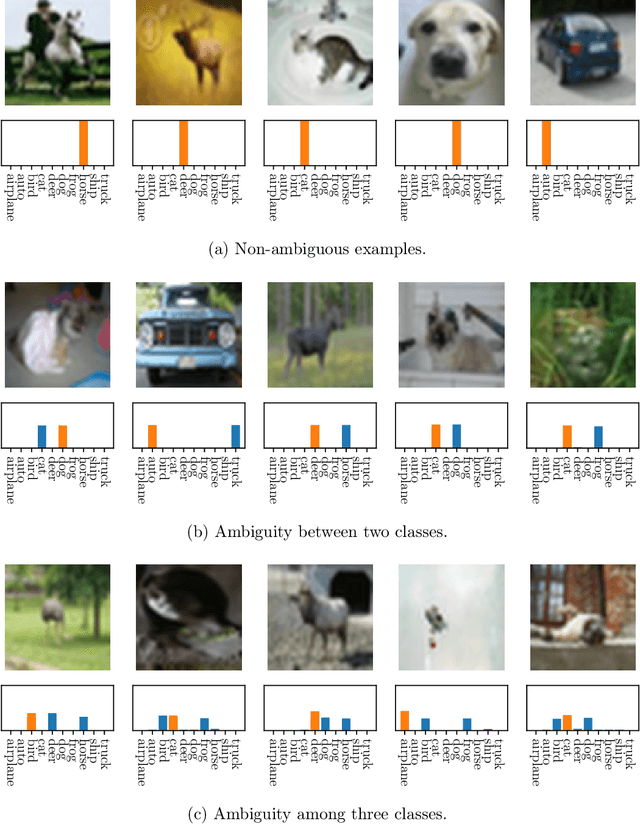

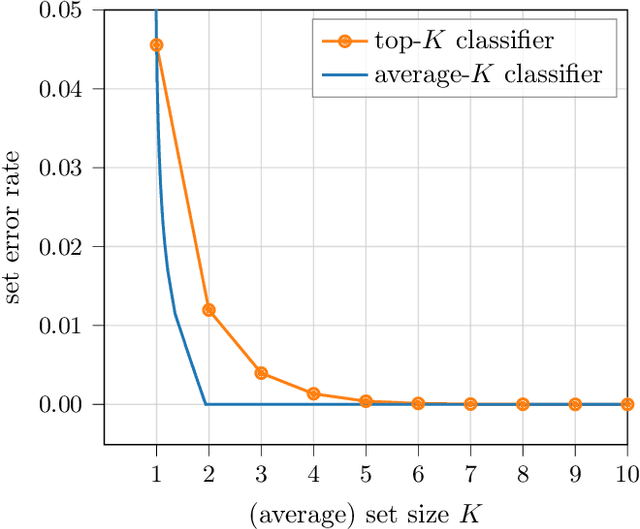
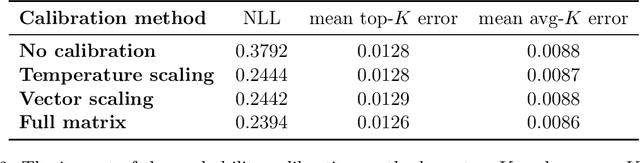
When many labels are possible, choosing a single one can lead to low precision. A common alternative, referred to as top-$K$ classification, is to choose some number $K$ (commonly around 5) and to return the $K$ labels with the highest scores. Unfortunately, for unambiguous cases, $K>1$ is too many and, for very ambiguous cases, $K \leq 5$ (for example) can be too small. An alternative sensible strategy is to use an adaptive approach in which the number of labels returned varies as a function of the computed ambiguity, but must average to some particular $K$ over all the samples. We denote this alternative average-$K$ classification. This paper formally characterizes the ambiguity profile when average-$K$ classification can achieve a lower error rate than a fixed top-$K$ classification. Moreover, it provides natural estimation procedures for both the fixed-size and the adaptive classifier and proves their consistency. Finally, it reports experiments on real-world image data sets revealing the benefit of average-$K$ classification over top-$K$ in practice. Overall, when the ambiguity is known precisely, average-$K$ is never worse than top-$K$, and, in our experiments, when it is estimated, this also holds.
Robotic Room Traversal using Optical Range Finding
Apr 17, 2020


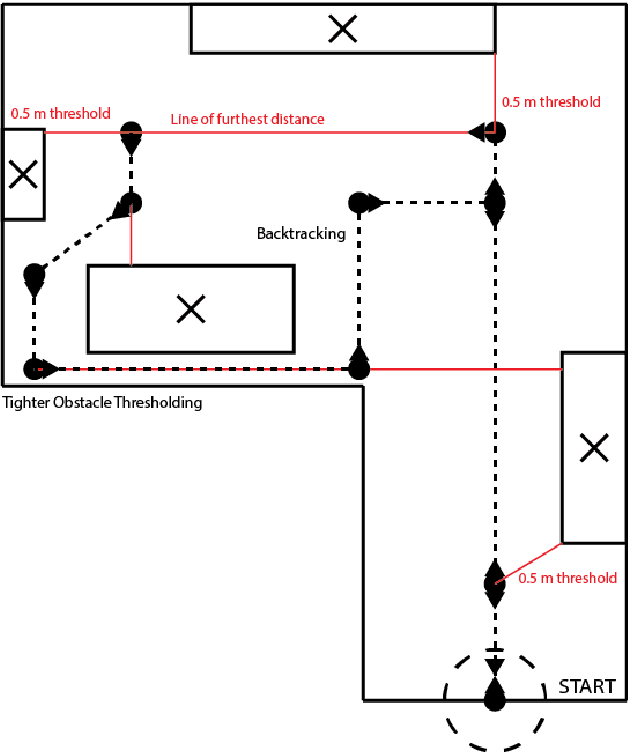
Consider the goal of visiting every part of a room that is not blocked by obstacles. Doing so efficiently requires both sensors and planning. Our findings suggest a method of inexpensive optical range finding for robotic room traversal. Our room traversal algorithm relies upon the approximate distance from the robot to the nearest obstacle in 360 degrees. We then choose the path with the furthest approximate distance. Since millimeter-precision is not required for our problem, we have opted to develop our own laser range finding solution, in lieu of using more common, but also expensive solutions like light detection and ranging (LIDAR). Rather, our solution uses a laser that casts a visible dot on the target and a common camera (an iPhone, for example). Based upon where in the camera frame the laser dot is detected, we may calculate an angle between our target and the laser aperture. Using this angle and the known distance between the camera eye and the laser aperture, we may solve all sides of a trigonometric model which provides the distance between the robot and the target.
Debugging Machine Learning Pipelines
Feb 11, 2020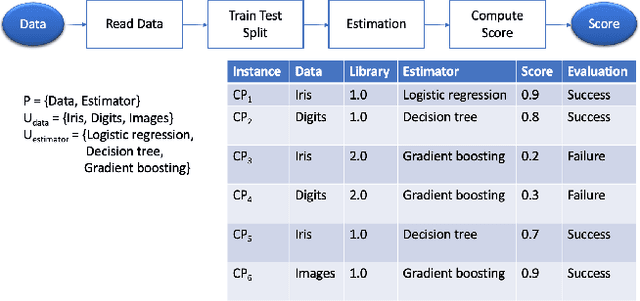
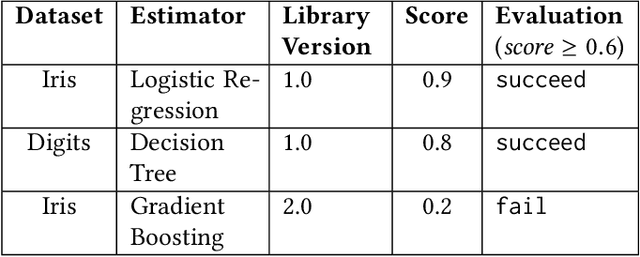
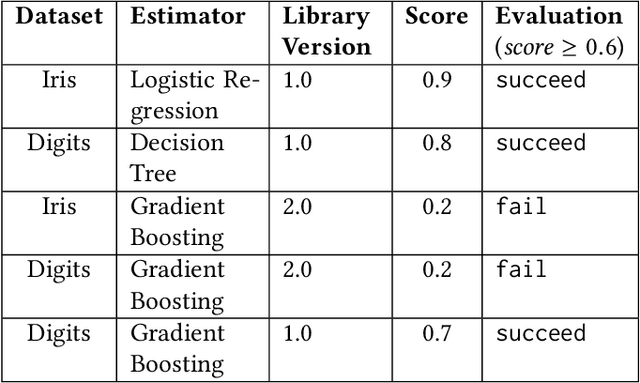
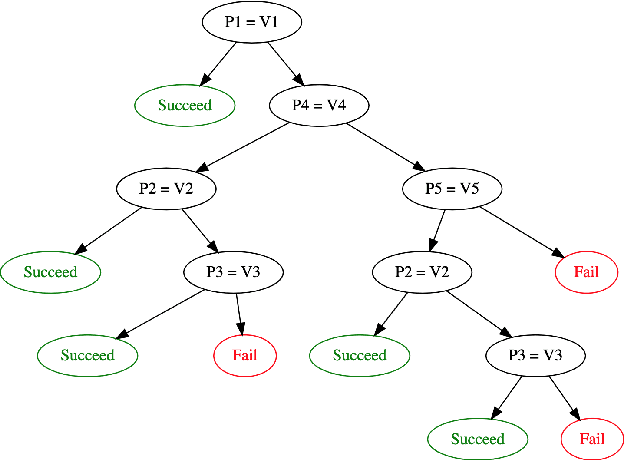
Machine learning tasks entail the use of complex computational pipelines to reach quantitative and qualitative conclusions. If some of the activities in a pipeline produce erroneous or uninformative outputs, the pipeline may fail or produce incorrect results. Inferring the root cause of failures and unexpected behavior is challenging, usually requiring much human thought, and is both time-consuming and error-prone. We propose a new approach that makes use of iteration and provenance to automatically infer the root causes and derive succinct explanations of failures. Through a detailed experimental evaluation, we assess the cost, precision, and recall of our approach compared to the state of the art. Our source code and experimental data will be available for reproducibility and enhancement.
* 10 pages