 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cost-Effective LLM-based Approach to Identify Wildlife Trafficking in Online Marketplaces
Apr 29, 2025Wildlife trafficking remains a critical global issue, significantly impacting biodiversity, ecological stability, and public health. Despite efforts to combat this illicit trade, the rise of e-commerce platforms has made it easier to sell wildlife products, putting new pressure on wild populations of endangered and threatened species. The use of these platforms also opens a new opportunity: as criminals sell wildlife products online, they leave digital traces of their activity that can provide insights into trafficking activities as well as how they can be disrupted. The challenge lies in finding these traces. Online marketplaces publish ads for a plethora of products, and identifying ads for wildlife-related products is like finding a needle in a haystack. Learning classifiers can automate ad identification, but creating them requires costly, time-consuming data labeling that hinders support for diverse ads and research questions. This paper addresses a critical challenge in the data science pipeline for wildlife trafficking analytics: generating quality labeled data for classifiers that select relevant data. While large language models (LLMs) can directly label advertisements, doing so at scale is prohibitively expensive. We propose a cost-effective strategy that leverages LLMs to generate pseudo labels for a small sample of the data and uses these labels to create specialized classification models. Our novel method automatically gathers diverse and representative samples to be labeled while minimizing the labeling costs. Our experimental evaluation shows that our classifiers achieve up to 95% F1 score, outperforming LLMs at a lower cost. We present real use cases that demonstrate the effectiveness of our approach in enabling analyses of different aspects of wildlife trafficking.
Interactive Data Harmonization with LLM Agents
Feb 10, 2025Data harmonization is an essential task that entails integrating datasets from diverse sources. Despite years of research in this area, it remains a time-consuming and challenging task due to schema mismatches, varying terminologies, and differences in data collection methodologies. This paper presents the case for agentic data harmonization as a means to both empower experts to harmonize their data and to streamline the process. We introduce Harmonia, a system that combines LLM-based reasoning, an interactive user interface, and a library of data harmonization primitives to automate the synthesis of data harmonization pipelines. We demonstrate Harmonia in a clinical data harmonization scenario, where it helps to interactively create reusable pipelines that map datasets to a standard format. Finally, we discuss challenges and open problems, and suggest research directions for advancing our vision.
Matrix Product Sketching via Coordinated Sampling
Jan 29, 2025



We revisit the well-studied problem of approximating a matrix product, $\mathbf{A}^T\mathbf{B}$, based on small space sketches $\mathcal{S}(\mathbf{A})$ and $\mathcal{S}(\mathbf{B})$ of $\mathbf{A} \in \R^{n \times d}$ and $\mathbf{B}\in \R^{n \times m}$. We are interested in the setting where the sketches must be computed independently of each other, except for the use of a shared random seed. We prove that, when $\mathbf{A}$ and $\mathbf{B}$ are sparse, methods based on \emph{coordinated random sampling} can outperform classical linear sketching approaches, like Johnson-Lindenstrauss Projection or CountSketch. For example, to obtain Frobenius norm error $\epsilon\|\mathbf{A}\|_F\|\mathbf{B}\|_F$, coordinated sampling requires sketches of size $O(s/\epsilon^2)$ when $\mathbf{A}$ and $\mathbf{B}$ have at most $s \leq d,m$ non-zeros per row. In contrast, linear sketching leads to sketches of size $O(d/\epsilon^2)$ and $O(m/\epsilon^2)$ for $\mathbf{A}$ and $\mathbf{B}$. We empirically evaluate our approach on two applications: 1) distributed linear regression in databases, a problem motivated by tasks like dataset discovery and augmentation, and 2) approximating attention matrices in transformer-based language models. In both cases, our sampling algorithms yield an order of magnitude improvement over linear sketching.
Magneto: Combining Small and Large Language Models for Schema Matching
Dec 11, 2024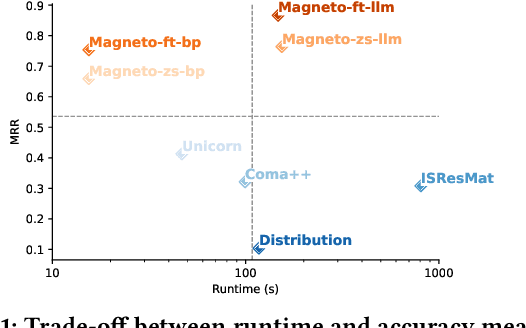
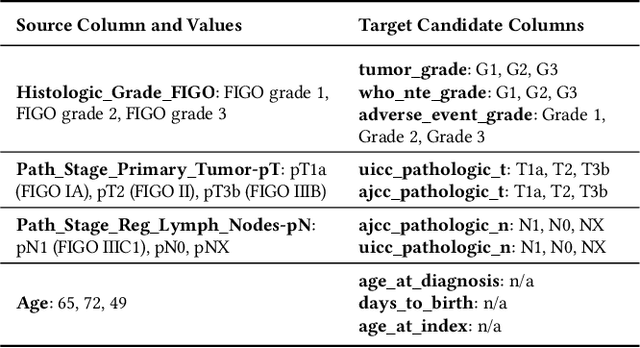


Recent advances in language models opened new opportunities to address complex schema matching tasks. Schema matching approaches have been proposed that demonstrate the usefulness of language models, but they have also uncovered important limitations: Small language models (SLMs) require training data (which can be both expensive and challenging to obtain), and large language models (LLMs) often incur high computational costs and must deal with constraints imposed by context windows. We present Magneto, a cost-effective and accurate solution for schema matching that combines the advantages of SLMs and LLMs to address their limitations. By structuring the schema matching pipeline in two phases, retrieval and reranking, Magneto can use computationally efficient SLM-based strategies to derive candidate matches which can then be reranked by LLMs, thus making it possible to reduce runtime without compromising matching accuracy. We propose a self-supervised approach to fine-tune SLMs which uses LLMs to generate syntactically diverse training data, and prompting strategies that are effective for reranking. We also introduce a new benchmark, developed in collaboration with domain experts, which includes real biomedical datasets and presents new challenges to schema matching methods. Through a detailed experimental evaluation, using both our new and existing benchmarks, we show that Magneto is scalable and attains high accuracy for datasets from different domains.
Kernel Banzhaf: A Fast and Robust Estimator for Banzhaf Values
Oct 10, 2024



Banzhaf values offer a simple and interpretable alternative to the widely-used Shapley values. We introduce Kernel Banzhaf, a novel algorithm inspired by KernelSHAP, that leverages an elegant connection between Banzhaf values and linear regression. Through extensive experiments on feature attribution tasks, we demonstrate that Kernel Banzhaf substantially outperforms other algorithms for estimating Banzhaf values in both sample efficiency and robustness to noise. Furthermore, we prove theoretical guarantees on the algorithm's performance, establishing Kernel Banzhaf as a valuable tool for interpretable machine learning.
A Flexible and Scalable Approach for Collecting Wildlife Advertisements on the Web
Jul 26, 2024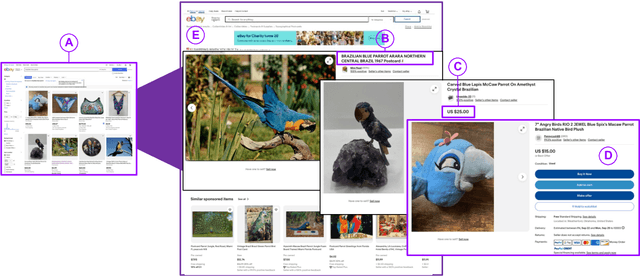
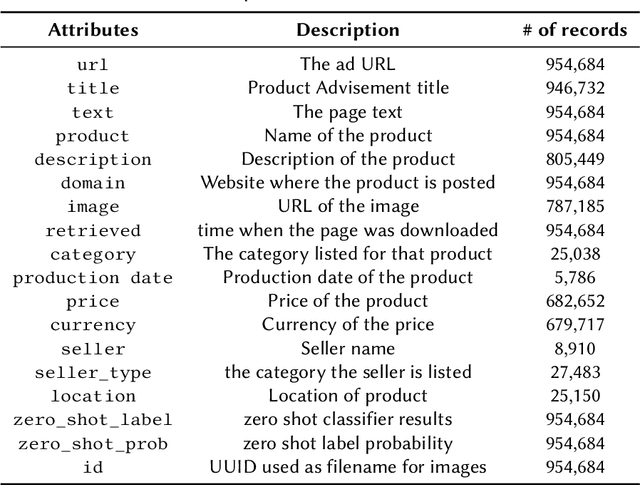

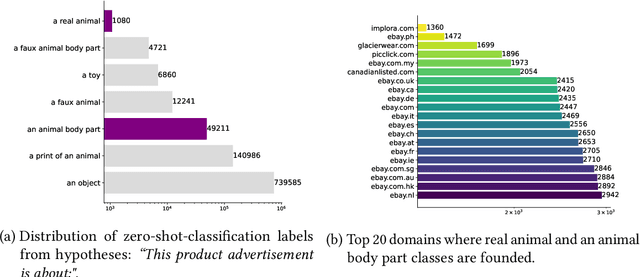
Wildlife traffickers are increasingly carrying out their activities in cyberspace. As they advertise and sell wildlife products in online marketplaces, they leave digital traces of their activity. This creates a new opportunity: by analyzing these traces, we can obtain insights into how trafficking networks work as well as how they can be disrupted. However, collecting such information is difficult. Online marketplaces sell a very large number of products and identifying ads that actually involve wildlife is a complex task that is hard to automate. Furthermore, given that the volume of data is staggering, we need scalable mechanisms to acquire, filter, and store the ads, as well as to make them available for analysis. In this paper, we present a new approach to collect wildlife trafficking data at scale. We propose a data collection pipeline that combines scoped crawlers for data discovery and acquisition with foundational models and machine learning classifiers to identify relevant ads. We describe a dataset we created using this pipeline which is, to the best of our knowledge, the largest of its kind: it contains almost a million ads obtained from 41 marketplaces, covering 235 species and 20 languages. The source code is publicly available at \url{https://github.com/VIDA-NYU/wildlife_pipeline}.
ArcheType: A Novel Framework for Open-Source Column Type Annotation using Large Language Models
Nov 06, 2023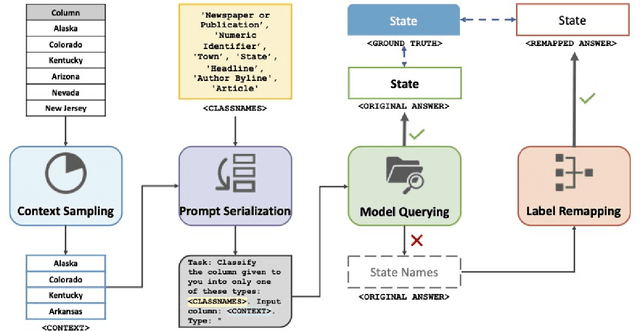



Existing deep-learning approaches to semantic column type annotation (CTA) have important shortcomings: they rely on semantic types which are fixed at training time; require a large number of training samples per type and incur large run-time inference costs; and their performance can degrade when evaluated on novel datasets, even when types remain constant. Large language models have exhibited strong zero-shot classification performance on a wide range of tasks and in this paper we explore their use for CTA. We introduce ArcheType, a simple, practical method for context sampling, prompt serialization, model querying, and label remapping, which enables large language models to solve CTA problems in a fully zero-shot manner. We ablate each component of our method separately, and establish that improvements to context sampling and label remapping provide the most consistent gains. ArcheType establishes a new state-of-the-art performance on zero-shot CTA benchmarks (including three new domain-specific benchmarks which we release along with this paper), and when used in conjunction with classical CTA techniques, it outperforms a SOTA DoDuo model on the fine-tuned SOTAB benchmark. Our code is available at https://github.com/penfever/ArcheType.
eTOP: Early Termination of Pipelines for Faster Training of AutoML Systems
Apr 17, 2023



Recent advancements in software and hardware technologies have enabled the use of AI/ML models in everyday applications has significantly improved the quality of service rendered. However, for a given application, finding the right AI/ML model is a complex and costly process, that involves the generation, training, and evaluation of multiple interlinked steps (called pipelines), such as data pre-processing, feature engineering, selection, and model tuning. These pipelines are complex (in structure) and costly (both in compute resource and time) to execute end-to-end, with a hyper-parameter associated with each step. AutoML systems automate the search of these hyper-parameters but are slow, as they rely on optimizing the pipeline's end output. We propose the eTOP Framework which works on top of any AutoML system and decides whether or not to execute the pipeline to the end or terminate at an intermediate step. Experimental evaluation on 26 benchmark datasets and integration of eTOPwith MLBox4 reduces the training time of the AutoML system upto 40x than baseline MLBox.
AlphaD3M: Machine Learning Pipeline Synthesis
Nov 03, 2021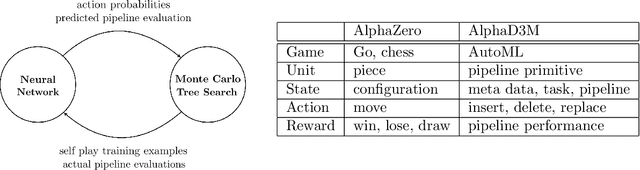
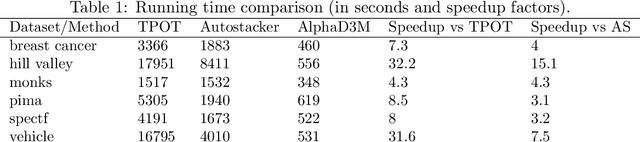
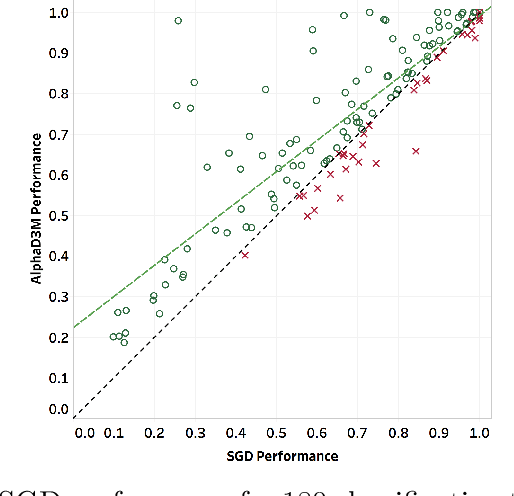
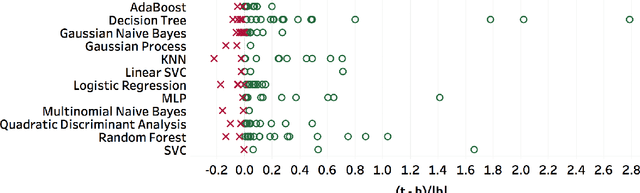
We introduce AlphaD3M, an automatic machine learning (AutoML) system based on meta reinforcement learning using sequence models with self play. AlphaD3M is based on edit operations performed over machine learning pipeline primitives providing explainability. We compare AlphaD3M with state-of-the-art AutoML systems: Autosklearn, Autostacker, and TPOT, on OpenML datasets. AlphaD3M achieves competitive performance while being an order of magnitude faster, reducing computation time from hours to minutes, and is explainable by design.
Correlation Sketches for Approximate Join-Correlation Queries
Apr 07, 2021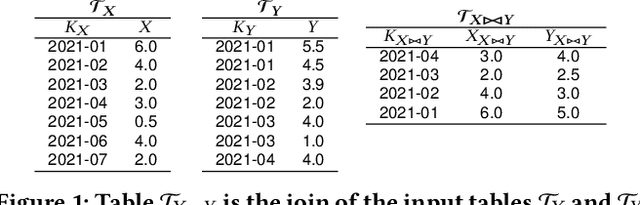


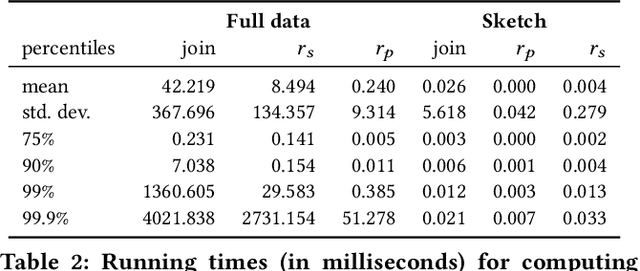
The increasing availability of structured datasets, from Web tables and open-data portals to enterprise data, opens up opportunities~to enrich analytics and improve machine learning models through relational data augmentation. In this paper, we introduce a new class of data augmentation queries: join-correlation queries. Given a column $Q$ and a join column $K_Q$ from a query table $\mathcal{T}_Q$, retrieve tables $\mathcal{T}_X$ in a dataset collection such that $\mathcal{T}_X$ is joinable with $\mathcal{T}_Q$ on $K_Q$ and there is a column $C \in \mathcal{T}_X$ such that $Q$ is correlated with $C$. A na\"ive approach to evaluate these queries, which first finds joinable tables and then explicitly joins and computes correlations between $Q$ and all columns of the discovered tables, is prohibitively expensive. To efficiently support correlated column discovery, we 1) propose a sketching method that enables the construction of an index for a large number of tables and that provides accurate estimates for join-correlation queries, and 2) explore different scoring strategies that effectively rank the query results based on how well the columns are correlated with the query. We carry out a detailed experimental evaluation, using both synthetic and real data, which shows that our sketches attain high accuracy and the scoring strategies lead to high-quality rankings.