 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Expert Specialization in Mixture of Experts
Feb 28, 2023



Mixture of experts (MoE), introduced over 20 years ago, is the simplest gated modular neural network architecture. There is renewed interest in MoE because the conditional computation allows only parts of the network to be used during each inference, as was recently demonstrated in large scale natural language processing models. MoE is also of potential interest for continual learning, as experts may be reused for new tasks, and new experts introduced. The gate in the MoE architecture learns task decompositions and individual experts learn simpler functions appropriate to the gate's decomposition. In this paper: (1) we show that the original MoE architecture and its training method do not guarantee intuitive task decompositions and good expert utilization, indeed they can fail spectacularly even for simple data such as MNIST and FashionMNIST; (2) we introduce a novel gating architecture, similar to attention, that improves performance and results in a lower entropy task decomposition; and (3) we introduce a novel data-driven regularization that improves expert specialization. We empirically validate our methods on MNIST, FashionMNIST and CIFAR-100 datasets.
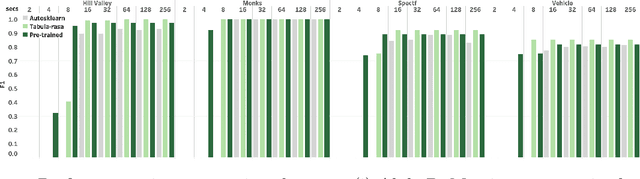
AlphaD3M: Machine Learning Pipeline Synthesis
Nov 03, 2021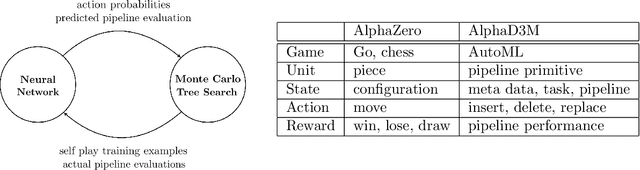
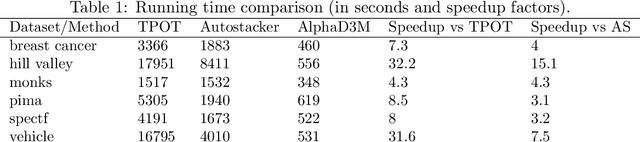
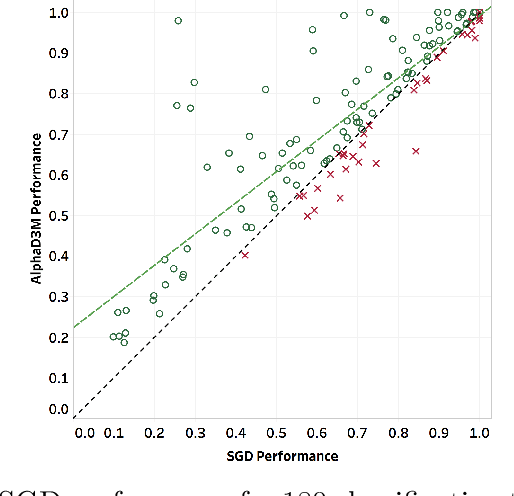
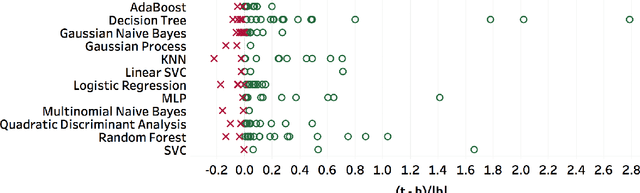
We introduce AlphaD3M, an automatic machine learning (AutoML) system based on meta reinforcement learning using sequence models with self play. AlphaD3M is based on edit operations performed over machine learning pipeline primitives providing explainability. We compare AlphaD3M with state-of-the-art AutoML systems: Autosklearn, Autostacker, and TPOT, on OpenML datasets. AlphaD3M achieves competitive performance while being an order of magnitude faster, reducing computation time from hours to minutes, and is explainable by design.
Automatic Machine Learning by Pipeline Synthesis using Model-Based Reinforcement Learning and a Grammar
May 24, 2019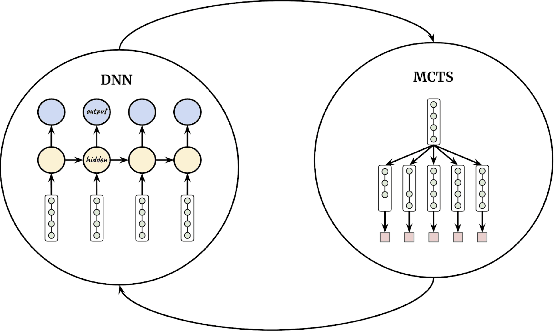

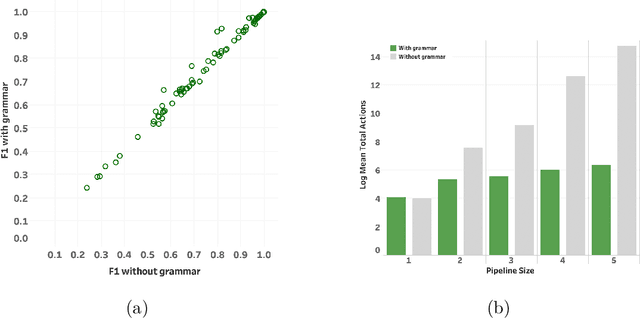
Automatic machine learning is an important problem in the forefront of machine learning. The strongest AutoML systems are based on neural networks, evolutionary algorithms, and Bayesian optimization. Recently AlphaD3M reached state-of-the-art results with an order of magnitude speedup using reinforcement learning with self-play. In this work we extend AlphaD3M by using a pipeline grammar and a pre-trained model which generalizes from many different datasets and similar tasks. Our results demonstrate improved performance compared with our earlier work and existing methods on AutoML benchmark datasets for classification and regression tasks. In the spirit of reproducible research we make our data, models, and code publicly available.
Bayesian Optimal Active Search and Surveying
Jun 27, 2012
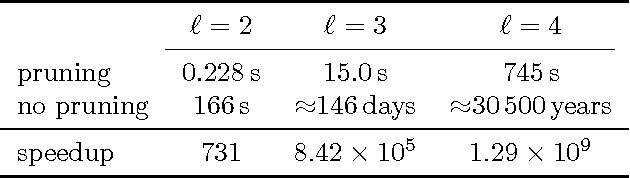
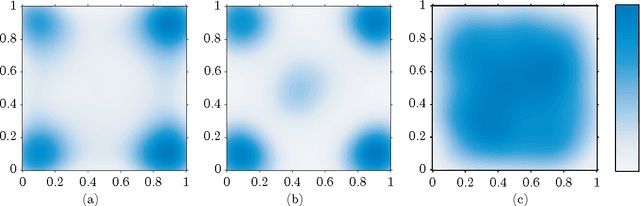
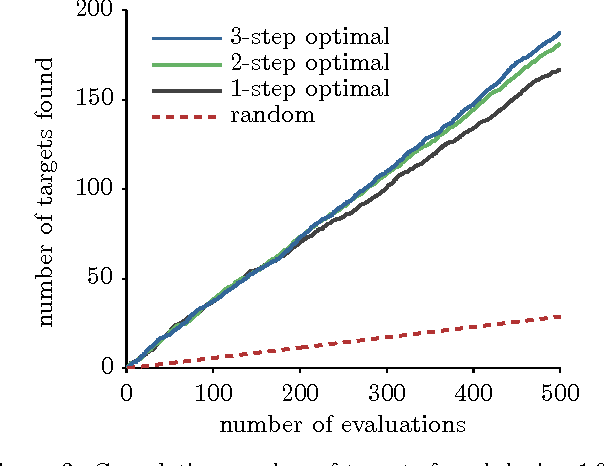
We consider two active binary-classification problems with atypical objectives. In the first, active search, our goal is to actively uncover as many members of a given class as possible. In the second, active surveying, our goal is to actively query points to ultimately predict the proportion of a given class. Numerous real-world problems can be framed in these terms, and in either case typical model-based concerns such as generalization error are only of secondary importance. We approach these problems via Bayesian decision theory; after choosing natural utility functions, we derive the optimal policies. We provide three contributions. In addition to introducing the active surveying problem, we extend previous work on active search in two ways. First, we prove a novel theoretical result, that less-myopic approximations to the optimal policy can outperform more-myopic approximations by any arbitrary degree. We then derive bounds that for certain models allow us to reduce (in practice dramatically) the exponential search space required by a naive implementation of the optimal policy, enabling further lookahead while still ensuring that optimal decisions are always made.