 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dynamic, Ordinal Gaussian Process Item Response Theoretic Model
Apr 03, 2025Social scientists are often interested in using ordinal indicators to estimate latent traits that change over time. Frequently, this is done with item response theoretic (IRT) models that describe the relationship between those latent traits and observed indicators. We combine recent advances in Bayesian nonparametric IRT, which makes minimal assumptions on shapes of item response functions, and Gaussian process time series methods to capture dynamic structures in latent traits from longitudinal observations. We propose a generalized dynamic Gaussian process item response theory (GD-GPIRT) as well as a Markov chain Monte Carlo sampling algorithm for estimation of both latent traits and response functions. We evaluate GD-GPIRT in simulation studies against baselines in dynamic IRT, and apply it to various substantive studies, including assessing public opinions on economy environment and congressional ideology related to abortion debate.
Idiographic Personality Gaussian Process for Psychological Assessment
Jul 06, 2024We develop a novel measurement framework based on a Gaussian process coregionalization model to address a long-lasting debate in psychometrics: whether psychological features like personality share a common structure across the population, vary uniquely for individuals, or some combination. We propose the idiographic personality Gaussian process (IPGP) framework, an intermediate model that accommodates both shared trait structure across a population and "idiographic" deviations for individuals. IPGP leverages the Gaussian process coregionalization model to handle the grouped nature of battery responses, but adjusted to non-Gaussian ordinal data. We further exploit stochastic variational inference for efficient latent factor estimation required for idiographic modeling at scale. Using synthetic and real data, we show that IPGP improves both prediction of actual responses and estimation of individualized factor structures relative to existing benchmarks. In a third study, we show that IPGP also identifies unique clusters of personality taxonomies in real-world data, displaying great potential in advancing individualized approaches to psychological diagnosis and treatment.
Amortized nonmyopic active search via deep imitation learning
May 23, 2024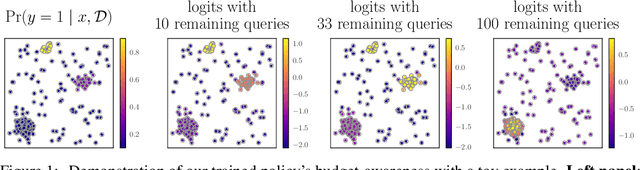

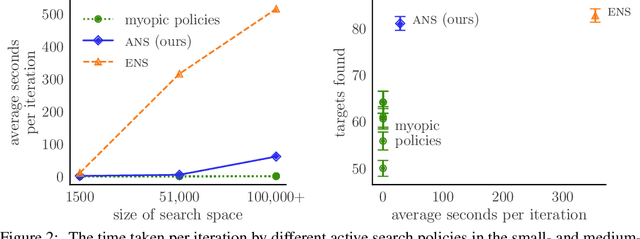

Active search formalizes a specialized active learning setting where the goal is to collect members of a rare, valuable class. The state-of-the-art algorithm approximates the optimal Bayesian policy in a budget-aware manner, and has been shown to achieve impressive empirical performance in previous work. However, even this approximate policy has a superlinear computational complexity with respect to the size of the search problem, rendering its application impractical in large spaces or in real-time systems where decisions must be made quickly. We study the amortization of this policy by training a neural network to learn to search. To circumvent the difficulty of learning from scratch, we appeal to imitation learning techniques to mimic the behavior of the expert, expensive-to-compute policy. Our policy network, trained on synthetic data, learns a beneficial search strategy that yields nonmyopic decisions carefully balancing exploration and exploitation. Extensive experiments demonstrate our policy achieves competitive performance at real-world tasks that closely approximates the expert's at a fraction of the cost, while outperforming cheaper baselines.
The Behavior and Convergence of Local Bayesian Optimization
May 24, 2023



A recent development in Bayesian optimization is the use of local optimization strategies, which can deliver strong empirical performance on high-dimensional problems compared to traditional global strategies. The "folk wisdom" in the literature is that the focus on local optimization sidesteps the curse of dimensionality; however, little is known concretely about the expected behavior or convergence of Bayesian local optimization routines. We first study the behavior of the local approach, and find that the statistics of individual local solutions of Gaussian process sample paths are surprisingly good compared to what we would expect to recover from global methods. We then present the first rigorous analysis of such a Bayesian local optimization algorithm recently proposed by M\"uller et al. (2021), and derive convergence rates in both the noisy and noiseless settings.
A Visual Active Search Framework for Geospatial Exploration
Nov 28, 2022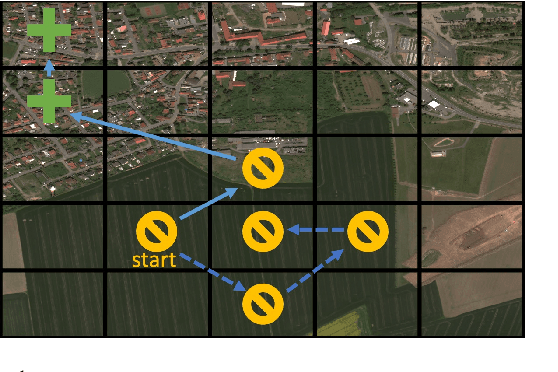
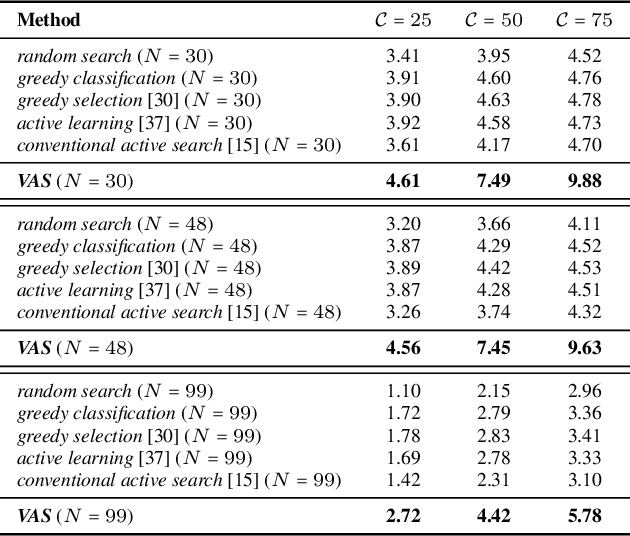
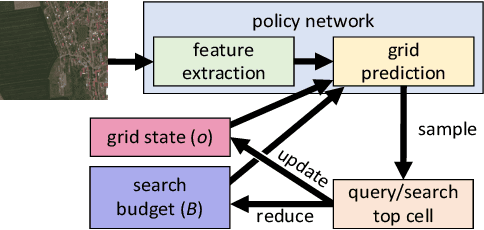
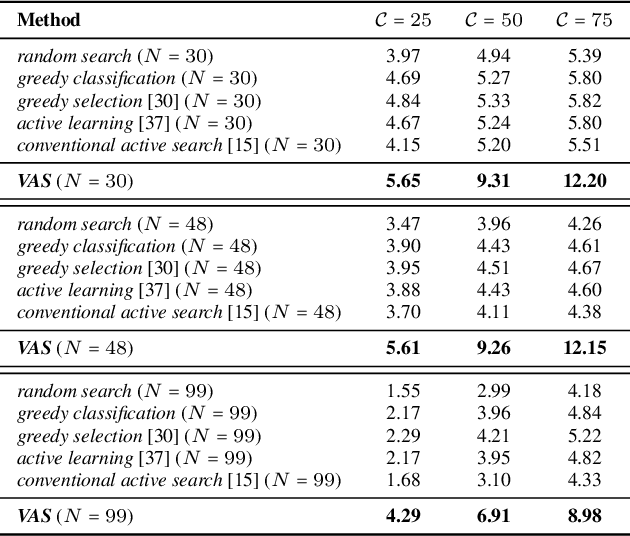
Many problems can be viewed as forms of geospatial search aided by aerial imagery, with examples ranging from detecting poaching activity to human trafficking. We model this class of problems in a visual active search (VAS) framework, which takes as input an image of a broad area, and aims to identify as many examples of a target object as possible. It does this through a limited sequence of queries, each of which verifies whether an example is present in a given region. We propose a reinforcement learning approach for VAS that leverages a collection of fully annotated search tasks as training data to learn a search policy, and combines features of the input image with a natural representation of active search state. Additionally, we propose domain adaptation techniques to improve the policy at decision time when training data is not fully reflective of the test-time distribution of VAS tasks. Through extensive experiments on several satellite imagery datasets, we show that the proposed approach significantly outperforms several strong baselines. Code and data will be made public.
A Unified Comparison of User Modeling Techniques for Predicting Data Interaction and Detecting Exploration Bias
Aug 09, 2022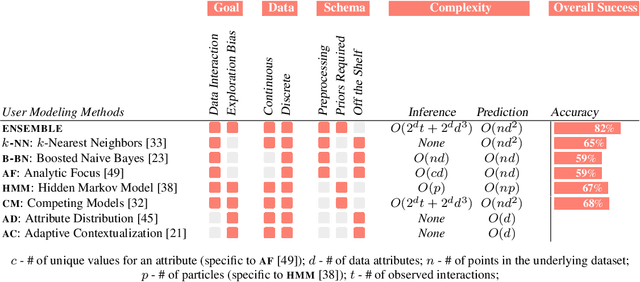
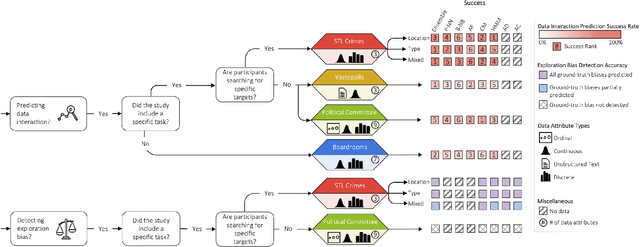
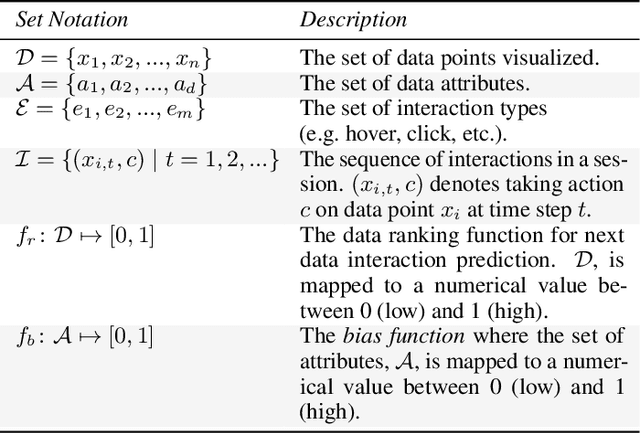
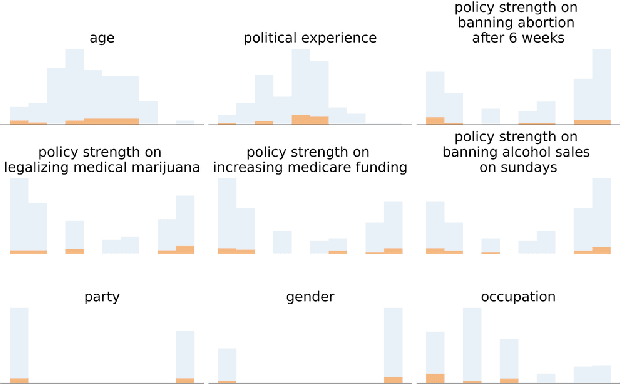
The visual analytics community has proposed several user modeling algorithms to capture and analyze users' interaction behavior in order to assist users in data exploration and insight generation. For example, some can detect exploration biases while others can predict data points that the user will interact with before that interaction occurs. Researchers believe this collection of algorithms can help create more intelligent visual analytics tools. However, the community lacks a rigorous evaluation and comparison of these existing techniques. As a result, there is limited guidance on which method to use and when. Our paper seeks to fill in this missing gap by comparing and ranking eight user modeling algorithms based on their performance on a diverse set of four user study datasets. We analyze exploration bias detection, data interaction prediction, and algorithmic complexity, among other measures. Based on our findings, we highlight open challenges and new directions for analyzing user interactions and visualization provenance.
Nonmyopic Multiclass Active Search for Diverse Discovery
Feb 08, 2022
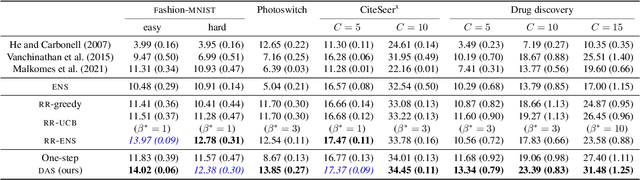
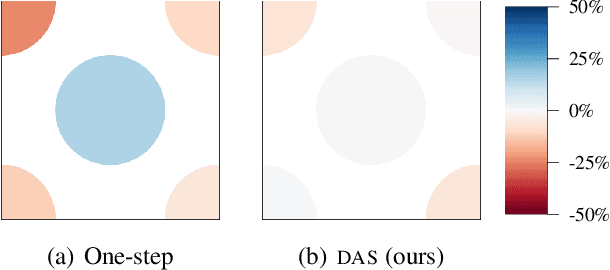

Active search is a setting in adaptive experimental design where we aim to uncover members of rare, valuable class(es) subject to a budget constraint. An important consideration in this problem is diversity among the discovered targets -- in many applications, diverse discoveries offer more insight and may be preferable in downstream tasks. However, most existing active search policies either assume that all targets belong to a common positive class or encourage diversity via simple heuristics. We present a novel formulation of active search with multiple target classes, characterized by a utility function that naturally induces a preference for label diversity among discoveries via a diminishing returns mechanism. We then study this problem under the Bayesian lens and prove a hardness result for approximating the optimal policy. Finally, we propose an efficient, nonmyopic approximation to the optimal policy and demonstrate its superior empirical performance across a wide variety of experimental settings, including drug discovery.
Nonmyopic Multifidelity Active Search
Jul 07, 2021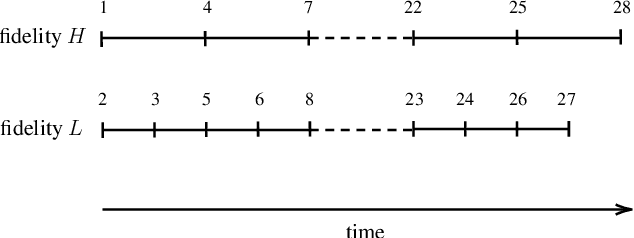

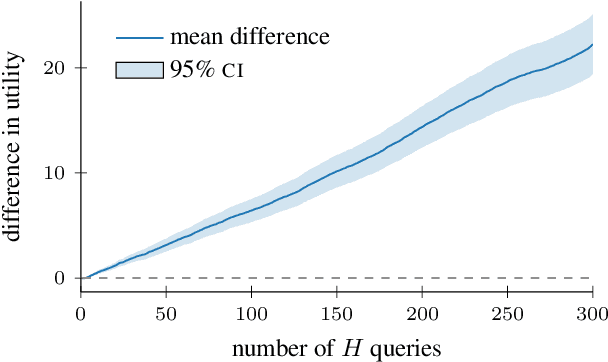
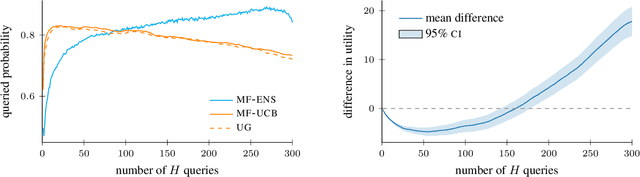
Active search is a learning paradigm where we seek to identify as many members of a rare, valuable class as possible given a labeling budget. Previous work on active search has assumed access to a faithful (and expensive) oracle reporting experimental results. However, some settings offer access to cheaper surrogates such as computational simulation that may aid in the search. We propose a model of multifidelity active search, as well as a novel, computationally efficient policy for this setting that is motivated by state-of-the-art classical policies. Our policy is nonmyopic and budget aware, allowing for a dynamic tradeoff between exploration and exploitation. We evaluate the performance of our solution on real-world datasets and demonstrate significantly better performance than natural benchmarks.
Efficient Nonmyopic Bayesian Optimization via One-Shot Multi-Step Trees
Jun 29, 2020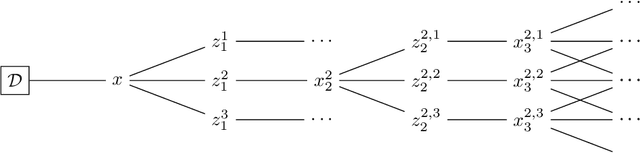

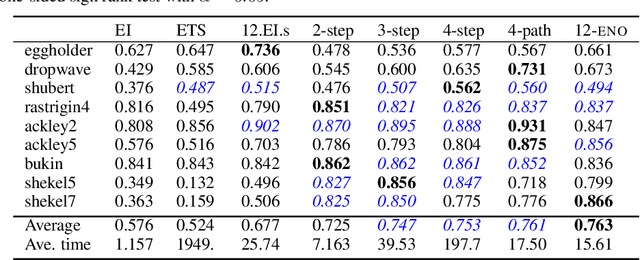
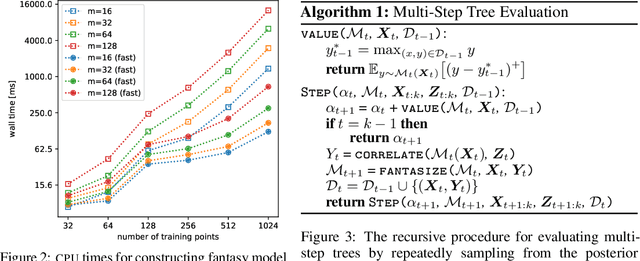
Bayesian optimization is a sequential decision making framework for optimizing expensive-to-evaluate black-box functions. Computing a full lookahead policy amounts to solving a highly intractable stochastic dynamic program. Myopic approaches, such as expected improvement, are often adopted in practice, but they ignore the long-term impact of the immediate decision. Existing nonmyopic approaches are mostly heuristic and/or computationally expensive. In this paper, we provide the first efficient implementation of general multi-step lookahead Bayesian optimization, formulated as a sequence of nested optimization problems within a multi-step scenario tree. Instead of solving these problems in a nested way, we equivalently optimize all decision variables in the full tree jointly, in a ``one-shot'' fashion. Combining this with an efficient method for implementing multi-step Gaussian process ``fantasization,'' we demonstrate that multi-step expected improvement is computationally tractable and exhibits performance superior to existing methods on a wide range of benchmarks.
GPIRT: A Gaussian Process Model for Item Response Theory
Jun 17, 2020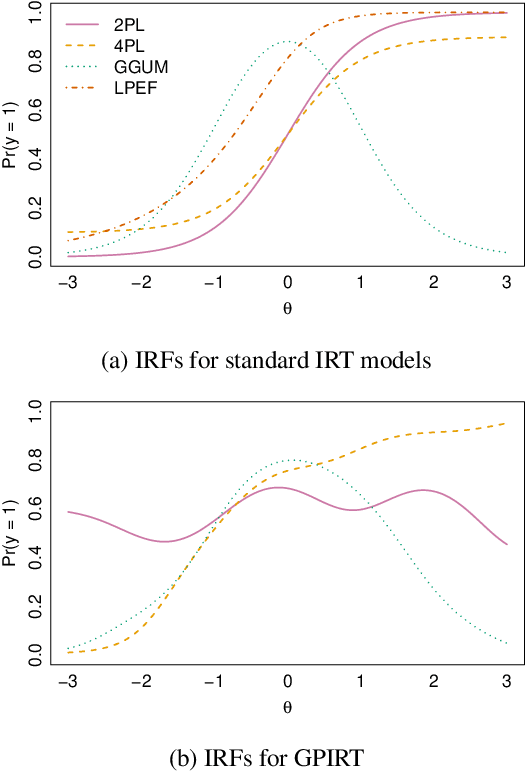



The goal of item response theoretic (IRT) models is to provide estimates of latent traits from binary observed indicators and at the same time to learn the item response functions (IRFs) that map from latent trait to observed response. However, in many cases observed behavior can deviate significantly from the parametric assumptions of traditional IRT models. Nonparametric IRT models overcome these challenges by relaxing assumptions about the form of the IRFs, but standard tools are unable to simultaneously estimate flexible IRFs and recover ability estimates for respondents. We propose a Bayesian nonparametric model that solves this problem by placing Gaussian process priors on the latent functions defining the IRFs. This allows us to simultaneously relax assumptions about the shape of the IRFs while preserving the ability to estimate latent traits. This in turn allows us to easily extend the model to further tasks such as active learning. GPIRT therefore provides a simple and intuitive solution to several longstanding problems in the IRT literature.