 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms for Adaptive Experiments that Trade-off Statistical Analysis with Reward: Combining Uniform Random Assignment and Reward Maximization
Dec 21, 2021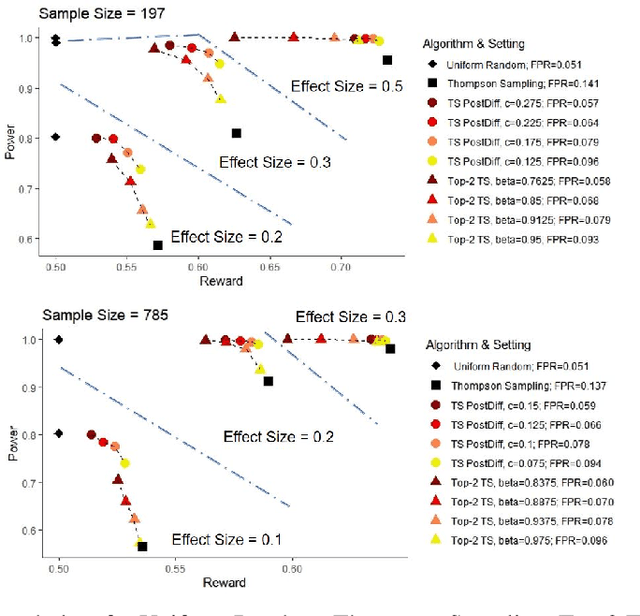
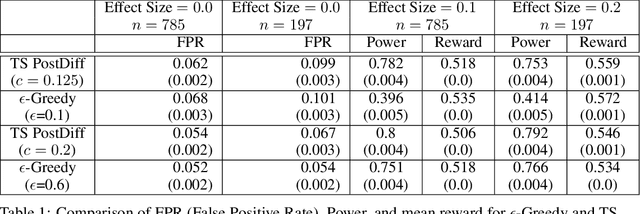
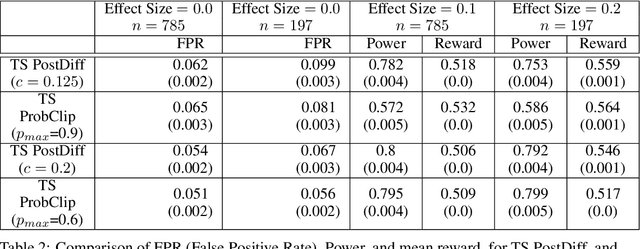
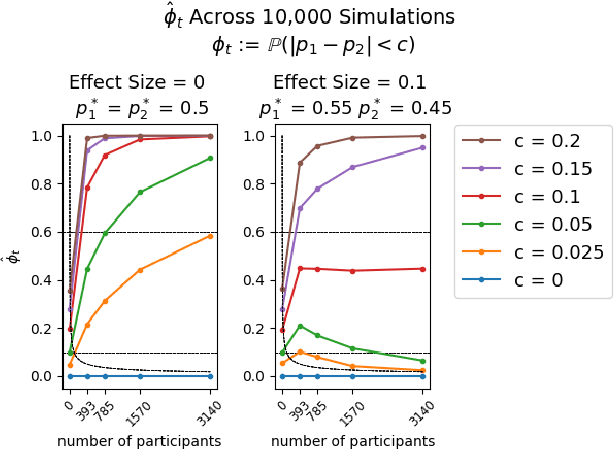
Multi-armed bandit algorithms like Thompson Sampling can be used to conduct adaptive experiments, in which maximizing reward means that data is used to progressively assign more participants to more effective arms. Such assignment strategies increase the risk of statistical hypothesis tests identifying a difference between arms when there is not one, and failing to conclude there is a difference in arms when there truly is one. We present simulations for 2-arm experiments that explore two algorithms that combine the benefits of uniform randomization for statistical analysis, with the benefits of reward maximization achieved by Thompson Sampling (TS). First, Top-Two Thompson Sampling adds a fixed amount of uniform random allocation (UR) spread evenly over time. Second, a novel heuristic algorithm, called TS PostDiff (Posterior Probability of Difference). TS PostDiff takes a Bayesian approach to mixing TS and UR: the probability a participant is assigned using UR allocation is the posterior probability that the difference between two arms is `small' (below a certain threshold), allowing for more UR exploration when there is little or no reward to be gained. We find that TS PostDiff method performs well across multiple effect sizes, and thus does not require tuning based on a guess for the true effect size.
Nonmyopic Multifidelity Active Search
Jul 07, 2021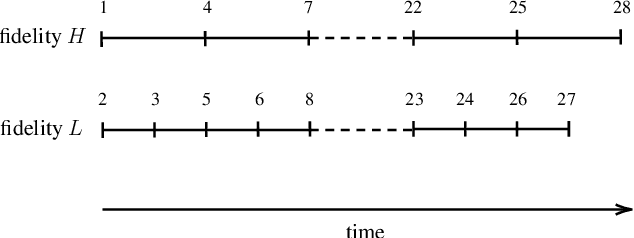

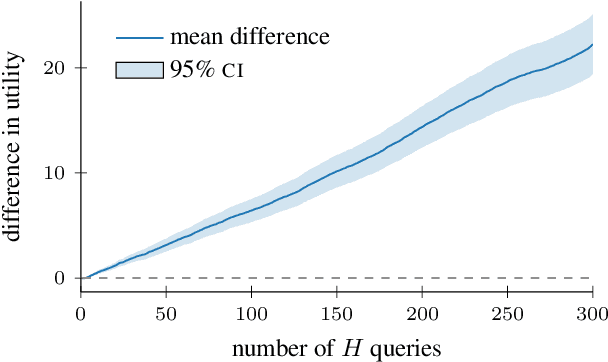
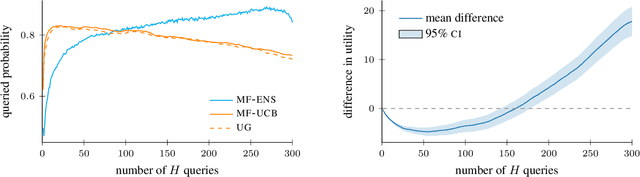
Active search is a learning paradigm where we seek to identify as many members of a rare, valuable class as possible given a labeling budget. Previous work on active search has assumed access to a faithful (and expensive) oracle reporting experimental results. However, some settings offer access to cheaper surrogates such as computational simulation that may aid in the search. We propose a model of multifidelity active search, as well as a novel, computationally efficient policy for this setting that is motivated by state-of-the-art classical policies. Our policy is nonmyopic and budget aware, allowing for a dynamic tradeoff between exploration and exploitation. We evaluate the performance of our solution on real-world datasets and demonstrate significantly better performance than natural benchmarks.