 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Bandits: Bringing statistical validity and reward efficiency to the small-gap regime
Dec 10, 2025We introduce Conformal Bandits, a novel framework integrating Conformal Prediction (CP) into bandit problems, a classic paradigm for sequential decision-making under uncertainty. Traditional regret-minimisation bandit strategies like Thompson Sampling and Upper Confidence Bound (UCB) typically rely on distributional assumptions or asymptotic guarantees; further, they remain largely focused on regret, neglecting their statistical properties. We address this gap. Through the adoption of CP, we bridge the regret-minimising potential of a decision-making bandit policy with statistical guarantees in the form of finite-time prediction coverage. We demonstrate the potential of it Conformal Bandits through simulation studies and an application to portfolio allocation, a typical small-gap regime, where differences in arm rewards are far too small for classical policies to achieve optimal regret bounds in finite sample. Motivated by this, we showcase our framework's practical advantage in terms of regret in small-gap settings, as well as its added value in achieving nominal coverage guarantees where classical UCB policies fail. Focusing on our application of interest, we further illustrate how integrating hidden Markov models to capture the regime-switching behaviour of financial markets, enhances the exploration-exploitation trade-off, and translates into higher risk-adjusted regret efficiency returns, while preserving coverage guarantees.
Artificial Intelligence-based Decision Support Systems for Precision and Digital Health
Jul 22, 2024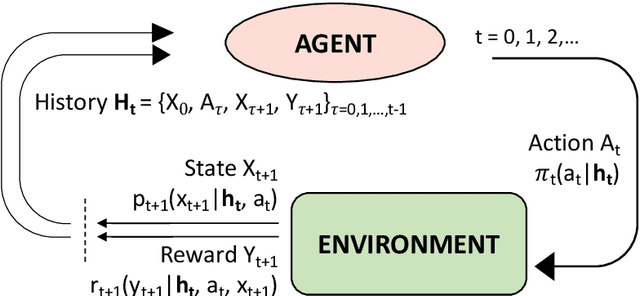
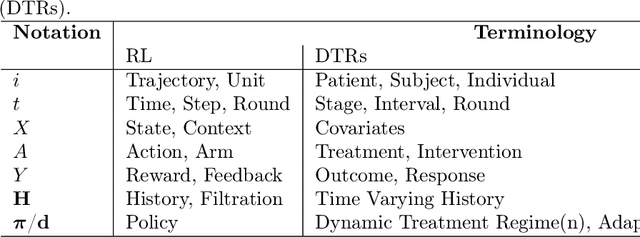
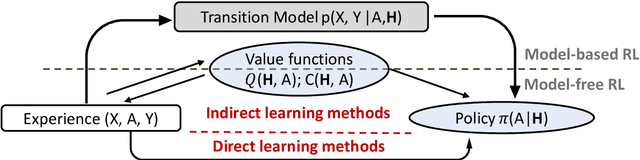
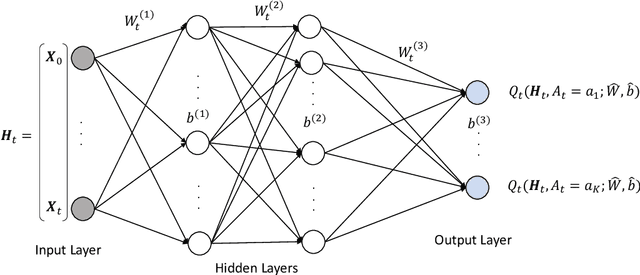
Precision health, increasingly supported by digital technologies, is a domain of research that broadens the paradigm of precision medicine, advancing everyday healthcare. This vision goes hand in hand with the groundbreaking advent of artificial intelligence (AI), which is reshaping the way we diagnose, treat, and monitor both clinical subjects and the general population. AI tools powered by machine learning have shown considerable improvements in a variety of healthcare domains. In particular, reinforcement learning (RL) holds great promise for sequential and dynamic problems such as dynamic treatment regimes and just-in-time adaptive interventions in digital health. In this work, we discuss the opportunity offered by AI, more specifically RL, to current trends in healthcare, providing a methodological survey of RL methods in the context of precision and digital health. Focusing on the area of adaptive interventions, we expand the methodological survey with illustrative case studies that used RL in real practice. This invited article has undergone anonymous review and is intended as a book chapter for the volume "Frontiers of Statistics and Data Science" edited by Subhashis Ghoshal and Anindya Roy for the International Indian Statistical Association Series on Statistics and Data Science, published by Springer. It covers the material from a short course titled "Artificial Intelligence in Precision and Digital Health" taught by the author Bibhas Chakraborty at the IISA 2022 Conference, December 26-30 2022, at the Indian Institute of Science, Bengaluru.
Thompson sampling for zero-inflated count outcomes with an application to the Drink Less mobile health study
Nov 24, 2023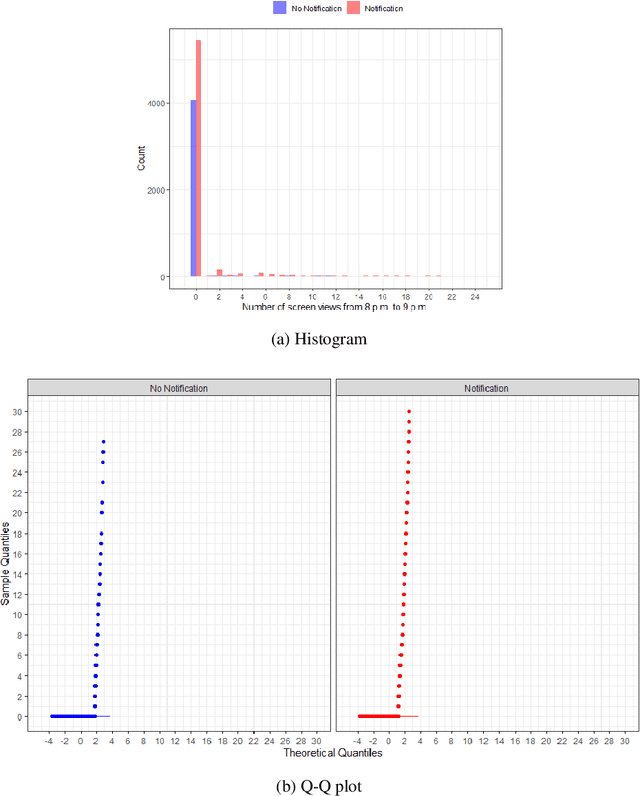
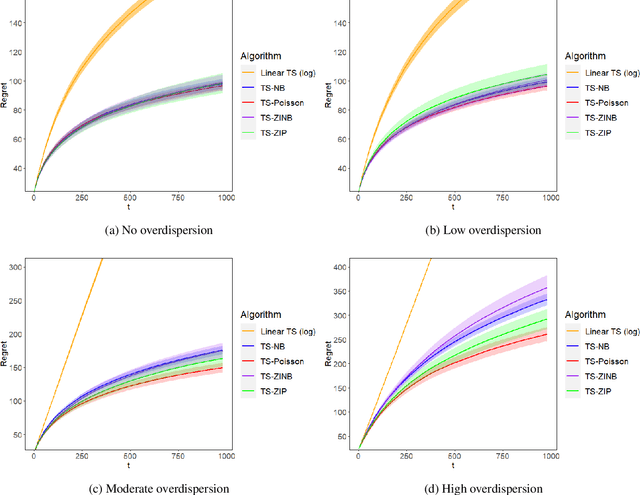
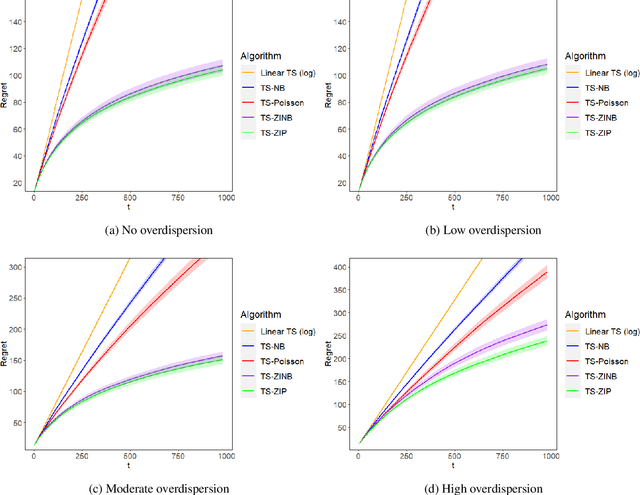
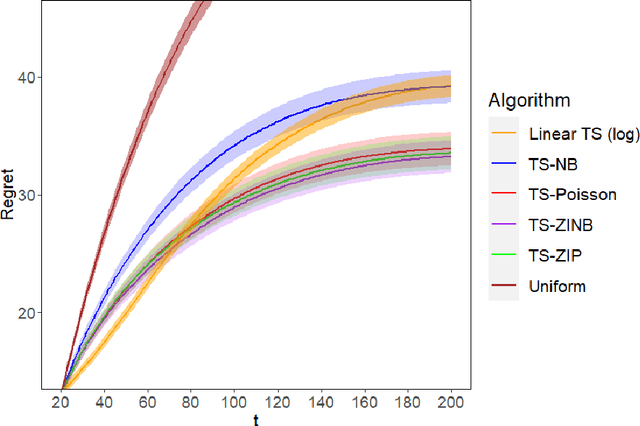
Mobile health (mHealth) technologies aim to improve distal outcomes, such as clinical conditions, by optimizing proximal outcomes through just-in-time adaptive interventions. Contextual bandits provide a suitable framework for customizing such interventions according to individual time-varying contexts, intending to maximize cumulative proximal outcomes. However, unique challenges such as modeling count outcomes within bandit frameworks have hindered the widespread application of contextual bandits to mHealth studies. The current work addresses this challenge by leveraging count data models into online decision-making approaches. Specifically, we combine four common offline count data models (Poisson, negative binomial, zero-inflated Poisson, and zero-inflated negative binomial regressions) with Thompson sampling, a popular contextual bandit algorithm. The proposed algorithms are motivated by and evaluated on a real dataset from the Drink Less trial, where they are shown to improve user engagement with the mHealth system. The proposed methods are further evaluated on simulated data, achieving improvement in maximizing cumulative proximal outcomes over existing algorithms. Theoretical results on regret bounds are also derived. A user-friendly R package countts that implements the proposed methods for assessing contextual bandit algorithms is made publicly available at https://cran.r-project.org/web/packages/countts.
Using Adaptive Bandit Experiments to Increase and Investigate Engagement in Mental Health
Oct 13, 2023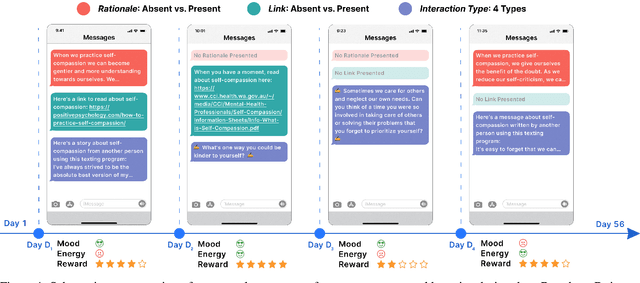

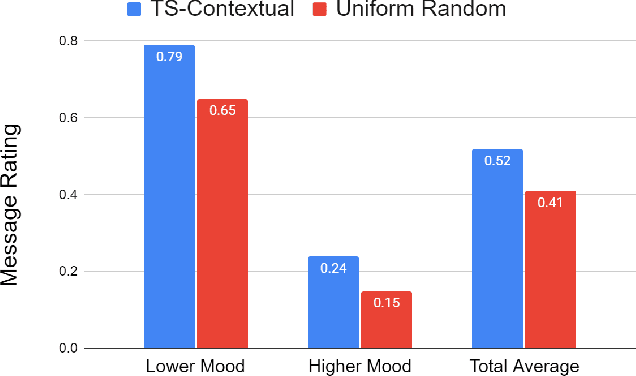

Digital mental health (DMH) interventions, such as text-message-based lessons and activities, offer immense potential for accessible mental health support. While these interventions can be effective, real-world experimental testing can further enhance their design and impact. Adaptive experimentation, utilizing algorithms like Thompson Sampling for (contextual) multi-armed bandit (MAB) problems, can lead to continuous improvement and personalization. However, it remains unclear when these algorithms can simultaneously increase user experience rewards and facilitate appropriate data collection for social-behavioral scientists to analyze with sufficient statistical confidence. Although a growing body of research addresses the practical and statistical aspects of MAB and other adaptive algorithms, further exploration is needed to assess their impact across diverse real-world contexts. This paper presents a software system developed over two years that allows text-messaging intervention components to be adapted using bandit and other algorithms while collecting data for side-by-side comparison with traditional uniform random non-adaptive experiments. We evaluate the system by deploying a text-message-based DMH intervention to 1100 users, recruited through a large mental health non-profit organization, and share the path forward for deploying this system at scale. This system not only enables applications in mental health but could also serve as a model testbed for adaptive experimentation algorithms in other domains.
Multi-disciplinary fairness considerations in machine learning for clinical trials
May 18, 2022While interest in the application of machine learning to improve healthcare has grown tremendously in recent years, a number of barriers prevent deployment in medical practice. A notable concern is the potential to exacerbate entrenched biases and existing health disparities in society. The area of fairness in machine learning seeks to address these issues of equity; however, appropriate approaches are context-dependent, necessitating domain-specific consideration. We focus on clinical trials, i.e., research studies conducted on humans to evaluate medical treatments. Clinical trials are a relatively under-explored application in machine learning for healthcare, in part due to complex ethical, legal, and regulatory requirements and high costs. Our aim is to provide a multi-disciplinary assessment of how fairness for machine learning fits into the context of clinical trials research and practice. We start by reviewing the current ethical considerations and guidelines for clinical trials and examine their relationship with common definitions of fairness in machine learning. We examine potential sources of unfairness in clinical trials, providing concrete examples, and discuss the role machine learning might play in either mitigating potential biases or exacerbating them when applied without care. Particular focus is given to adaptive clinical trials, which may employ machine learning. Finally, we highlight concepts that require further investigation and development, and emphasize new approaches to fairness that may be relevant to the design of clinical trials.
Reinforcement Learning in Modern Biostatistics: Constructing Optimal Adaptive Interventions
Mar 04, 2022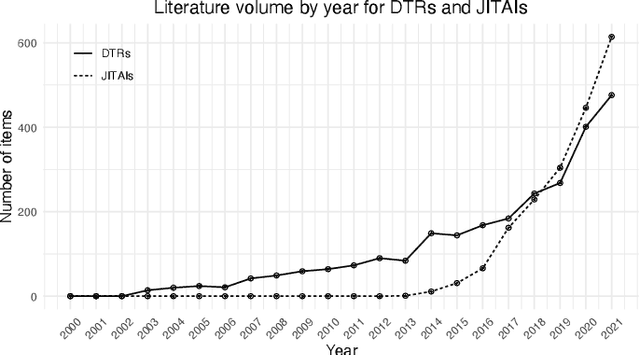

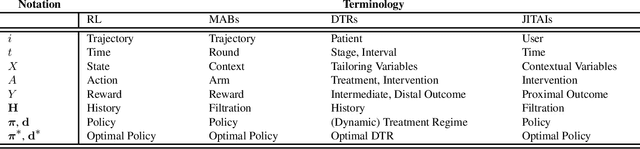
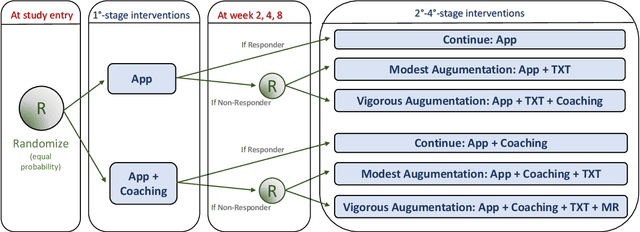
Reinforcement learning (RL) is acquiring a key role in the space of adaptive interventions (AIs), attracting a substantial interest within methodological and theoretical literature and becoming increasingly popular within health sciences. Despite potential benefits, its application in real life is still limited due to several operational and statistical challenges--in addition to ethical and cost issues among others--that remain open in part due to poor communication and synergy between methodological and applied scientists. In this work, we aim to bridge the different domains that contribute to and may benefit from RL, under a unique framework that intersects the areas of RL, causal inference, and AIs, among others. We provide the first unified instructive survey on RL methods for building AIs, encompassing both dynamic treatment regimes (DTRs) and just-in-time adaptive interventions in mobile health (mHealth). We outline similarities and differences between the two areas, and discuss their implications for using RL. We combine our relevant methodological knowledge with motivating studies in both DTRs and mHealth to illustrate the tremendous collaboration opportunities between statistical, RL, and healthcare researchers in the space of AIs.
Algorithms for Adaptive Experiments that Trade-off Statistical Analysis with Reward: Combining Uniform Random Assignment and Reward Maximization
Dec 21, 2021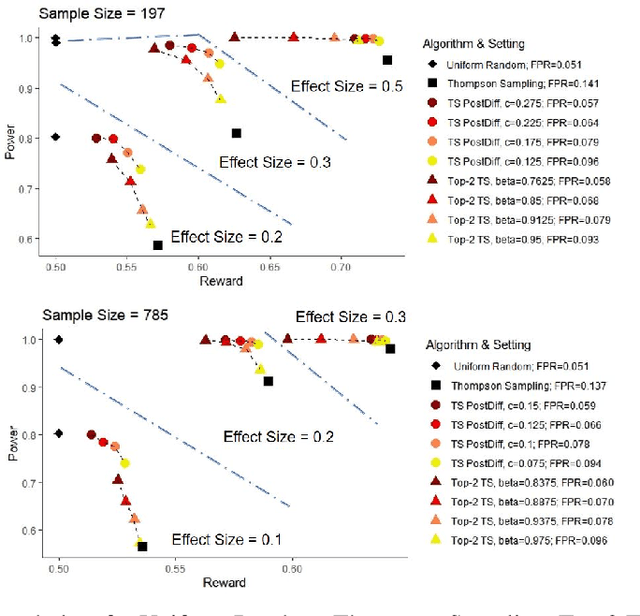
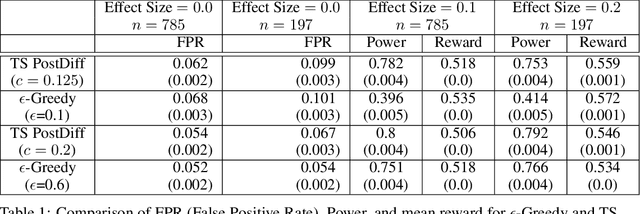
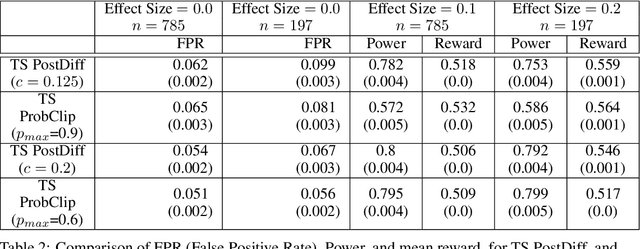
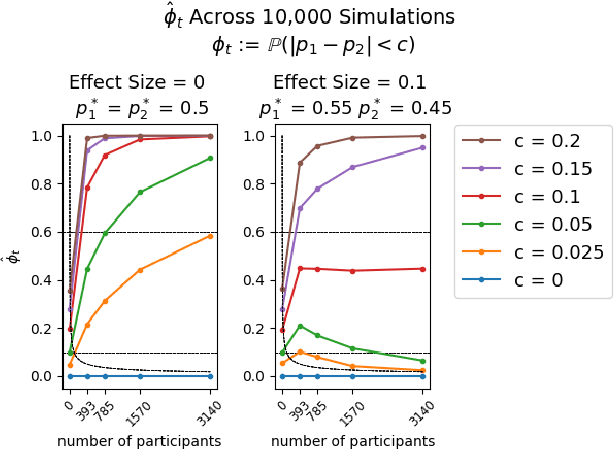
Multi-armed bandit algorithms like Thompson Sampling can be used to conduct adaptive experiments, in which maximizing reward means that data is used to progressively assign more participants to more effective arms. Such assignment strategies increase the risk of statistical hypothesis tests identifying a difference between arms when there is not one, and failing to conclude there is a difference in arms when there truly is one. We present simulations for 2-arm experiments that explore two algorithms that combine the benefits of uniform randomization for statistical analysis, with the benefits of reward maximization achieved by Thompson Sampling (TS). First, Top-Two Thompson Sampling adds a fixed amount of uniform random allocation (UR) spread evenly over time. Second, a novel heuristic algorithm, called TS PostDiff (Posterior Probability of Difference). TS PostDiff takes a Bayesian approach to mixing TS and UR: the probability a participant is assigned using UR allocation is the posterior probability that the difference between two arms is `small' (below a certain threshold), allowing for more UR exploration when there is little or no reward to be gained. We find that TS PostDiff method performs well across multiple effect sizes, and thus does not require tuning based on a guess for the true effect size.
Efficient Inference Without Trading-off Regret in Bandits: An Allocation Probability Test for Thompson Sampling
Oct 30, 2021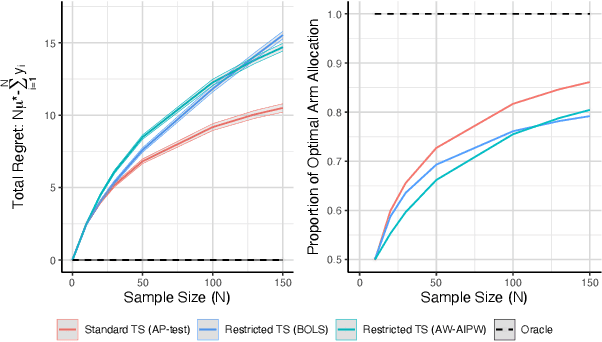
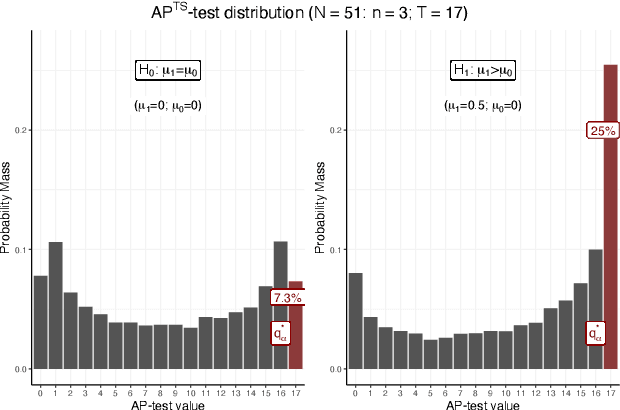

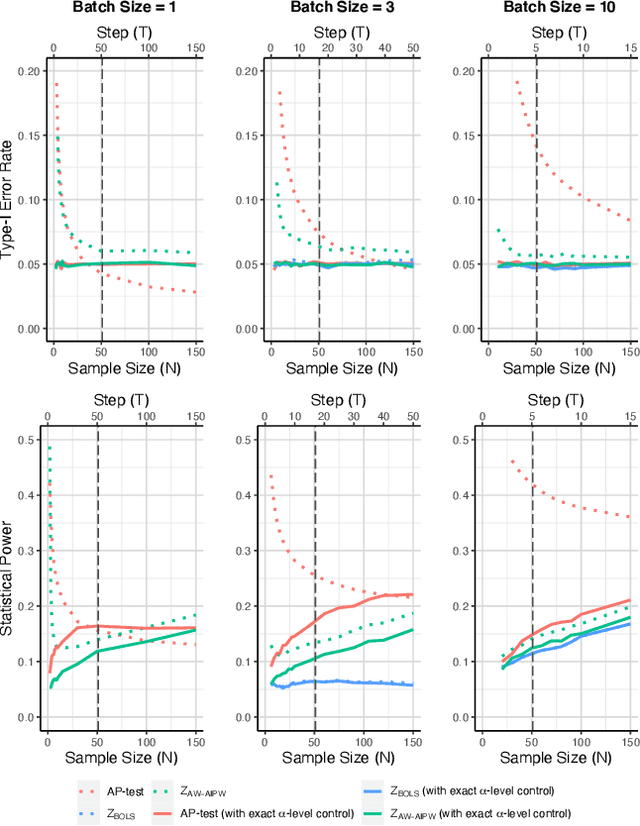
Using bandit algorithms to conduct adaptive randomised experiments can minimise regret, but it poses major challenges for statistical inference (e.g., biased estimators, inflated type-I error and reduced power). Recent attempts to address these challenges typically impose restrictions on the exploitative nature of the bandit algorithm$-$trading off regret$-$and require large sample sizes to ensure asymptotic guarantees. However, large experiments generally follow a successful pilot study, which is tightly constrained in its size or duration. Increasing power in such small pilot experiments, without limiting the adaptive nature of the algorithm, can allow promising interventions to reach a larger experimental phase. In this work we introduce a novel hypothesis test, uniquely based on the allocation probabilities of the bandit algorithm, and without constraining its exploitative nature or requiring a minimum experimental size. We characterise our $Allocation\ Probability\ Test$ when applied to $Thompson\ Sampling$, presenting its asymptotic theoretical properties, and illustrating its finite-sample performances compared to state-of-the-art approaches. We demonstrate the regret and inferential advantages of our approach, particularly in small samples, in both extensive simulations and in a real-world experiment on mental health aspects.
Challenges in Statistical Analysis of Data Collected by a Bandit Algorithm: An Empirical Exploration in Applications to Adaptively Randomized Experiments
Mar 26, 2021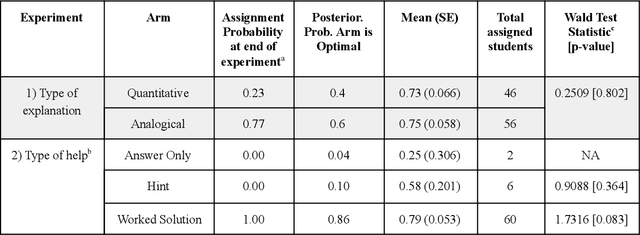
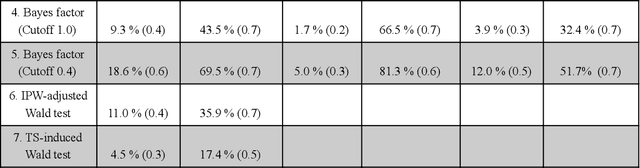
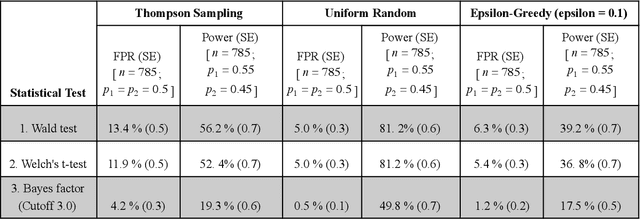
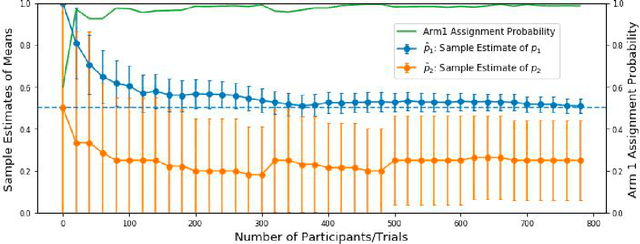
Multi-armed bandit algorithms have been argued for decades as useful for adaptively randomized experiments. In such experiments, an algorithm varies which arms (e.g. alternative interventions to help students learn) are assigned to participants, with the goal of assigning higher-reward arms to as many participants as possible. We applied the bandit algorithm Thompson Sampling (TS) to run adaptive experiments in three university classes. Instructors saw great value in trying to rapidly use data to give their students in the experiments better arms (e.g. better explanations of a concept). Our deployment, however, illustrated a major barrier for scientists and practitioners to use such adaptive experiments: a lack of quantifiable insight into how much statistical analysis of specific real-world experiments is impacted (Pallmann et al, 2018; FDA, 2019), compared to traditional uniform random assignment. We therefore use our case study of the ubiquitous two-arm binary reward setting to empirically investigate the impact of using Thompson Sampling instead of uniform random assignment. In this setting, using common statistical hypothesis tests, we show that collecting data with TS can as much as double the False Positive Rate (FPR; incorrectly reporting differences when none exist) and the False Negative Rate (FNR; failing to report differences when they exist)...