 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Policy Adaptation under Covariate Shift
Jan 14, 2025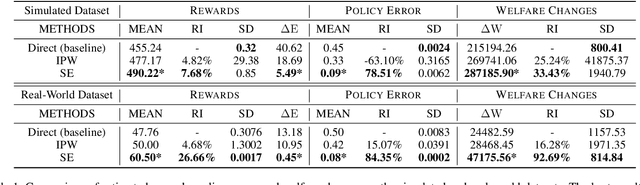
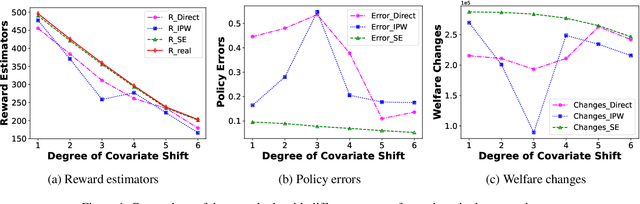
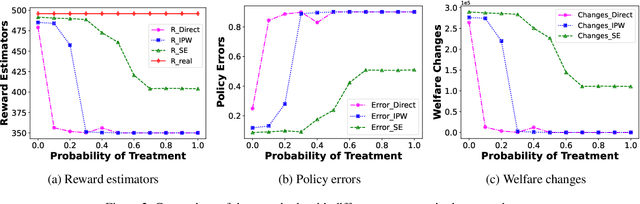
Transfer learning of prediction models has been extensively studied, while the corresponding policy learning approaches are rarely discussed. In this paper, we propose principled approaches for learning the optimal policy in the target domain by leveraging two datasets: one with full information from the source domain and the other from the target domain with only covariates. First, under the setting of covariate shift, we formulate the problem from a perspective of causality and present the identifiability assumptions for the reward induced by a given policy. Then, we derive the efficient influence function and the semiparametric efficiency bound for the reward. Based on this, we construct a doubly robust and semiparametric efficient estimator for the reward and then learn the optimal policy by optimizing the estimated reward. Moreover, we theoretically analyze the bias and the generalization error bound for the learned policy. Furthermore, in the presence of both covariate and concept shifts, we propose a novel sensitivity analysis method to evaluate the robustness of the proposed policy learning approach. Extensive experiments demonstrate that the approach not only estimates the reward more accurately but also yields a policy that closely approximates the theoretically optimal policy.
Compact SPICE model for TeraFET resonant detectors
Jul 27, 2024This paper presents an improved compact model for TeraFETs employing a nonlinear transmission line approach to describe the non-uniform carrier density oscillations and electron inertia effects in the TeraFET channels. By calculating the equivalent components for each segment of the channel: conductance, capacitance, and inductance, based on the voltages at the segment's nodes, our model accommodates non-uniform variations along the channel. We validate the efficacy of this approach by comparing terahertz (THz) response simulations with experimental data and MOSA1, EKV TeraFET SPICE models, analytical theories, and Multiphysics simulations.
Online Uniform Risk Times Sampling: First Approximation Algorithms, Learning Augmentation with Full Confidence Interval Integration
Feb 07, 2024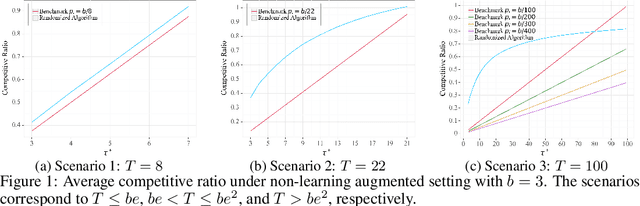
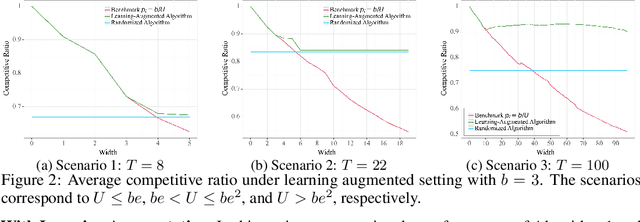
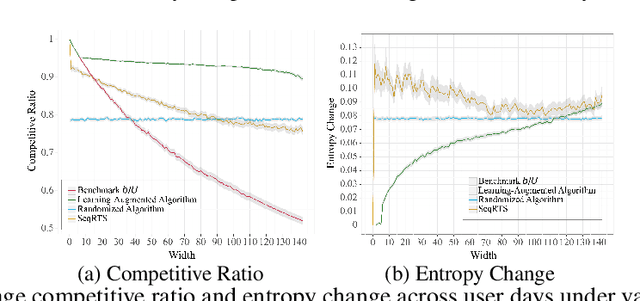
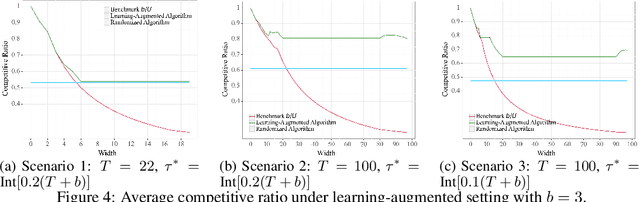
In digital health, the strategy of allocating a limited treatment budget across available risk times is crucial to reduce user fatigue. This strategy, however, encounters a significant obstacle due to the unknown actual number of risk times, a factor not adequately addressed by existing methods lacking theoretical guarantees. This paper introduces, for the first time, the online uniform risk times sampling problem within the approximation algorithm framework. We propose two online approximation algorithms for this problem, one with and one without learning augmentation, and provide rigorous theoretical performance guarantees for them using competitive ratio analysis. We assess the performance of our algorithms using both synthetic experiments and a real-world case study on HeartSteps mobile applications.
Thompson sampling for zero-inflated count outcomes with an application to the Drink Less mobile health study
Nov 24, 2023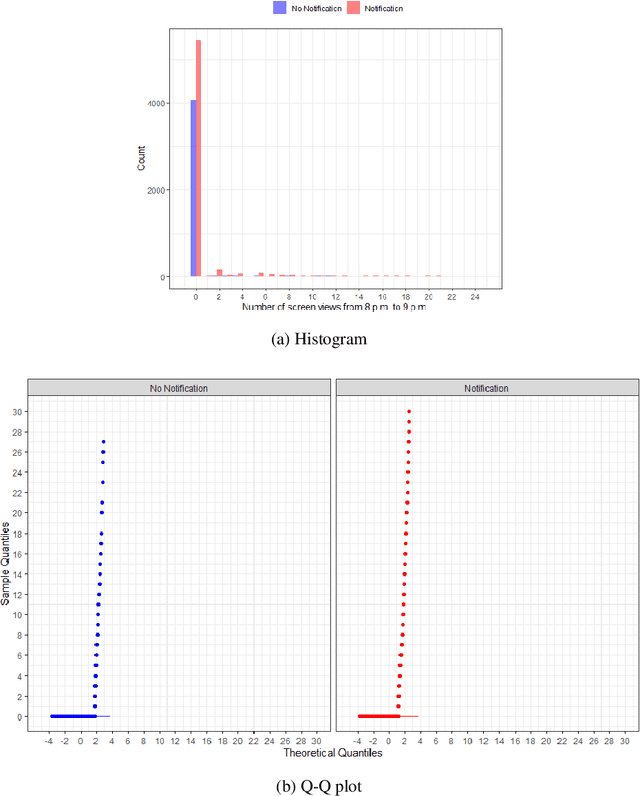
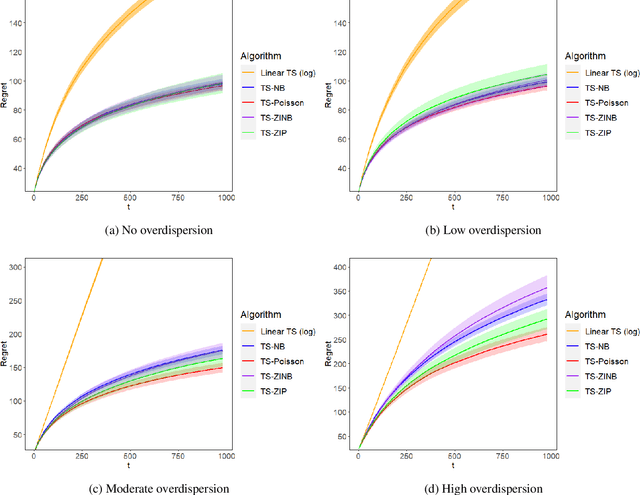
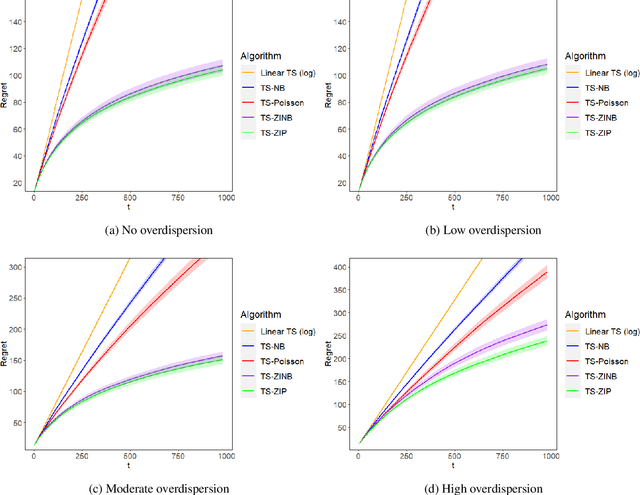
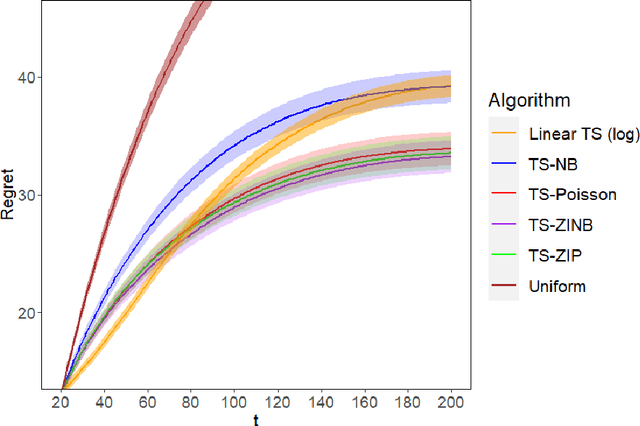
Mobile health (mHealth) technologies aim to improve distal outcomes, such as clinical conditions, by optimizing proximal outcomes through just-in-time adaptive interventions. Contextual bandits provide a suitable framework for customizing such interventions according to individual time-varying contexts, intending to maximize cumulative proximal outcomes. However, unique challenges such as modeling count outcomes within bandit frameworks have hindered the widespread application of contextual bandits to mHealth studies. The current work addresses this challenge by leveraging count data models into online decision-making approaches. Specifically, we combine four common offline count data models (Poisson, negative binomial, zero-inflated Poisson, and zero-inflated negative binomial regressions) with Thompson sampling, a popular contextual bandit algorithm. The proposed algorithms are motivated by and evaluated on a real dataset from the Drink Less trial, where they are shown to improve user engagement with the mHealth system. The proposed methods are further evaluated on simulated data, achieving improvement in maximizing cumulative proximal outcomes over existing algorithms. Theoretical results on regret bounds are also derived. A user-friendly R package countts that implements the proposed methods for assessing contextual bandit algorithms is made publicly available at https://cran.r-project.org/web/packages/countts.
Testing Hateful Speeches against Policies
Jul 23, 2023In the recent years, many software systems have adopted AI techniques, especially deep learning techniques. Due to their black-box nature, AI-based systems brought challenges to traceability, because AI system behaviors are based on models and data, whereas the requirements or policies are rules in the form of natural or programming language. To the best of our knowledge, there is a limited amount of studies on how AI and deep neural network-based systems behave against rule-based requirements/policies. This experience paper examines deep neural network behaviors against rule-based requirements described in natural language policies. In particular, we focus on a case study to check AI-based content moderation software against content moderation policies. First, using crowdsourcing, we collect natural language test cases which match each moderation policy, we name this dataset HateModerate; second, using the test cases in HateModerate, we test the failure rates of state-of-the-art hate speech detection software, and we find that these models have high failure rates for certain policies; finally, since manual labeling is costly, we further proposed an automated approach to augument HateModerate by finetuning OpenAI's large language models to automatically match new examples to policies. The dataset and code of this work can be found on our anonymous website: \url{https://sites.google.com/view/content-moderation-project}.
Contextual Bandits with Budgeted Information Reveal
May 29, 2023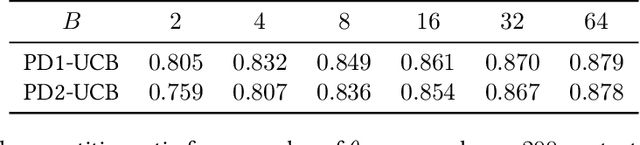
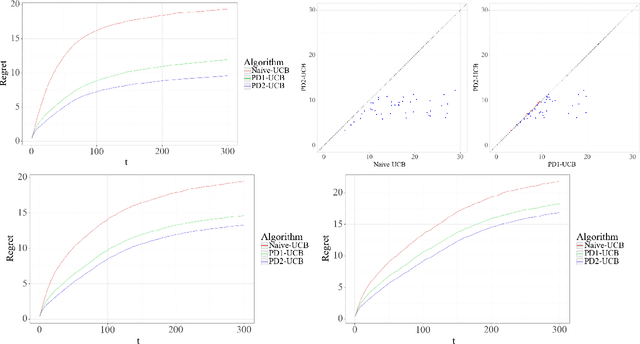
Contextual bandit algorithms are commonly used in digital health to recommend personalized treatments. However, to ensure the effectiveness of the treatments, patients are often requested to take actions that have no immediate benefit to them, which we refer to as pro-treatment actions. In practice, clinicians have a limited budget to encourage patients to take these actions and collect additional information. We introduce a novel optimization and learning algorithm to address this problem. This algorithm effectively combines the strengths of two algorithmic approaches in a seamless manner, including 1) an online primal-dual algorithm for deciding the optimal timing to reach out to patients, and 2) a contextual bandit learning algorithm to deliver personalized treatment to the patient. We prove that this algorithm admits a sub-linear regret bound. We illustrate the usefulness of this algorithm on both synthetic and real-world data.
Inferring latent neural sources via deep transcoding of simultaneously acquired EEG and fMRI
Nov 27, 2022Simultaneous EEG-fMRI is a multi-modal neuroimaging technique that provides complementary spatial and temporal resolution. Challenging has been developing principled and interpretable approaches for fusing the modalities, specifically approaches enabling inference of latent source spaces representative of neural activity. In this paper, we address this inference problem within the framework of transcoding -- mapping from a specific encoding (modality) to a decoding (the latent source space) and then encoding the latent source space to the other modality. Specifically, we develop a symmetric method consisting of a cyclic convolutional transcoder that transcodes EEG to fMRI and vice versa. Without any prior knowledge of either the hemodynamic response function or lead field matrix, the complete data-driven method exploits the temporal and spatial relationships between the modalities and latent source spaces to learn these mappings. We quantify, for both the simulated and real EEG-fMRI data, how well the modalities can be transcoded from one to another as well as the source spaces that are recovered, all evaluated on unseen data. In addition to enabling a new way to symmetrically infer a latent source space, the method can also be seen as low-cost computational neuroimaging -- i.e. generating an 'expensive' fMRI BOLD image from 'low cost' EEG data.
TestAug: A Framework for Augmenting Capability-based NLP Tests
Oct 14, 2022
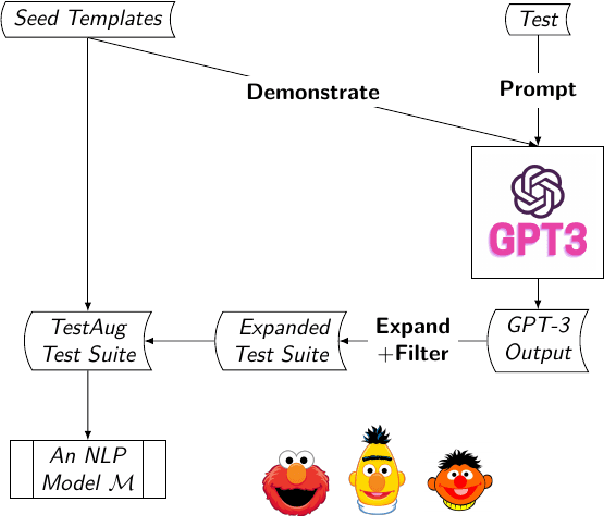

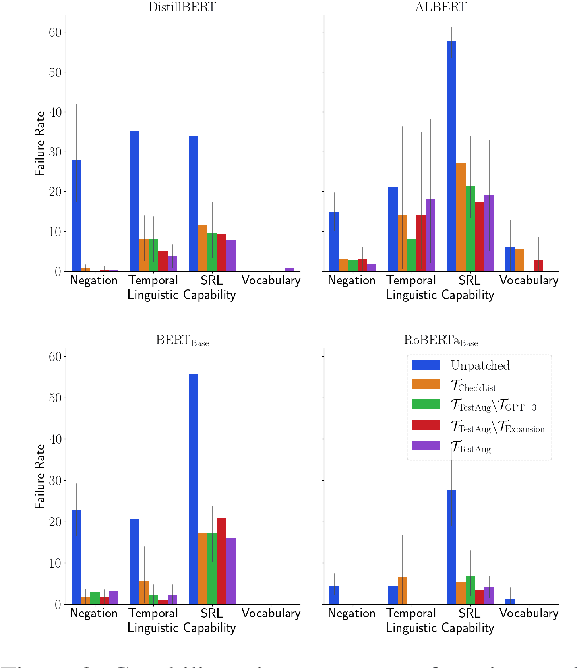
The recently proposed capability-based NLP testing allows model developers to test the functional capabilities of NLP models, revealing functional failures that cannot be detected by the traditional heldout mechanism. However, existing work on capability-based testing requires extensive manual efforts and domain expertise in creating the test cases. In this paper, we investigate a low-cost approach for the test case generation by leveraging the GPT-3 engine. We further propose to use a classifier to remove the invalid outputs from GPT-3 and expand the outputs into templates to generate more test cases. Our experiments show that TestAug has three advantages over the existing work on behavioral testing: (1) TestAug can find more bugs than existing work; (2) The test cases in TestAug are more diverse; and (3) TestAug largely saves the manual efforts in creating the test suites. The code and data for TestAug can be found at our project website (https://guanqun-yang.github.io/testaug/) and GitHub (https://github.com/guanqun-yang/testaug).
Few-Sample Named Entity Recognition for Security Vulnerability Reports by Fine-Tuning Pre-Trained Language Models
Aug 14, 2021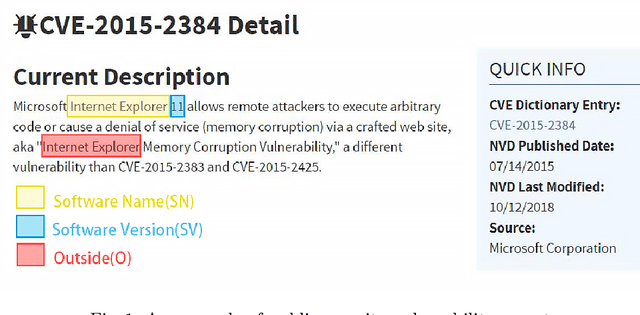
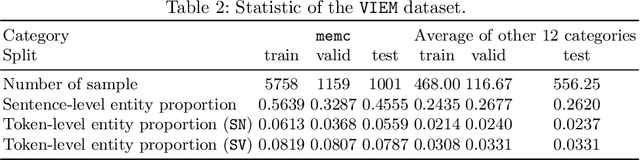
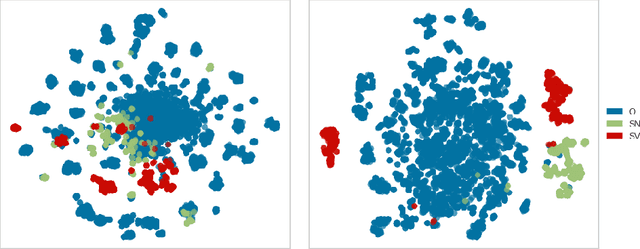
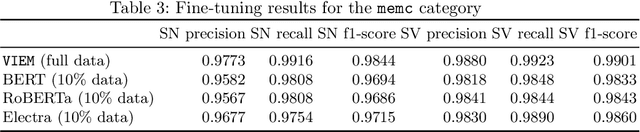
Public security vulnerability reports (e.g., CVE reports) play an important role in the maintenance of computer and network systems. Security companies and administrators rely on information from these reports to prioritize tasks on developing and deploying patches to their customers. Since these reports are unstructured texts, automatic information extraction (IE) can help scale up the processing by converting the unstructured reports to structured forms, e.g., software names and versions and vulnerability types. Existing works on automated IE for security vulnerability reports often rely on a large number of labeled training samples. However, creating massive labeled training set is both expensive and time consuming. In this work, for the first time, we propose to investigate this problem where only a small number of labeled training samples are available. In particular, we investigate the performance of fine-tuning several state-of-the-art pre-trained language models on our small training dataset. The results show that with pre-trained language models and carefully tuned hyperparameters, we have reached or slightly outperformed the state-of-the-art system on this task. Consistent with previous two-step process of first fine-tuning on main category and then transfer learning to others as in [7], if otherwise following our proposed approach, the number of required labeled samples substantially decrease in both stages: 90% reduction in fine-tuning from 5758 to 576,and 88.8% reduction in transfer learning with 64 labeled samples per category. Our experiments thus demonstrate the effectiveness of few-sample learning on NER for security vulnerability report. This result opens up multiple research opportunities for few-sample learning for security vulnerability reports, which is discussed in the paper. Code: https://github.com/guanqun-yang/FewVulnerability.
An Empirical Study on Hyperparameter Optimization for Fine-Tuning Pre-trained Language Models
Jun 17, 2021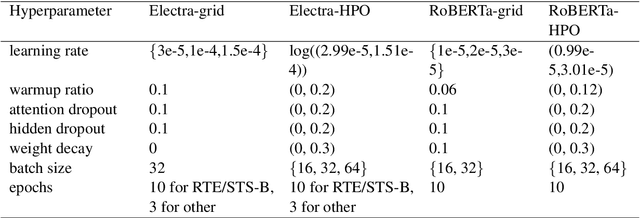
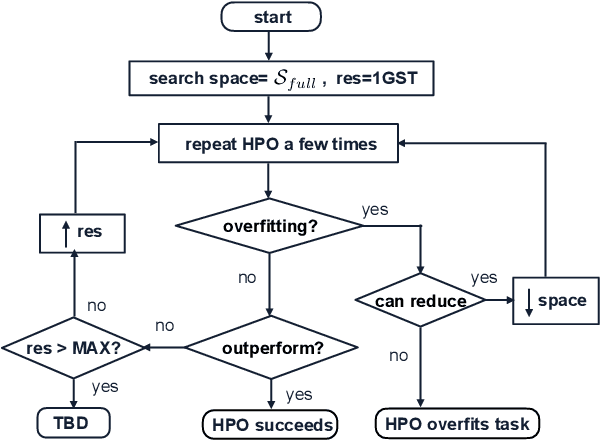
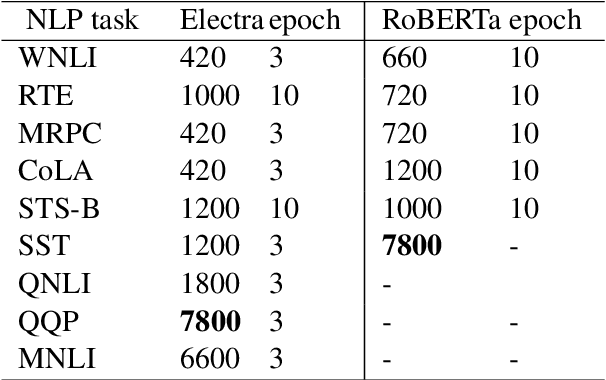
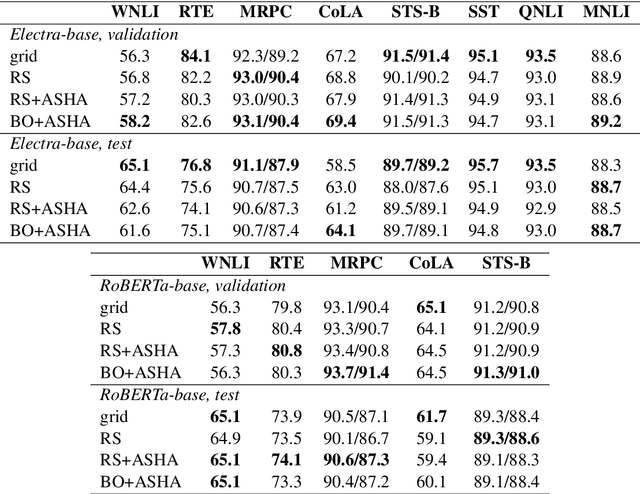
The performance of fine-tuning pre-trained language models largely depends on the hyperparameter configuration. In this paper, we investigate the performance of modern hyperparameter optimization methods (HPO) on fine-tuning pre-trained language models. First, we study and report three HPO algorithms' performances on fine-tuning two state-of-the-art language models on the GLUE dataset. We find that using the same time budget, HPO often fails to outperform grid search due to two reasons: insufficient time budget and overfitting. We propose two general strategies and an experimental procedure to systematically troubleshoot HPO's failure cases. By applying the procedure, we observe that HPO can succeed with more appropriate settings in the search space and time budget; however, in certain cases overfitting remains. Finally, we make suggestions for future work. Our implementation can be found in https://github.com/microsoft/FLAML/tree/main/flaml/nlp/.