 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
RELEAP: Reinforcement-Enhanced Label-Efficient Active Phenotyping for Electronic Health Records
Nov 08, 2025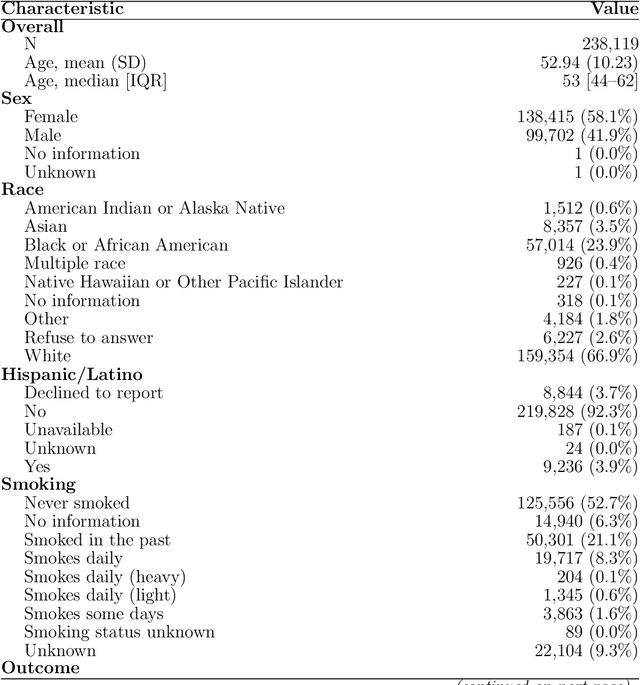

Objective: Electronic health record (EHR) phenotyping often relies on noisy proxy labels, which undermine the reliability of downstream risk prediction. Active learning can reduce annotation costs, but most rely on fixed heuristics and do not ensure that phenotype refinement improves prediction performance. Our goal was to develop a framework that directly uses downstream prediction performance as feedback to guide phenotype correction and sample selection under constrained labeling budgets. Materials and Methods: We propose Reinforcement-Enhanced Label-Efficient Active Phenotyping (RELEAP), a reinforcement learning-based active learning framework. RELEAP adaptively integrates multiple querying strategies and, unlike prior methods, updates its policy based on feedback from downstream models. We evaluated RELEAP on a de-identified Duke University Health System (DUHS) cohort (2014-2024) for incident lung cancer risk prediction, using logistic regression and penalized Cox survival models. Performance was benchmarked against noisy-label baselines and single-strategy active learning. Results: RELEAP consistently outperformed all baselines. Logistic AUC increased from 0.774 to 0.805 and survival C-index from 0.718 to 0.752. Using downstream performance as feedback, RELEAP produced smoother and more stable gains than heuristic methods under the same labeling budget. Discussion: By linking phenotype refinement to prediction outcomes, RELEAP learns which samples most improve downstream discrimination and calibration, offering a more principled alternative to fixed active learning rules. Conclusion: RELEAP optimizes phenotype correction through downstream feedback, offering a scalable, label-efficient paradigm that reduces manual chart review and enhances the reliability of EHR-based risk prediction.
Artificial Intelligence-based Decision Support Systems for Precision and Digital Health
Jul 22, 2024Precision health, increasingly supported by digital technologies, is a domain of research that broadens the paradigm of precision medicine, advancing everyday healthcare. This vision goes hand in hand with the groundbreaking advent of artificial intelligence (AI), which is reshaping the way we diagnose, treat, and monitor both clinical subjects and the general population. AI tools powered by machine learning have shown considerable improvements in a variety of healthcare domains. In particular, reinforcement learning (RL) holds great promise for sequential and dynamic problems such as dynamic treatment regimes and just-in-time adaptive interventions in digital health. In this work, we discuss the opportunity offered by AI, more specifically RL, to current trends in healthcare, providing a methodological survey of RL methods in the context of precision and digital health. Focusing on the area of adaptive interventions, we expand the methodological survey with illustrative case studies that used RL in real practice. This invited article has undergone anonymous review and is intended as a book chapter for the volume "Frontiers of Statistics and Data Science" edited by Subhashis Ghoshal and Anindya Roy for the International Indian Statistical Association Series on Statistics and Data Science, published by Springer. It covers the material from a short course titled "Artificial Intelligence in Precision and Digital Health" taught by the author Bibhas Chakraborty at the IISA 2022 Conference, December 26-30 2022, at the Indian Institute of Science, Bengaluru.
Developing Federated Time-to-Event Scores Using Heterogeneous Real-World Survival Data
Mar 08, 2024

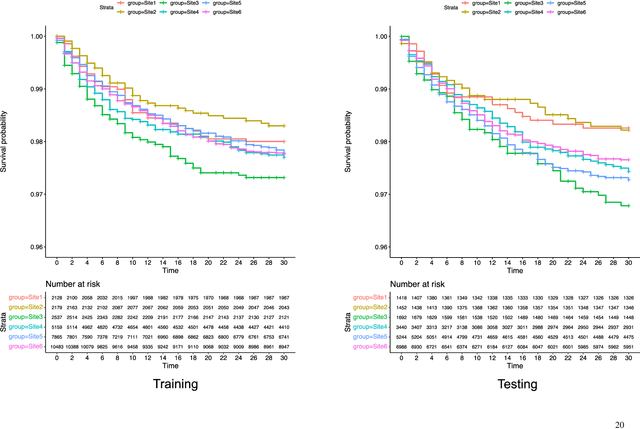
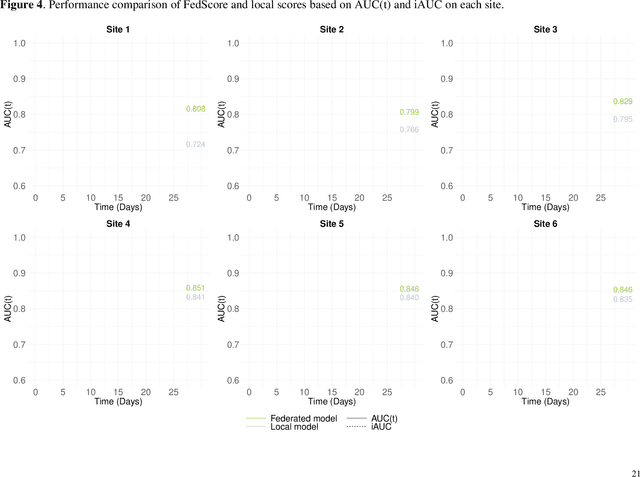
Survival analysis serves as a fundamental component in numerous healthcare applications, where the determination of the time to specific events (such as the onset of a certain disease or death) for patients is crucial for clinical decision-making. Scoring systems are widely used for swift and efficient risk prediction. However, existing methods for constructing survival scores presume that data originates from a single source, posing privacy challenges in collaborations with multiple data owners. We propose a novel framework for building federated scoring systems for multi-site survival outcomes, ensuring both privacy and communication efficiency. We applied our approach to sites with heterogeneous survival data originating from emergency departments in Singapore and the United States. Additionally, we independently developed local scores at each site. In testing datasets from each participant site, our proposed federated scoring system consistently outperformed all local models, evidenced by higher integrated area under the receiver operating characteristic curve (iAUC) values, with a maximum improvement of 11.6%. Additionally, the federated score's time-dependent AUC(t) values showed advantages over local scores, exhibiting narrower confidence intervals (CIs) across most time points. The model developed through our proposed method exhibits effective performance on each local site, signifying noteworthy implications for healthcare research. Sites participating in our proposed federated scoring model training gained benefits by acquiring survival models with enhanced prediction accuracy and efficiency. This study demonstrates the effectiveness of our privacy-preserving federated survival score generation framework and its applicability to real-world heterogeneous survival data.
Fairness-Aware Interpretable Modeling (FAIM) for Trustworthy Machine Learning in Healthcare
Mar 08, 2024
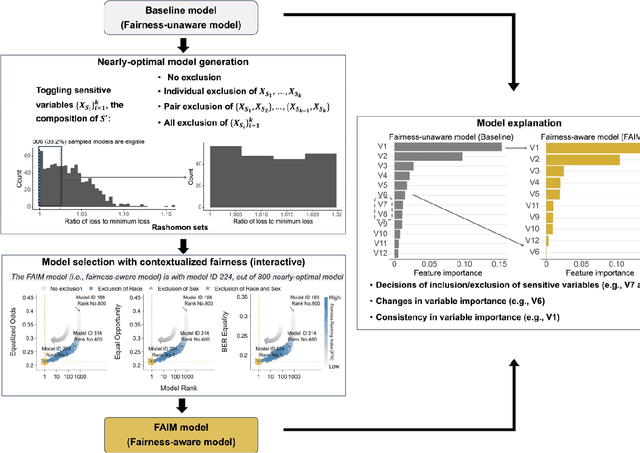


The escalating integration of machine learning in high-stakes fields such as healthcare raises substantial concerns about model fairness. We propose an interpretable framework - Fairness-Aware Interpretable Modeling (FAIM), to improve model fairness without compromising performance, featuring an interactive interface to identify a "fairer" model from a set of high-performing models and promoting the integration of data-driven evidence and clinical expertise to enhance contextualized fairness. We demonstrated FAIM's value in reducing sex and race biases by predicting hospital admission with two real-world databases, MIMIC-IV-ED and SGH-ED. We show that for both datasets, FAIM models not only exhibited satisfactory discriminatory performance but also significantly mitigated biases as measured by well-established fairness metrics, outperforming commonly used bias-mitigation methods. Our approach demonstrates the feasibility of improving fairness without sacrificing performance and provides an a modeling mode that invites domain experts to engage, fostering a multidisciplinary effort toward tailored AI fairness.
Skew Probabilistic Neural Networks for Learning from Imbalanced Data
Dec 10, 2023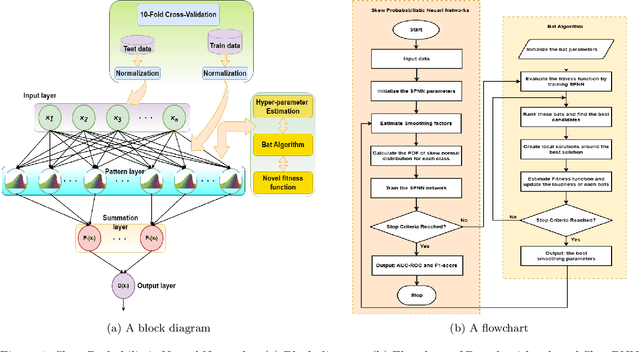



Real-world datasets often exhibit imbalanced data distribution, where certain class levels are severely underrepresented. In such cases, traditional pattern classifiers have shown a bias towards the majority class, impeding accurate predictions for the minority class. This paper introduces an imbalanced data-oriented approach using probabilistic neural networks (PNNs) with a skew normal probability kernel to address this major challenge. PNNs are known for providing probabilistic outputs, enabling quantification of prediction confidence and uncertainty handling. By leveraging the skew normal distribution, which offers increased flexibility, particularly for imbalanced and non-symmetric data, our proposed Skew Probabilistic Neural Networks (SkewPNNs) can better represent underlying class densities. To optimize the performance of the proposed approach on imbalanced datasets, hyperparameter fine-tuning is imperative. To this end, we employ a population-based heuristic algorithm, Bat optimization algorithms, for effectively exploring the hyperparameter space. We also prove the statistical consistency of the density estimates which suggests that the true distribution will be approached smoothly as the sample size increases. Experimental simulations have been conducted on different synthetic datasets, comparing various benchmark-imbalanced learners. Our real-data analysis shows that SkewPNNs substantially outperform state-of-the-art machine learning methods for both balanced and imbalanced datasets in most experimental settings.
Thompson sampling for zero-inflated count outcomes with an application to the Drink Less mobile health study
Nov 24, 2023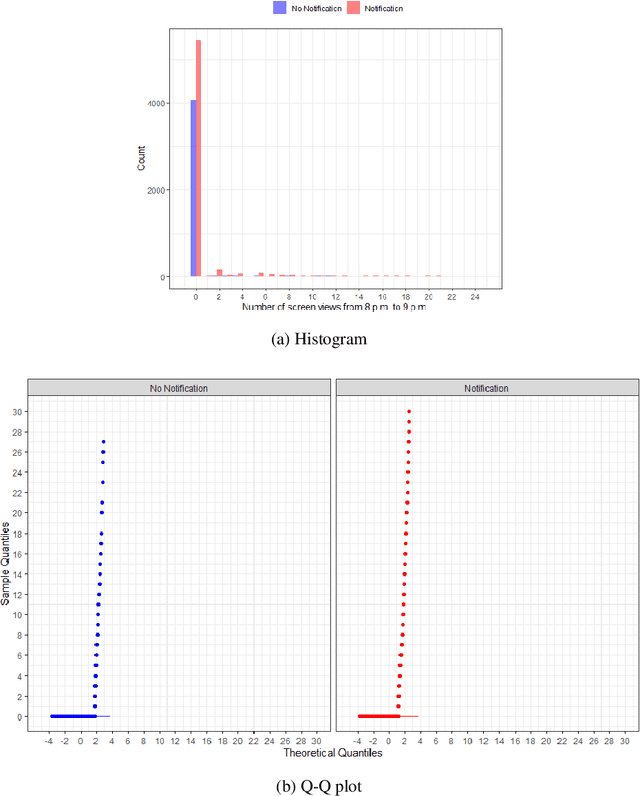
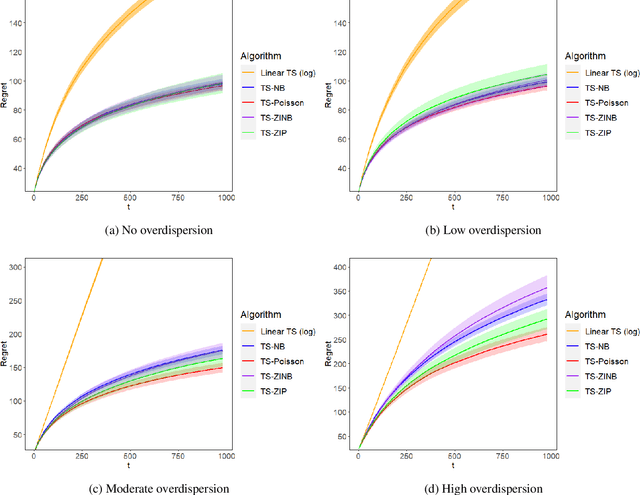
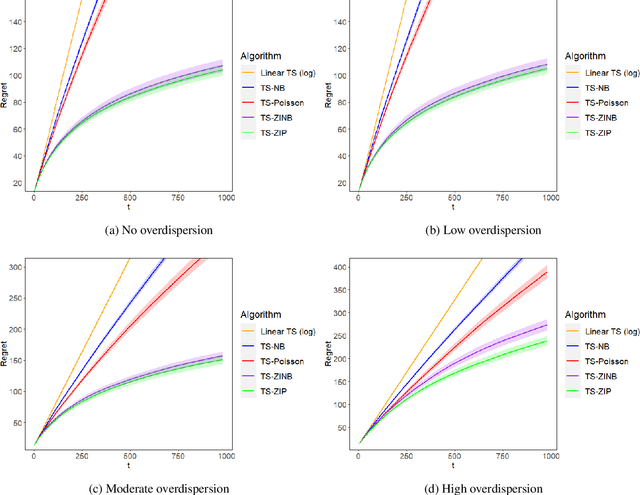
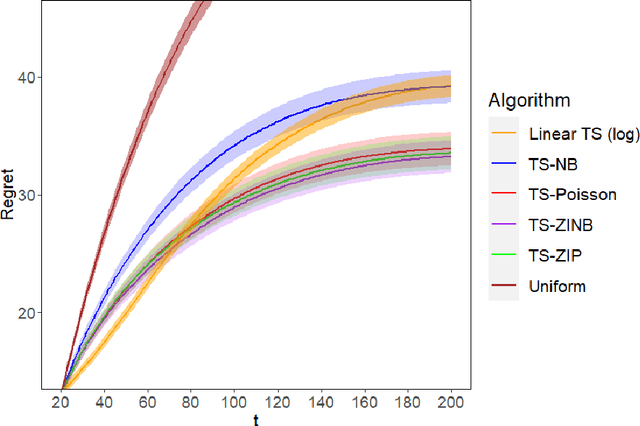
Mobile health (mHealth) technologies aim to improve distal outcomes, such as clinical conditions, by optimizing proximal outcomes through just-in-time adaptive interventions. Contextual bandits provide a suitable framework for customizing such interventions according to individual time-varying contexts, intending to maximize cumulative proximal outcomes. However, unique challenges such as modeling count outcomes within bandit frameworks have hindered the widespread application of contextual bandits to mHealth studies. The current work addresses this challenge by leveraging count data models into online decision-making approaches. Specifically, we combine four common offline count data models (Poisson, negative binomial, zero-inflated Poisson, and zero-inflated negative binomial regressions) with Thompson sampling, a popular contextual bandit algorithm. The proposed algorithms are motivated by and evaluated on a real dataset from the Drink Less trial, where they are shown to improve user engagement with the mHealth system. The proposed methods are further evaluated on simulated data, achieving improvement in maximizing cumulative proximal outcomes over existing algorithms. Theoretical results on regret bounds are also derived. A user-friendly R package countts that implements the proposed methods for assessing contextual bandit algorithms is made publicly available at https://cran.r-project.org/web/packages/countts.
Federated and distributed learning applications for electronic health records and structured medical data: A scoping review
Apr 14, 2023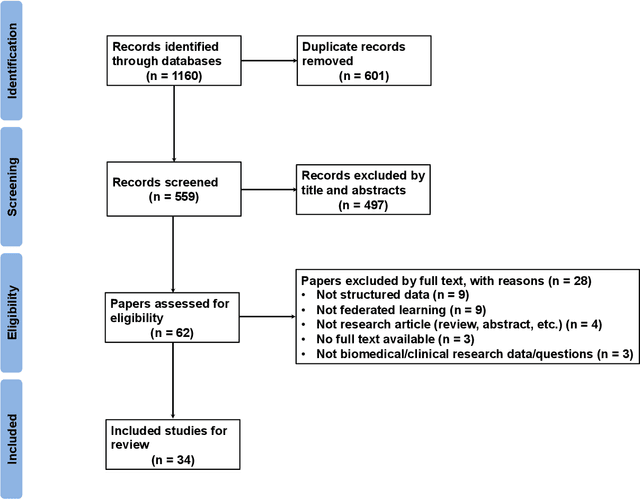


Federated learning (FL) has gained popularity in clinical research in recent years to facilitate privacy-preserving collaboration. Structured data, one of the most prevalent forms of clinical data, has experienced significant growth in volume concurrently, notably with the widespread adoption of electronic health records in clinical practice. This review examines FL applications on structured medical data, identifies contemporary limitations and discusses potential innovations. We searched five databases, SCOPUS, MEDLINE, Web of Science, Embase, and CINAHL, to identify articles that applied FL to structured medical data and reported results following the PRISMA guidelines. Each selected publication was evaluated from three primary perspectives, including data quality, modeling strategies, and FL frameworks. Out of the 1160 papers screened, 34 met the inclusion criteria, with each article consisting of one or more studies that used FL to handle structured clinical/medical data. Of these, 24 utilized data acquired from electronic health records, with clinical predictions and association studies being the most common clinical research tasks that FL was applied to. Only one article exclusively explored the vertical FL setting, while the remaining 33 explored the horizontal FL setting, with only 14 discussing comparisons between single-site (local) and FL (global) analysis. The existing FL applications on structured medical data lack sufficient evaluations of clinically meaningful benefits, particularly when compared to single-site analyses. Therefore, it is crucial for future FL applications to prioritize clinical motivations and develop designs and methodologies that can effectively support and aid clinical practice and research.
FedScore: A privacy-preserving framework for federated scoring system development
Mar 01, 2023

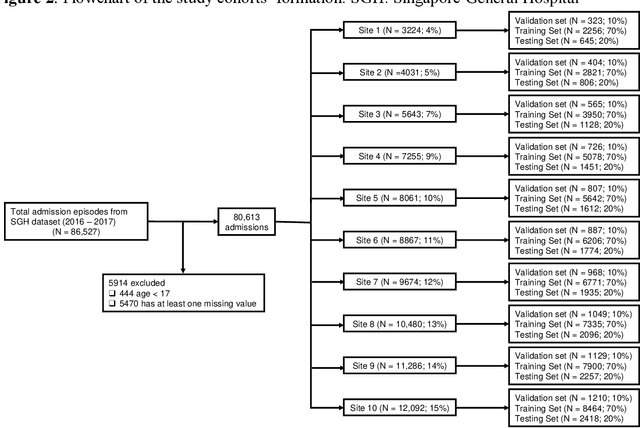

We propose FedScore, a privacy-preserving federated learning framework for scoring system generation across multiple sites to facilitate cross-institutional collaborations. The FedScore framework includes five modules: federated variable ranking, federated variable transformation, federated score derivation, federated model selection and federated model evaluation. To illustrate usage and assess FedScore's performance, we built a hypothetical global scoring system for mortality prediction within 30 days after a visit to an emergency department using 10 simulated sites divided from a tertiary hospital in Singapore. We employed a pre-existing score generator to construct 10 local scoring systems independently at each site and we also developed a scoring system using centralized data for comparison. We compared the acquired FedScore model's performance with that of other scoring models using the receiver operating characteristic (ROC) analysis. The FedScore model achieved an average area under the curve (AUC) value of 0.763 across all sites, with a standard deviation (SD) of 0.020. We also calculated the average AUC values and SDs for each local model, and the FedScore model showed promising accuracy and stability with a high average AUC value which was closest to the one of the pooled model and SD which was lower than that of most local models. This study demonstrates that FedScore is a privacy-preserving scoring system generator with potentially good generalizability.
Handling missing values in healthcare data: A systematic review of deep learning-based imputation techniques
Oct 15, 2022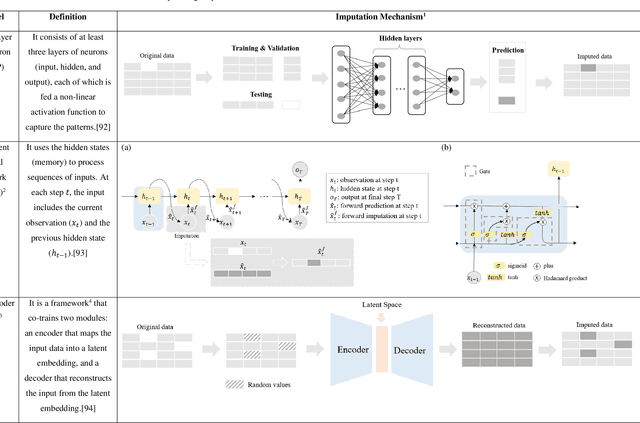
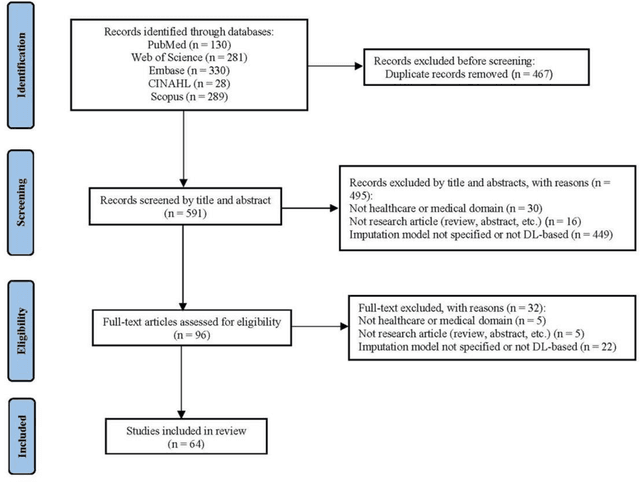
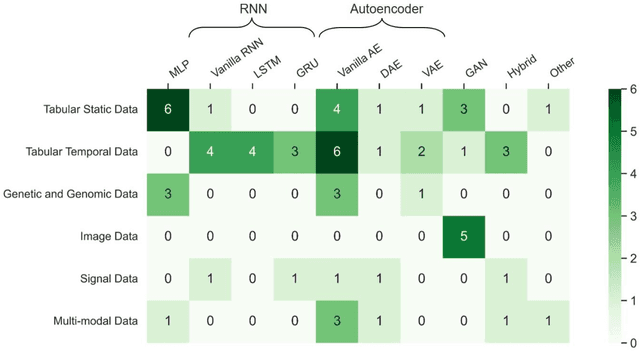
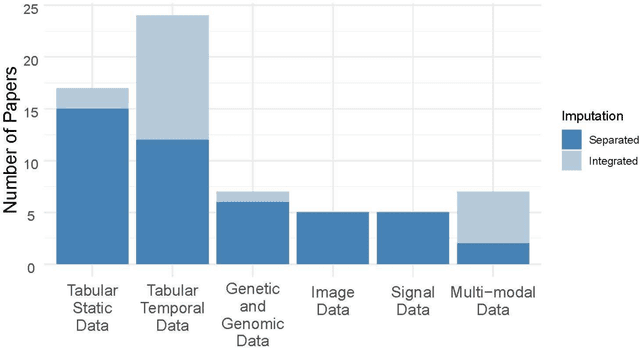
Objective: The proper handling of missing values is critical to delivering reliable estimates and decisions, especially in high-stakes fields such as clinical research. The increasing diversity and complexity of data have led many researchers to develop deep learning (DL)-based imputation techniques. We conducted a systematic review to evaluate the use of these techniques, with a particular focus on data types, aiming to assist healthcare researchers from various disciplines in dealing with missing values. Methods: We searched five databases (MEDLINE, Web of Science, Embase, CINAHL, and Scopus) for articles published prior to August 2021 that applied DL-based models to imputation. We assessed selected publications from four perspectives: health data types, model backbone (i.e., main architecture), imputation strategies, and comparison with non-DL-based methods. Based on data types, we created an evidence map to illustrate the adoption of DL models. Results: We included 64 articles, of which tabular static (26.6%, 17/64) and temporal data (37.5%, 24/64) were the most frequently investigated. We found that model backbone(s) differed among data types as well as the imputation strategy. The "integrated" strategy, that is, the imputation task being solved concurrently with downstream tasks, was popular for tabular temporal (50%, 12/24) and multi-modal data (71.4%, 5/7), but limited for other data types. Moreover, DL-based imputation methods yielded better imputation accuracy in most studies, compared with non-DL-based methods. Conclusion: DL-based imputation models can be customized based on data type, addressing the corresponding missing patterns, and its associated "integrated" strategy can enhance the efficacy of imputation, especially in scenarios where data is complex. Future research may focus on the portability and fairness of DL-based models for healthcare data imputation.