 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConflict-Aware Multimodal Fusion for Ambivalence and Hesitancy Recognition
Mar 16, 2026Ambivalence and hesitancy (A/H) are subtle affective states where a person shows conflicting signals through different channels -- saying one thing while their face or voice tells another story. Recognising these states automatically is valuable in clinical settings, but it is hard for machines because the key evidence lives in the \emph{disagreements} between what is said, how it sounds, and what the face shows. We present \textbf{ConflictAwareAH}, a multimodal framework built for this problem. Three pre-trained encoders extract video, audio, and text representations. Pairwise conflict features -- element-wise absolute differences between modality embeddings -- serve as \emph{bidirectional} cues: large cross-modal differences flag A/H, while small differences confirm behavioural consistency and anchor the negative class. This conflict-aware design addresses a key limitation of text-dominant approaches, which tend to over-detect A/H (high F1-AH) while struggling to confirm its absence: our multimodal model improves F1-NoAH by +4.6 points over text alone and halves the class-performance gap. A complementary \emph{text-guided late fusion} strategy blends a text-only auxiliary head with the full model at inference, adding +4.1 Macro F1. On the BAH dataset from the ABAW10 Ambivalence/Hesitancy Challenge, our method reaches \textbf{0.694 Macro F1} on the labelled test split and \textbf{0.715} on the private leaderboard, outperforming published multimodal baselines by over 10 points -- all on a single GPU in under 25 minutes of training.
Decoding Matters: Efficient Mamba-Based Decoder with Distribution-Aware Deep Supervision for Medical Image Segmentation
Mar 13, 2026Deep learning has achieved remarkable success in medical image segmentation, often reaching expert-level accuracy in delineating tumors and tissues. However, most existing approaches remain task-specific, showing strong performance on individual datasets but limited generalization across diverse imaging modalities. Moreover, many methods focus primarily on the encoder, relying on large pretrained backbones that increase computational complexity. In this paper, we propose a decoder-centric approach for generalized 2D medical image segmentation. The proposed Deco-Mamba follows a U-Net-like structure with a Transformer-CNN-Mamba design. The encoder combines a CNN block and Transformer backbone for efficient feature extraction, while the decoder integrates our novel Co-Attention Gate (CAG), Vision State Space Module (VSSM), and deformable convolutional refinement block to enhance multi-scale contextual representation. Additionally, a windowed distribution-aware KL-divergence loss is introduced for deep supervision across multiple decoding stages. Extensive experiments on diverse medical image segmentation benchmarks yield state-of-the-art performance and strong generalization capability while maintaining moderate model complexity. The source code will be released upon acceptance.
VP-Hype: A Hybrid Mamba-Transformer Framework with Visual-Textual Prompting for Hyperspectral Image Classification
Mar 01, 2026Accurate classification of hyperspectral imagery (HSI) is often frustrated by the tension between high-dimensional spectral data and the extreme scarcity of labeled training samples. While hierarchical models like LoLA-SpecViT have demonstrated the power of local windowed attention and parameter-efficient fine-tuning, the quadratic complexity of standard Transformers remains a barrier to scaling. We introduce VP-Hype, a framework that rethinks HSI classification by unifying the linear-time efficiency of State-Space Models (SSMs) with the relational modeling of Transformers in a novel hybrid architecture. Building on a robust 3D-CNN spectral front-end, VP-Hype replaces conventional attention blocks with a Hybrid Mamba-Transformer backbone to capture long-range dependencies with significantly reduced computational overhead. Furthermore, we address the label-scarcity problem by integrating dual-modal Visual and Textual Prompts that provide context-aware guidance for the feature extraction process. Our experimental evaluation demonstrates that VP-Hype establishes a new state of the art in low-data regimes. Specifically, with a training sample distribution of only 2\%, the model achieves Overall Accuracy (OA) of 99.69\% on the Salinas dataset and 99.45\% on the Longkou dataset. These results suggest that the convergence of hybrid sequence modeling and multi-modal prompting provides a robust path forward for high-performance, sample-efficient remote sensing.
VLM-PAR: A Vision Language Model for Pedestrian Attribute Recognition
Dec 22, 2025Pedestrian Attribute Recognition (PAR) involves predicting fine-grained attributes such as clothing color, gender, and accessories from pedestrian imagery, yet is hindered by severe class imbalance, intricate attribute co-dependencies, and domain shifts. We introduce VLM-PAR, a modular vision-language framework built on frozen SigLIP 2 multilingual encoders. By first aligning image and prompt embeddings via refining visual features through a compact cross-attention fusion, VLM-PAR achieves significant accuracy improvement on the highly imbalanced PA100K benchmark, setting a new state-of-the-art performance, while also delivering significant gains in mean accuracy across PETA and Market-1501 benchmarks. These results underscore the efficacy of integrating large-scale vision-language pretraining with targeted cross-modal refinement to overcome imbalance and generalization challenges in PAR.
RAVID: Retrieval-Augmented Visual Detection: A Knowledge-Driven Approach for AI-Generated Image Identification
Aug 05, 2025In this paper, we introduce RAVID, the first framework for AI-generated image detection that leverages visual retrieval-augmented generation (RAG). While RAG methods have shown promise in mitigating factual inaccuracies in foundation models, they have primarily focused on text, leaving visual knowledge underexplored. Meanwhile, existing detection methods, which struggle with generalization and robustness, often rely on low-level artifacts and model-specific features, limiting their adaptability. To address this, RAVID dynamically retrieves relevant images to enhance detection. Our approach utilizes a fine-tuned CLIP image encoder, RAVID CLIP, enhanced with category-related prompts to improve representation learning. We further integrate a vision-language model (VLM) to fuse retrieved images with the query, enriching the input and improving accuracy. Given a query image, RAVID generates an embedding using RAVID CLIP, retrieves the most relevant images from a database, and combines these with the query image to form an enriched input for a VLM (e.g., Qwen-VL or Openflamingo). Experiments on the UniversalFakeDetect benchmark, which covers 19 generative models, show that RAVID achieves state-of-the-art performance with an average accuracy of 93.85%. RAVID also outperforms traditional methods in terms of robustness, maintaining high accuracy even under image degradations such as Gaussian blur and JPEG compression. Specifically, RAVID achieves an average accuracy of 80.27% under degradation conditions, compared to 63.44% for the state-of-the-art model C2P-CLIP, demonstrating consistent improvements in both Gaussian blur and JPEG compression scenarios. The code will be publicly available upon acceptance.
SAViL-Det: Semantic-Aware Vision-Language Model for Multi-Script Text Detection
Jul 27, 2025Detecting text in natural scenes remains challenging, particularly for diverse scripts and arbitrarily shaped instances where visual cues alone are often insufficient. Existing methods do not fully leverage semantic context. This paper introduces SAViL-Det, a novel semantic-aware vision-language model that enhances multi-script text detection by effectively integrating textual prompts with visual features. SAViL-Det utilizes a pre-trained CLIP model combined with an Asymptotic Feature Pyramid Network (AFPN) for multi-scale visual feature fusion. The core of the proposed framework is a novel language-vision decoder that adaptively propagates fine-grained semantic information from text prompts to visual features via cross-modal attention. Furthermore, a text-to-pixel contrastive learning mechanism explicitly aligns textual and corresponding visual pixel features. Extensive experiments on challenging benchmarks demonstrate the effectiveness of the proposed approach, achieving state-of-the-art performance with F-scores of 84.8% on the benchmark multi-lingual MLT-2019 dataset and 90.2% on the curved-text CTW1500 dataset.
Recent Advances in Medical Imaging Segmentation: A Survey
May 14, 2025Medical imaging is a cornerstone of modern healthcare, driving advancements in diagnosis, treatment planning, and patient care. Among its various tasks, segmentation remains one of the most challenging problem due to factors such as data accessibility, annotation complexity, structural variability, variation in medical imaging modalities, and privacy constraints. Despite recent progress, achieving robust generalization and domain adaptation remains a significant hurdle, particularly given the resource-intensive nature of some proposed models and their reliance on domain expertise. This survey explores cutting-edge advancements in medical image segmentation, focusing on methodologies such as Generative AI, Few-Shot Learning, Foundation Models, and Universal Models. These approaches offer promising solutions to longstanding challenges. We provide a comprehensive overview of the theoretical foundations, state-of-the-art techniques, and recent applications of these methods. Finally, we discuss inherent limitations, unresolved issues, and future research directions aimed at enhancing the practicality and accessibility of segmentation models in medical imaging. We are maintaining a \href{https://github.com/faresbougourzi/Awesome-DL-for-Medical-Imaging-Segmentation}{GitHub Repository} to continue tracking and updating innovations in this field.
DeeCLIP: A Robust and Generalizable Transformer-Based Framework for Detecting AI-Generated Images
Apr 28, 2025This paper introduces DeeCLIP, a novel framework for detecting AI-generated images using CLIP-ViT and fusion learning. Despite significant advancements in generative models capable of creating highly photorealistic images, existing detection methods often struggle to generalize across different models and are highly sensitive to minor perturbations. To address these challenges, DeeCLIP incorporates DeeFuser, a fusion module that combines high-level and low-level features, improving robustness against degradations such as compression and blurring. Additionally, we apply triplet loss to refine the embedding space, enhancing the model's ability to distinguish between real and synthetic content. To further enable lightweight adaptation while preserving pre-trained knowledge, we adopt parameter-efficient fine-tuning using low-rank adaptation (LoRA) within the CLIP-ViT backbone. This approach supports effective zero-shot learning without sacrificing generalization. Trained exclusively on 4-class ProGAN data, DeeCLIP achieves an average accuracy of 89.00% on 19 test subsets composed of generative adversarial network (GAN) and diffusion models. Despite having fewer trainable parameters, DeeCLIP outperforms existing methods, demonstrating superior robustness against various generative models and real-world distortions. The code is publicly available at https://github.com/Mamadou-Keita/DeeCLIP for research purposes.
Shuffle Vision Transformer: Lightweight, Fast and Efficient Recognition of Driver Facial Expression
Sep 05, 2024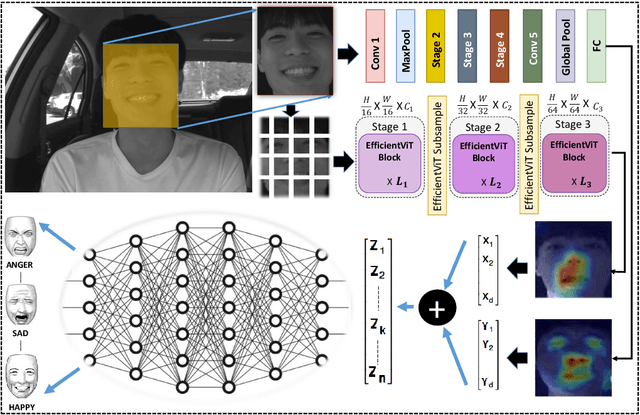

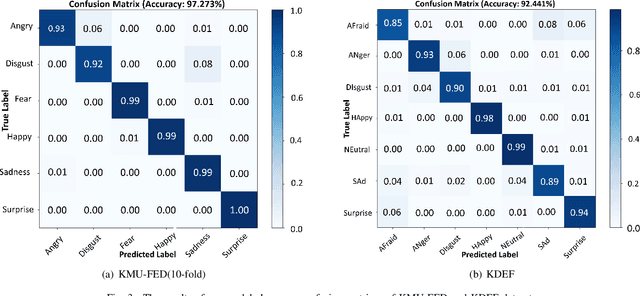

Existing methods for driver facial expression recognition (DFER) are often computationally intensive, rendering them unsuitable for real-time applications. In this work, we introduce a novel transfer learning-based dual architecture, named ShuffViT-DFER, which elegantly combines computational efficiency and accuracy. This is achieved by harnessing the strengths of two lightweight and efficient models using convolutional neural network (CNN) and vision transformers (ViT). We efficiently fuse the extracted features to enhance the performance of the model in accurately recognizing the facial expressions of the driver. Our experimental results on two benchmarking and public datasets, KMU-FED and KDEF, highlight the validity of our proposed method for real-time application with superior performance when compared to state-of-the-art methods.
TempoKGAT: A Novel Graph Attention Network Approach for Temporal Graph Analysis
Aug 29, 2024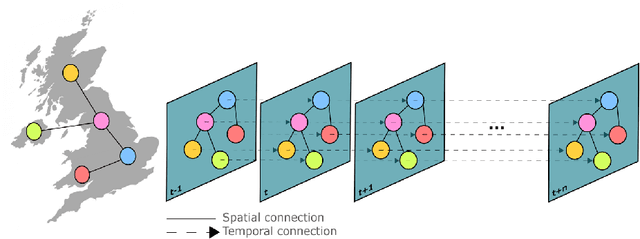

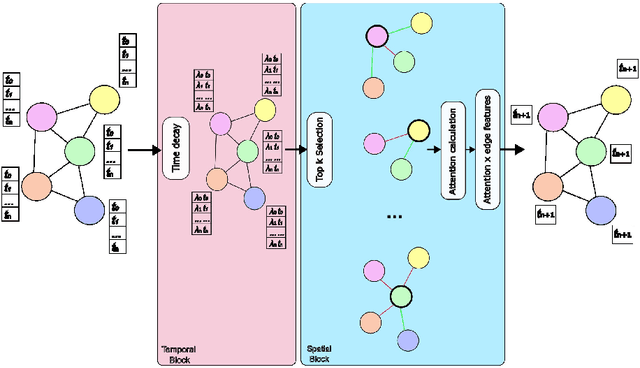
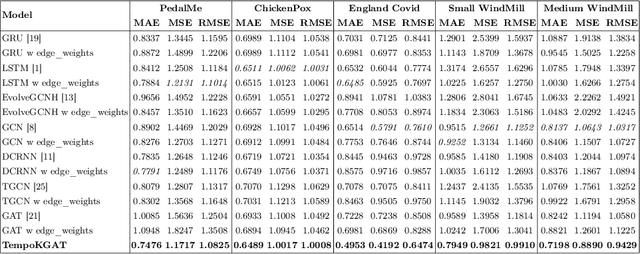
Graph neural networks (GNN) have shown significant capabilities in handling structured data, yet their application to dynamic, temporal data remains limited. This paper presents a new type of graph attention network, called TempoKGAT, which combines time-decaying weight and a selective neighbor aggregation mechanism on the spatial domain, which helps uncover latent patterns in the graph data. In this approach, a top-k neighbor selection based on the edge weights is introduced to represent the evolving features of the graph data. We evaluated the performance of our TempoKGAT on multiple datasets from the traffic, energy, and health sectors involving spatio-temporal data. We compared the performance of our approach to several state-of-the-art methods found in the literature on several open-source datasets. Our method shows superior accuracy on all datasets. These results indicate that TempoKGAT builds on existing methodologies to optimize prediction accuracy and provide new insights into model interpretation in temporal contexts.