 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Matters: Efficient Mamba-Based Decoder with Distribution-Aware Deep Supervision for Medical Image Segmentation
Mar 13, 2026Deep learning has achieved remarkable success in medical image segmentation, often reaching expert-level accuracy in delineating tumors and tissues. However, most existing approaches remain task-specific, showing strong performance on individual datasets but limited generalization across diverse imaging modalities. Moreover, many methods focus primarily on the encoder, relying on large pretrained backbones that increase computational complexity. In this paper, we propose a decoder-centric approach for generalized 2D medical image segmentation. The proposed Deco-Mamba follows a U-Net-like structure with a Transformer-CNN-Mamba design. The encoder combines a CNN block and Transformer backbone for efficient feature extraction, while the decoder integrates our novel Co-Attention Gate (CAG), Vision State Space Module (VSSM), and deformable convolutional refinement block to enhance multi-scale contextual representation. Additionally, a windowed distribution-aware KL-divergence loss is introduced for deep supervision across multiple decoding stages. Extensive experiments on diverse medical image segmentation benchmarks yield state-of-the-art performance and strong generalization capability while maintaining moderate model complexity. The source code will be released upon acceptance.
Lung Infection Severity Prediction Using Transformers with Conditional TransMix Augmentation and Cross-Attention
Oct 08, 2025



Lung infections, particularly pneumonia, pose serious health risks that can escalate rapidly, especially during pandemics. Accurate AI-based severity prediction from medical imaging is essential to support timely clinical decisions and optimize patient outcomes. In this work, we present a novel method applicable to both CT scans and chest X-rays for assessing lung infection severity. Our contributions are twofold: (i) QCross-Att-PVT, a Transformer-based architecture that integrates parallel encoders, a cross-gated attention mechanism, and a feature aggregator to capture rich multi-scale features; and (ii) Conditional Online TransMix, a custom data augmentation strategy designed to address dataset imbalance by generating mixed-label image patches during training. Evaluated on two benchmark datasets, RALO CXR and Per-COVID-19 CT, our method consistently outperforms several state-of-the-art deep learning models. The results emphasize the critical role of data augmentation and gated attention in improving both robustness and predictive accuracy. This approach offers a reliable, adaptable tool to support clinical diagnosis, disease monitoring, and personalized treatment planning. The source code of this work is available at https://github.com/bouthainas/QCross-Att-PVT.
Recent Advances in Medical Imaging Segmentation: A Survey
May 14, 2025Medical imaging is a cornerstone of modern healthcare, driving advancements in diagnosis, treatment planning, and patient care. Among its various tasks, segmentation remains one of the most challenging problem due to factors such as data accessibility, annotation complexity, structural variability, variation in medical imaging modalities, and privacy constraints. Despite recent progress, achieving robust generalization and domain adaptation remains a significant hurdle, particularly given the resource-intensive nature of some proposed models and their reliance on domain expertise. This survey explores cutting-edge advancements in medical image segmentation, focusing on methodologies such as Generative AI, Few-Shot Learning, Foundation Models, and Universal Models. These approaches offer promising solutions to longstanding challenges. We provide a comprehensive overview of the theoretical foundations, state-of-the-art techniques, and recent applications of these methods. Finally, we discuss inherent limitations, unresolved issues, and future research directions aimed at enhancing the practicality and accessibility of segmentation models in medical imaging. We are maintaining a \href{https://github.com/faresbougourzi/Awesome-DL-for-Medical-Imaging-Segmentation}{GitHub Repository} to continue tracking and updating innovations in this field.
Advancing Wheat Crop Analysis: A Survey of Deep Learning Approaches Using Hyperspectral Imaging
May 01, 2025As one of the most widely cultivated and consumed crops, wheat is essential to global food security. However, wheat production is increasingly challenged by pests, diseases, climate change, and water scarcity, threatening yields. Traditional crop monitoring methods are labor-intensive and often ineffective for early issue detection. Hyperspectral imaging (HSI) has emerged as a non-destructive and efficient technology for remote crop health assessment. However, the high dimensionality of HSI data and limited availability of labeled samples present notable challenges. In recent years, deep learning has shown great promise in addressing these challenges due to its ability to extract and analysis complex structures. Despite advancements in applying deep learning methods to HSI data for wheat crop analysis, no comprehensive survey currently exists in this field. This review addresses this gap by summarizing benchmark datasets, tracking advancements in deep learning methods, and analyzing key applications such as variety classification, disease detection, and yield estimation. It also highlights the strengths, limitations, and future opportunities in leveraging deep learning methods for HSI-based wheat crop analysis. We have listed the current state-of-the-art papers and will continue tracking updating them in the following https://github.com/fadi-07/Awesome-Wheat-HSI-DeepLearning.
Extremely Fine-Grained Visual Classification over Resembling Glyphs in the Wild
Aug 25, 2024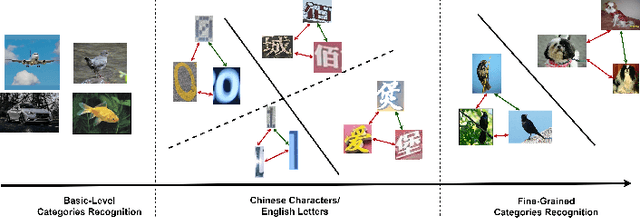

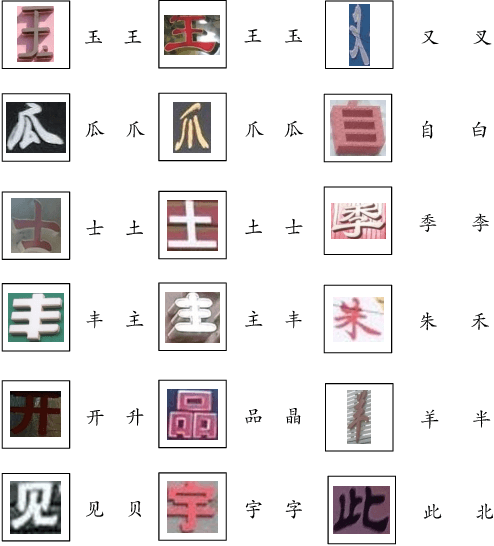
Text recognition in the wild is an important technique for digital maps and urban scene understanding, in which the natural resembling properties between glyphs is one of the major reasons that lead to wrong recognition results. To address this challenge, we introduce two extremely fine-grained visual recognition benchmark datasets that contain very challenging resembling glyphs (characters/letters) in the wild to be distinguished. Moreover, we propose a simple yet effective two-stage contrastive learning approach to the extremely fine-grained recognition task of resembling glyphs discrimination. In the first stage, we utilize supervised contrastive learning to leverage label information to warm-up the backbone network. In the second stage, we introduce CCFG-Net, a network architecture that integrates classification and contrastive learning in both Euclidean and Angular spaces, in which contrastive learning is applied in both supervised learning and pairwise discrimination manners to enhance the model's feature representation capability. Overall, our proposed approach effectively exploits the complementary strengths of contrastive learning and classification, leading to improved recognition performance on the resembling glyphs. Comparative evaluations with state-of-the-art fine-grained classification approaches under both Convolutional Neural Network (CNN) and Transformer backbones demonstrate the superiority of our proposed method.
Boosting Hyperspectral Image Classification with Gate-Shift-Fuse Mechanisms in a Novel CNN-Transformer Approach
Jun 20, 2024During the process of classifying Hyperspectral Image (HSI), every pixel sample is categorized under a land-cover type. CNN-based techniques for HSI classification have notably advanced the field by their adept feature representation capabilities. However, acquiring deep features remains a challenge for these CNN-based methods. In contrast, transformer models are adept at extracting high-level semantic features, offering a complementary strength. This paper's main contribution is the introduction of an HSI classification model that includes two convolutional blocks, a Gate-Shift-Fuse (GSF) block and a transformer block. This model leverages the strengths of CNNs in local feature extraction and transformers in long-range context modelling. The GSF block is designed to strengthen the extraction of local and global spatial-spectral features. An effective attention mechanism module is also proposed to enhance the extraction of information from HSI cubes. The proposed method is evaluated on four well-known datasets (the Indian Pines, Pavia University, WHU-WHU-Hi-LongKou and WHU-Hi-HanChuan), demonstrating that the proposed framework achieves superior results compared to other models.
D-TrAttUnet: Toward Hybrid CNN-Transformer Architecture for Generic and Subtle Segmentation in Medical Images
May 07, 2024



Over the past two decades, machine analysis of medical imaging has advanced rapidly, opening up significant potential for several important medical applications. As complicated diseases increase and the number of cases rises, the role of machine-based imaging analysis has become indispensable. It serves as both a tool and an assistant to medical experts, providing valuable insights and guidance. A particularly challenging task in this area is lesion segmentation, a task that is challenging even for experienced radiologists. The complexity of this task highlights the urgent need for robust machine learning approaches to support medical staff. In response, we present our novel solution: the D-TrAttUnet architecture. This framework is based on the observation that different diseases often target specific organs. Our architecture includes an encoder-decoder structure with a composite Transformer-CNN encoder and dual decoders. The encoder includes two paths: the Transformer path and the Encoders Fusion Module path. The Dual-Decoder configuration uses two identical decoders, each with attention gates. This allows the model to simultaneously segment lesions and organs and integrate their segmentation losses. To validate our approach, we performed evaluations on the Covid-19 and Bone Metastasis segmentation tasks. We also investigated the adaptability of the model by testing it without the second decoder in the segmentation of glands and nuclei. The results confirmed the superiority of our approach, especially in Covid-19 infections and the segmentation of bone metastases. In addition, the hybrid encoder showed exceptional performance in the segmentation of glands and nuclei, solidifying its role in modern medical image analysis.
Artificial Intelligence in Bone Metastasis Analysis: Current Advancements, Opportunities and Challenges
Apr 30, 2024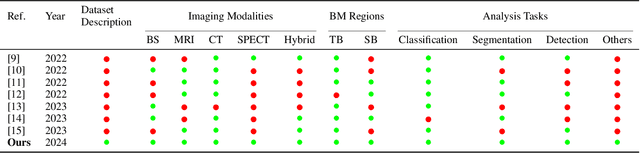
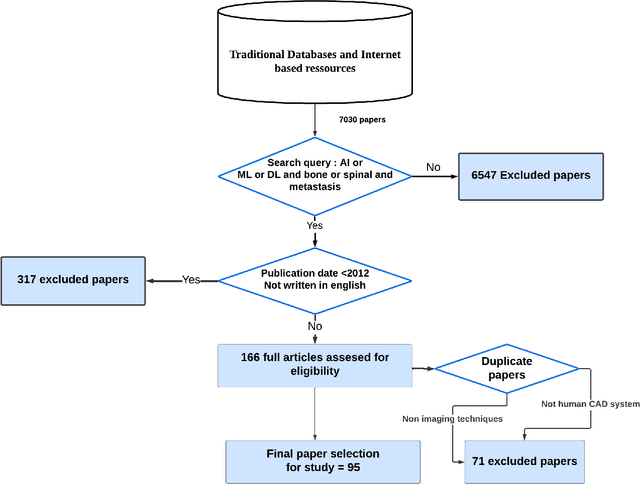
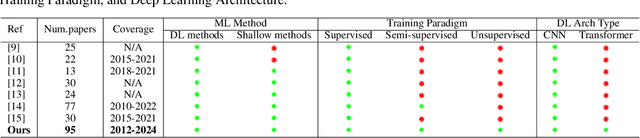
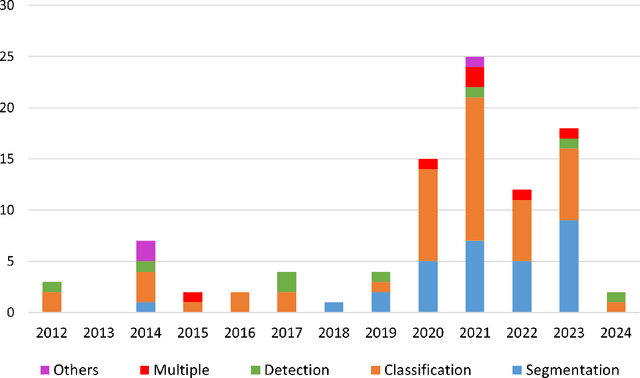
In recent years, Artificial Intelligence (AI) has been widely used in medicine, particularly in the analysis of medical imaging, which has been driven by advances in computer vision and deep learning methods. This is particularly important in overcoming the challenges posed by diseases such as Bone Metastases (BM), a common and complex malignancy of the bones. Indeed, there have been an increasing interest in developing Machine Learning (ML) techniques into oncologic imaging for BM analysis. In order to provide a comprehensive overview of the current state-of-the-art and advancements for BM analysis using artificial intelligence, this review is conducted with the accordance with PRISMA guidelines. Firstly, this review highlights the clinical and oncologic perspectives of BM and the used medical imaging modalities, with discussing their advantages and limitations. Then the review focuses on modern approaches with considering the main BM analysis tasks, which includes: classification, detection and segmentation. The results analysis show that ML technologies can achieve promising performance for BM analysis and have significant potential to improve clinician efficiency and cope with time and cost limitations. Furthermore, there are requirements for further research to validate the clinical performance of ML tools and facilitate their integration into routine clinical practice.
Rethinking Attention Gated with Hybrid Dual Pyramid Transformer-CNN for Generalized Segmentation in Medical Imaging
Apr 28, 2024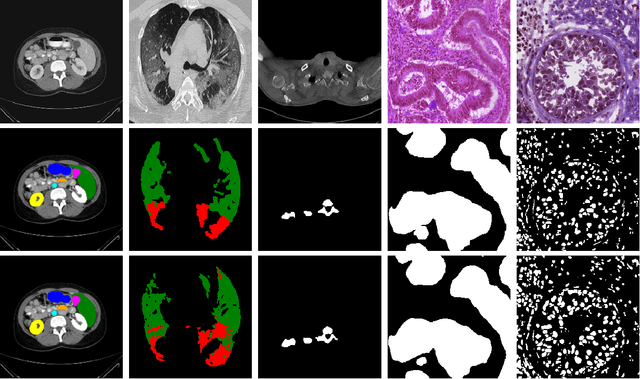
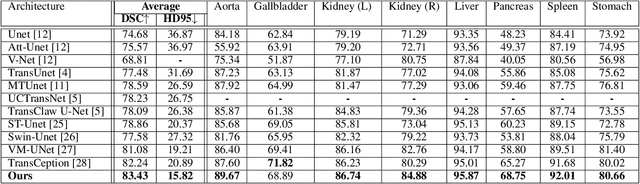
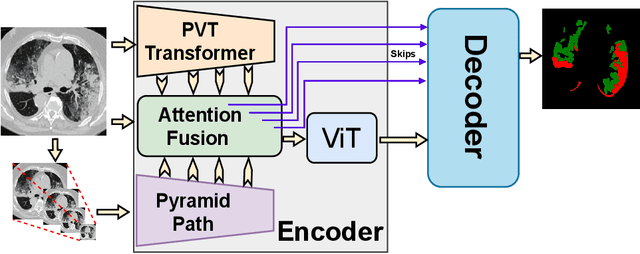
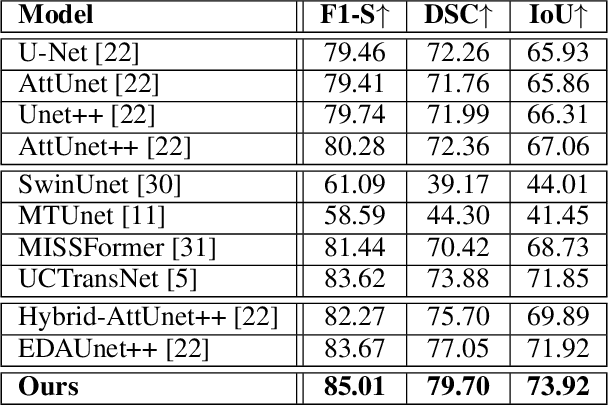
Inspired by the success of Transformers in Computer vision, Transformers have been widely investigated for medical imaging segmentation. However, most of Transformer architecture are using the recent transformer architectures as encoder or as parallel encoder with the CNN encoder. In this paper, we introduce a novel hybrid CNN-Transformer segmentation architecture (PAG-TransYnet) designed for efficiently building a strong CNN-Transformer encoder. Our approach exploits attention gates within a Dual Pyramid hybrid encoder. The contributions of this methodology can be summarized into three key aspects: (i) the utilization of Pyramid input for highlighting the prominent features at different scales, (ii) the incorporation of a PVT transformer to capture long-range dependencies across various resolutions, and (iii) the implementation of a Dual-Attention Gate mechanism for effectively fusing prominent features from both CNN and Transformer branches. Through comprehensive evaluation across different segmentation tasks including: abdominal multi-organs segmentation, infection segmentation (Covid-19 and Bone Metastasis), microscopic tissues segmentation (Gland and Nucleus). The proposed approach demonstrates state-of-the-art performance and exhibits remarkable generalization capabilities. This research represents a significant advancement towards addressing the pressing need for efficient and adaptable segmentation solutions in medical imaging applications.
Ensembling and Test Augmentation for Covid-19 Detection and Covid-19 Domain Adaptation from 3D CT-Scans
Mar 17, 2024



Since the emergence of Covid-19 in late 2019, medical image analysis using artificial intelligence (AI) has emerged as a crucial research area, particularly with the utility of CT-scan imaging for disease diagnosis. This paper contributes to the 4th COV19D competition, focusing on Covid-19 Detection and Covid-19 Domain Adaptation Challenges. Our approach centers on lung segmentation and Covid-19 infection segmentation employing the recent CNN-based segmentation architecture PDAtt-Unet, which simultaneously segments lung regions and infections. Departing from traditional methods, we concatenate the input slice (grayscale) with segmented lung and infection, generating three input channels akin to color channels. Additionally, we employ three 3D CNN backbones Customized Hybrid-DeCoVNet, along with pretrained 3D-Resnet-18 and 3D-Resnet-50 models to train Covid-19 recognition for both challenges. Furthermore, we explore ensemble approaches and testing augmentation to enhance performance. Comparison with baseline results underscores the substantial efficiency of our approach, with a significant margin in terms of F1-score (14 %). This study advances the field by presenting a comprehensive methodology for accurate Covid-19 detection and adaptation, leveraging cutting-edge AI techniques in medical image analysis.