 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLung Infection Severity Prediction Using Transformers with Conditional TransMix Augmentation and Cross-Attention
Oct 08, 2025



Lung infections, particularly pneumonia, pose serious health risks that can escalate rapidly, especially during pandemics. Accurate AI-based severity prediction from medical imaging is essential to support timely clinical decisions and optimize patient outcomes. In this work, we present a novel method applicable to both CT scans and chest X-rays for assessing lung infection severity. Our contributions are twofold: (i) QCross-Att-PVT, a Transformer-based architecture that integrates parallel encoders, a cross-gated attention mechanism, and a feature aggregator to capture rich multi-scale features; and (ii) Conditional Online TransMix, a custom data augmentation strategy designed to address dataset imbalance by generating mixed-label image patches during training. Evaluated on two benchmark datasets, RALO CXR and Per-COVID-19 CT, our method consistently outperforms several state-of-the-art deep learning models. The results emphasize the critical role of data augmentation and gated attention in improving both robustness and predictive accuracy. This approach offers a reliable, adaptable tool to support clinical diagnosis, disease monitoring, and personalized treatment planning. The source code of this work is available at https://github.com/bouthainas/QCross-Att-PVT.
SHREC 2025: Protein surface shape retrieval including electrostatic potential
Sep 16, 2025



This SHREC 2025 track dedicated to protein surface shape retrieval involved 9 participating teams. We evaluated the performance in retrieval of 15 proposed methods on a large dataset of 11,555 protein surfaces with calculated electrostatic potential (a key molecular surface descriptor). The performance in retrieval of the proposed methods was evaluated through different metrics (Accuracy, Balanced accuracy, F1 score, Precision and Recall). The best retrieval performance was achieved by the proposed methods that used the electrostatic potential complementary to molecular surface shape. This observation was also valid for classes with limited data which highlights the importance of taking into account additional molecular surface descriptors.
* Published in Computers & Graphics, Elsevier. 59 pages, 12 figures
Vision Transformer-based Model for Severity Quantification of Lung Pneumonia Using Chest X-ray Images
Mar 18, 2023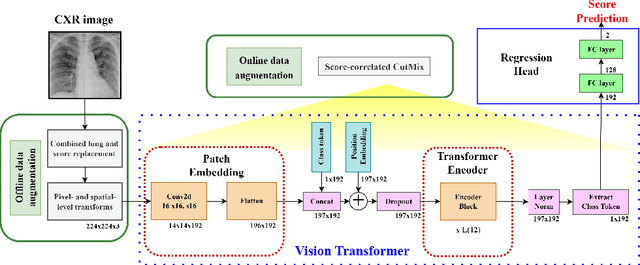



To develop generic and reliable approaches for diagnosing and assessing the severity of COVID-19 from chest X-rays (CXR), a large number of well-maintained COVID-19 datasets are needed. Existing severity quantification architectures require expensive training calculations to achieve the best results. For healthcare professionals to quickly and automatically identify COVID-19 patients and predict associated severity indicators, computer utilities are needed. In this work, we propose a Vision Transformer (ViT)-based neural network model that relies on a small number of trainable parameters to quantify the severity of COVID-19 and other lung diseases. We present a feasible approach to quantify the severity of CXR, called Vision Transformer Regressor Infection Prediction (ViTReg-IP), derived from a ViT and a regression head. We investigate the generalization potential of our model using a variety of additional test chest radiograph datasets from different open sources. In this context, we performed a comparative study with several competing deep learning analysis methods. The experimental results show that our model can provide peak performance in quantifying severity with high generalizability at a relatively low computational cost. The source codes used in our work are publicly available at https://github.com/bouthainas/ViTReg-IP.
SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix Data Augmentation
Apr 11, 2022
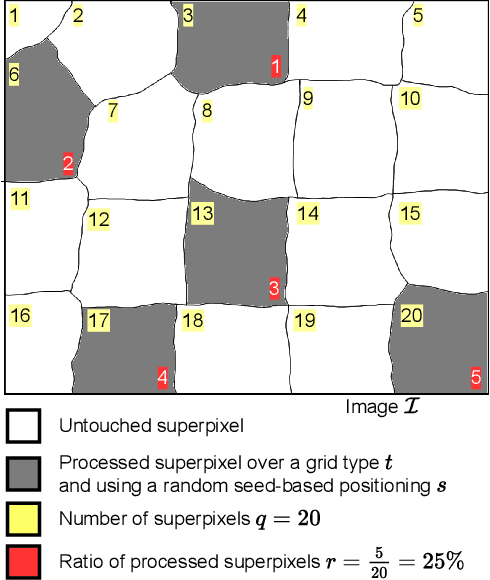

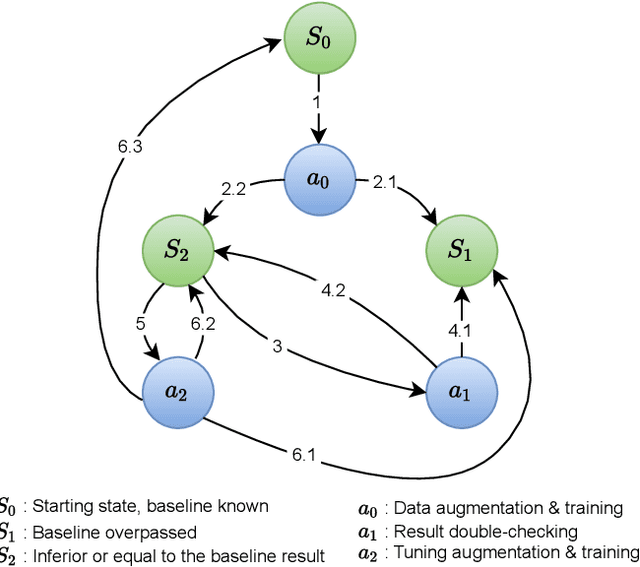
A novel approach of data augmentation based on irregular superpixel decomposition is proposed. This approach called SuperpixelGridMasks permits to extend original image datasets that are required by training stages of machine learning-related analysis architectures towards increasing their performances. Three variants named SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix are presented. These grid-based methods produce a new style of image transformations using the dropping and fusing of information. Extensive experiments using various image classification models and datasets show that baseline performances can be significantly outperformed using our methods. The comparative study also shows that our methods can overpass the performances of other data augmentations. Experimental results obtained over image recognition datasets of varied natures show the efficiency of these new methods. SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix codes are publicly available at https://github.com/hammoudiproject/SuperpixelGridMasks
MaskedFace-Net -- A Dataset of Correctly/Incorrectly Masked Face Images in the Context of COVID-19
Aug 18, 2020
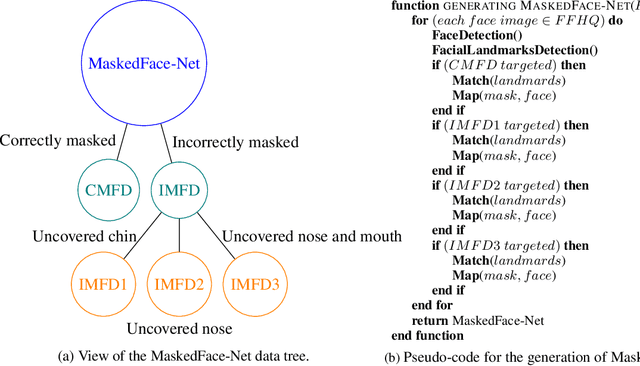

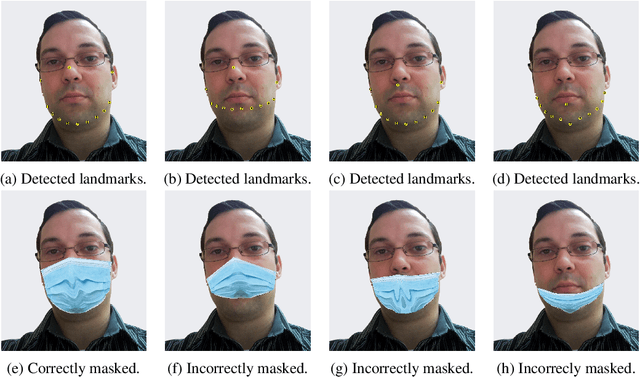
The wearing of the face masks appears as a solution for limiting the spread of COVID-19. In this context, efficient recognition systems are expected for checking that people faces are masked in regulated areas. To perform this task, a large dataset of masked faces is necessary for training deep learning models towards detecting people wearing masks and those not wearing masks. Some large datasets of masked faces are available in the literature. However, at the moment, there are no available large dataset of masked face images that permits to check if detected masked faces are correctly worn or not. Indeed, many people are not correctly wearing their masks due to bad practices, bad behaviors or vulnerability of individuals (e.g., children, old people). For these reasons, several mask wearing campaigns intend to sensitize people about this problem and good practices. In this sense, this work proposes three types of masked face detection dataset; namely, the Correctly Masked Face Dataset (CMFD), the Incorrectly Masked Face Dataset (IMFD) and their combination for the global masked face detection (MaskedFace-Net). Realistic masked face datasets are proposed with a twofold objective: i) to detect people having their faces masked or not masked, ii) to detect faces having their masks correctly worn or incorrectly worn (e.g.; at airport portals or in crowds). To the best of our knowledge, no large dataset of masked faces provides such a granularity of classification towards permitting mask wearing analysis. Moreover, this work globally presents the applied mask-to-face deformable model for permitting the generation of other masked face images, notably with specific masks. Our datasets of masked face images (137,016 images) are available at https://github.com/cabani/MaskedFace-Net.
Deep Learning on Chest X-ray Images to Detect and Evaluate Pneumonia Cases at the Era of COVID-19
Apr 05, 2020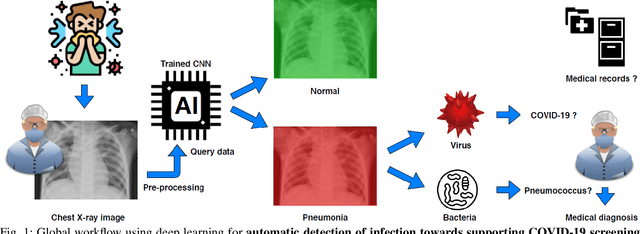
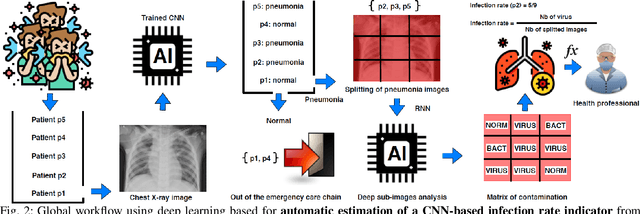
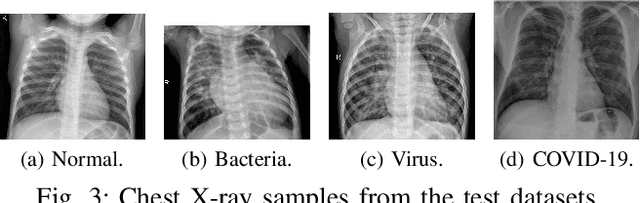
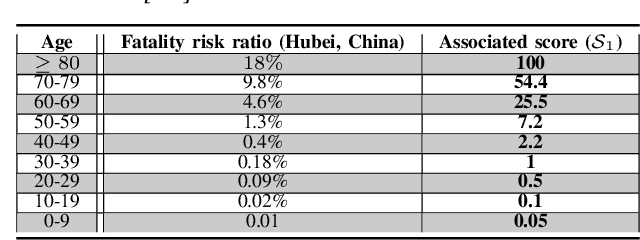
Coronavirus disease 2019 (COVID-19) is an infectious disease with first symptoms similar to the flu. COVID-19 appeared first in China and very quickly spreads to the rest of the world, causing then the 2019-20 coronavirus pandemic. In many cases, this disease causes pneumonia. Since pulmonary infections can be observed through radiography images, this paper investigates deep learning methods for automatically analyzing query chest X-ray images with the hope to bring precision tools to health professionals towards screening the COVID-19 and diagnosing confirmed patients. In this context, training datasets, deep learning architectures and analysis strategies have been experimented from publicly open sets of chest X-ray images. Tailored deep learning models are proposed to detect pneumonia infection cases, notably viral cases. It is assumed that viral pneumonia cases detected during an epidemic COVID-19 context have a high probability to presume COVID-19 infections. Moreover, easy-to-apply health indicators are proposed for estimating infection status and predicting patient status from the detected pneumonia cases. Experimental results show possibilities of training deep learning models over publicly open sets of chest X-ray images towards screening viral pneumonia. Chest X-ray test images of COVID-19 infected patients are successfully diagnosed through detection models retained for their performances. The efficiency of proposed health indicators is highlighted through simulated scenarios of patients presenting infections and health problems by combining real and synthetic health data.
Design, Implementation and Simulation of a Cloud Computing System for Enhancing Real-time Video Services by using VANET and Onboard Navigation Systems
Nov 25, 2014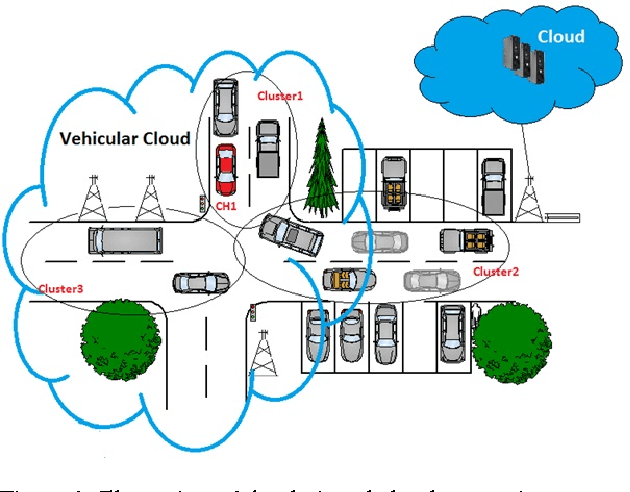

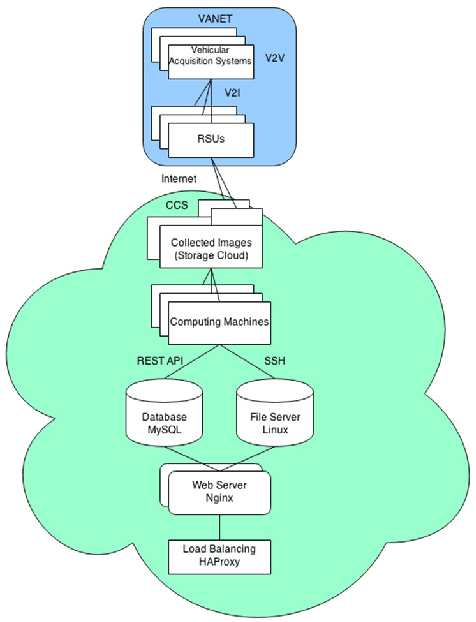
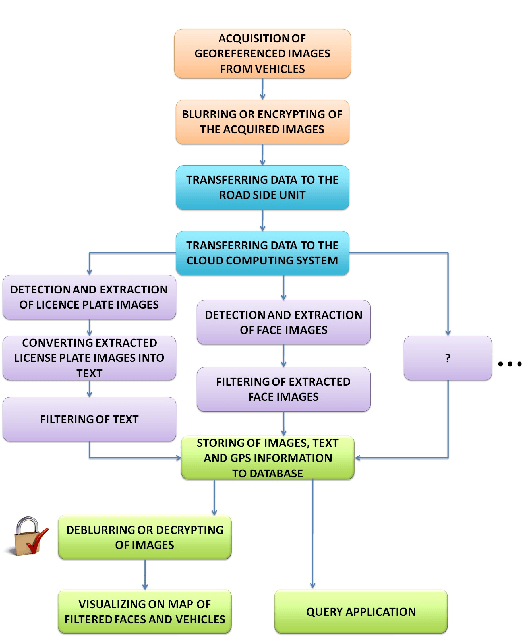
In this paper, we propose a design for novel and experimental cloud computing systems. The proposed system aims at enhancing computational, communicational and annalistic capabilities of road navigation services by merging several independent technologies, namely vision-based embedded navigation systems, prominent Cloud Computing Systems (CCSs) and Vehicular Ad-hoc NETwork (VANET). This work presents our initial investigations by describing the design of a global generic system. The designed system has been experimented with various scenarios of video-based road services. Moreover, the associated architecture has been implemented on a small-scale simulator of an in-vehicle embedded system. The implemented architecture has been experimented in the case of a simulated road service to aid the police agency. The goal of this service is to recognize and track searched individuals and vehicles in a real-time monitoring system remotely connected to moving cars. The presented work demonstrates the potential of our system for efficiently enhancing and diversifying real-time video services in road environments.
A Synergistic Approach for Recovering Occlusion-Free Textured 3D Maps of Urban Facades from Heterogeneous Cartographic Data
Aug 29, 2013
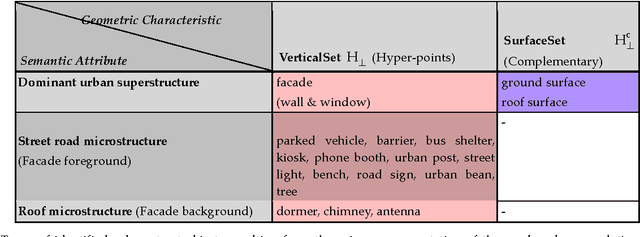
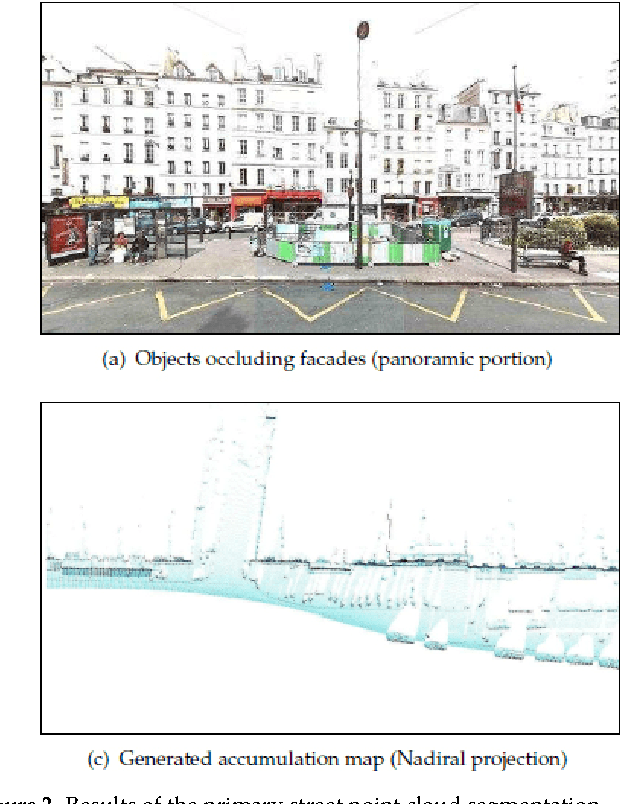
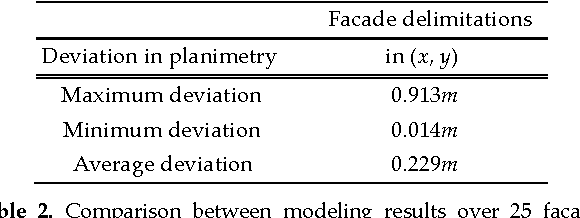
In this paper we present a practical approach for generating an occlusion-free textured 3D map of urban facades by the synergistic use of terrestrial images, 3D point clouds and area-based information. Particularly in dense urban environments, the high presence of urban objects in front of the facades causes significant difficulties for several stages in computational building modeling. Major challenges lie on the one hand in extracting complete 3D facade quadrilateral delimitations and on the other hand in generating occlusion-free facade textures. For these reasons, we describe a straightforward approach for completing and recovering facade geometry and textures by exploiting the data complementarity of terrestrial multi-source imagery and area-based information.