 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-PAR: A Vision Language Model for Pedestrian Attribute Recognition
Dec 22, 2025Pedestrian Attribute Recognition (PAR) involves predicting fine-grained attributes such as clothing color, gender, and accessories from pedestrian imagery, yet is hindered by severe class imbalance, intricate attribute co-dependencies, and domain shifts. We introduce VLM-PAR, a modular vision-language framework built on frozen SigLIP 2 multilingual encoders. By first aligning image and prompt embeddings via refining visual features through a compact cross-attention fusion, VLM-PAR achieves significant accuracy improvement on the highly imbalanced PA100K benchmark, setting a new state-of-the-art performance, while also delivering significant gains in mean accuracy across PETA and Market-1501 benchmarks. These results underscore the efficacy of integrating large-scale vision-language pretraining with targeted cross-modal refinement to overcome imbalance and generalization challenges in PAR.
SCS-SupCon: Sigmoid-based Common and Style Supervised Contrastive Learning with Adaptive Decision Boundaries
Dec 17, 2025Image classification is hindered by subtle inter-class differences and substantial intra-class variations, which limit the effectiveness of existing contrastive learning methods. Supervised contrastive approaches based on the InfoNCE loss suffer from negative-sample dilution and lack adaptive decision boundaries, thereby reducing discriminative power in fine-grained recognition tasks. To address these limitations, we propose Sigmoid-based Common and Style Supervised Contrastive Learning (SCS-SupCon). Our framework introduces a sigmoid-based pairwise contrastive loss with learnable temperature and bias parameters to enable adaptive decision boundaries. This formulation emphasizes hard negatives, mitigates negative-sample dilution, and more effectively exploits supervision. In addition, an explicit style-distance constraint further disentangles style and content representations, leading to more robust feature learning. Comprehensive experiments on six benchmark datasets, including CUB200-2011 and Stanford Dogs, demonstrate that SCS-SupCon achieves state-of-the-art performance across both CNN and Transformer backbones. On CIFAR-100 with ResNet-50, SCS-SupCon improves top-1 accuracy over SupCon by approximately 3.9 percentage points and over CS-SupCon by approximately 1.7 points under five-fold cross-validation. On fine-grained datasets, it outperforms CS-SupCon by 0.4--3.0 points. Extensive ablation studies and statistical analyses further confirm the robustness and generalization of the proposed framework, with Friedman tests and Nemenyi post-hoc evaluations validating the stability of the observed improvements.
Enhancing Semi-Supervised Multi-View Graph Convolutional Networks via Supervised Contrastive Learning and Self-Training
Dec 15, 2025



The advent of graph convolutional network (GCN)-based multi-view learning provides a powerful framework for integrating structural information from heterogeneous views, enabling effective modeling of complex multi-view data. However, existing methods often fail to fully exploit the complementary information across views, leading to suboptimal feature representations and limited performance. To address this, we propose MV-SupGCN, a semi-supervised GCN model that integrates several complementary components with clear motivations and mutual reinforcement. First, to better capture discriminative features and improve model generalization, we design a joint loss function that combines Cross-Entropy loss with Supervised Contrastive loss, encouraging the model to simultaneously minimize intra-class variance and maximize inter-class separability in the latent space. Second, recognizing the instability and incompleteness of single graph construction methods, we combine both KNN-based and semi-supervised graph construction approaches on each view, thereby enhancing the robustness of the data structure representation and reducing generalization error. Third, to effectively utilize abundant unlabeled data and enhance semantic alignment across multiple views, we propose a unified framework that integrates contrastive learning in order to enforce consistency among multi-view embeddings and capture meaningful inter-view relationships, together with pseudo-labeling, which provides additional supervision applied to both the cross-entropy and contrastive loss functions to enhance model generalization. Extensive experiments demonstrate that MV-SupGCN consistently surpasses state-of-the-art methods across multiple benchmarks, validating the effectiveness of our integrated approach. The source code is available at https://github.com/HuaiyuanXiao/MVSupGCN
Lung Infection Severity Prediction Using Transformers with Conditional TransMix Augmentation and Cross-Attention
Oct 08, 2025Lung infections, particularly pneumonia, pose serious health risks that can escalate rapidly, especially during pandemics. Accurate AI-based severity prediction from medical imaging is essential to support timely clinical decisions and optimize patient outcomes. In this work, we present a novel method applicable to both CT scans and chest X-rays for assessing lung infection severity. Our contributions are twofold: (i) QCross-Att-PVT, a Transformer-based architecture that integrates parallel encoders, a cross-gated attention mechanism, and a feature aggregator to capture rich multi-scale features; and (ii) Conditional Online TransMix, a custom data augmentation strategy designed to address dataset imbalance by generating mixed-label image patches during training. Evaluated on two benchmark datasets, RALO CXR and Per-COVID-19 CT, our method consistently outperforms several state-of-the-art deep learning models. The results emphasize the critical role of data augmentation and gated attention in improving both robustness and predictive accuracy. This approach offers a reliable, adaptable tool to support clinical diagnosis, disease monitoring, and personalized treatment planning. The source code of this work is available at https://github.com/bouthainas/QCross-Att-PVT.
Edge Artificial Intelligence: A Systematic Review of Evolution, Taxonomic Frameworks, and Future Horizons
Oct 01, 2025Edge Artificial Intelligence (Edge AI) embeds intelligence directly into devices at the network edge, enabling real-time processing with improved privacy and reduced latency by processing data close to its source. This review systematically examines the evolution, current landscape, and future directions of Edge AI through a multi-dimensional taxonomy including deployment location, processing capabilities such as TinyML and federated learning, application domains, and hardware types. Following PRISMA guidelines, the analysis traces the field from early content delivery networks and fog computing to modern on-device intelligence. Core enabling technologies such as specialized hardware accelerators, optimized software, and communication protocols are explored. Challenges including resource limitations, security, model management, power consumption, and connectivity are critically assessed. Emerging opportunities in neuromorphic hardware, continual learning algorithms, edge-cloud collaboration, and trustworthiness integration are highlighted, providing a comprehensive framework for researchers and practitioners.
Extremely Fine-Grained Visual Classification over Resembling Glyphs in the Wild
Aug 25, 2024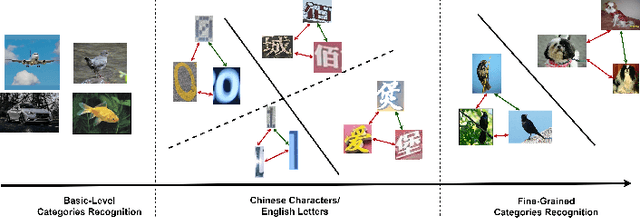

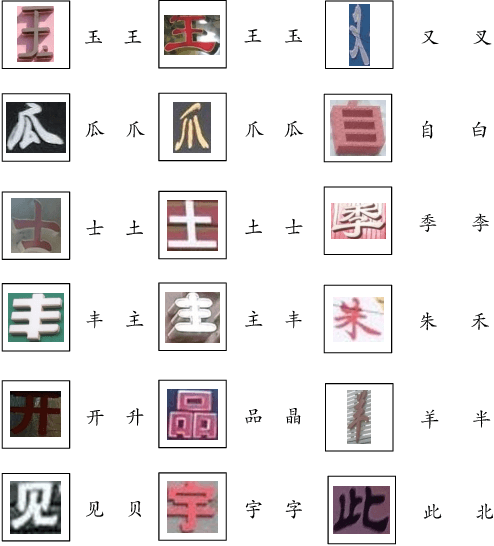
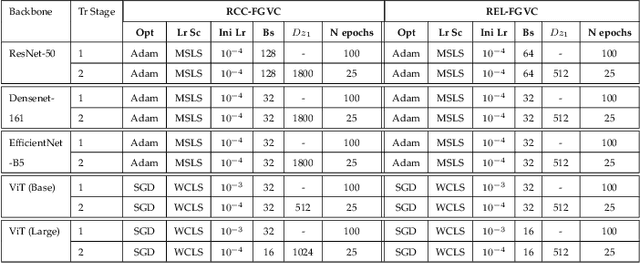
Text recognition in the wild is an important technique for digital maps and urban scene understanding, in which the natural resembling properties between glyphs is one of the major reasons that lead to wrong recognition results. To address this challenge, we introduce two extremely fine-grained visual recognition benchmark datasets that contain very challenging resembling glyphs (characters/letters) in the wild to be distinguished. Moreover, we propose a simple yet effective two-stage contrastive learning approach to the extremely fine-grained recognition task of resembling glyphs discrimination. In the first stage, we utilize supervised contrastive learning to leverage label information to warm-up the backbone network. In the second stage, we introduce CCFG-Net, a network architecture that integrates classification and contrastive learning in both Euclidean and Angular spaces, in which contrastive learning is applied in both supervised learning and pairwise discrimination manners to enhance the model's feature representation capability. Overall, our proposed approach effectively exploits the complementary strengths of contrastive learning and classification, leading to improved recognition performance on the resembling glyphs. Comparative evaluations with state-of-the-art fine-grained classification approaches under both Convolutional Neural Network (CNN) and Transformer backbones demonstrate the superiority of our proposed method.
D-TrAttUnet: Toward Hybrid CNN-Transformer Architecture for Generic and Subtle Segmentation in Medical Images
May 07, 2024



Over the past two decades, machine analysis of medical imaging has advanced rapidly, opening up significant potential for several important medical applications. As complicated diseases increase and the number of cases rises, the role of machine-based imaging analysis has become indispensable. It serves as both a tool and an assistant to medical experts, providing valuable insights and guidance. A particularly challenging task in this area is lesion segmentation, a task that is challenging even for experienced radiologists. The complexity of this task highlights the urgent need for robust machine learning approaches to support medical staff. In response, we present our novel solution: the D-TrAttUnet architecture. This framework is based on the observation that different diseases often target specific organs. Our architecture includes an encoder-decoder structure with a composite Transformer-CNN encoder and dual decoders. The encoder includes two paths: the Transformer path and the Encoders Fusion Module path. The Dual-Decoder configuration uses two identical decoders, each with attention gates. This allows the model to simultaneously segment lesions and organs and integrate their segmentation losses. To validate our approach, we performed evaluations on the Covid-19 and Bone Metastasis segmentation tasks. We also investigated the adaptability of the model by testing it without the second decoder in the segmentation of glands and nuclei. The results confirmed the superiority of our approach, especially in Covid-19 infections and the segmentation of bone metastases. In addition, the hybrid encoder showed exceptional performance in the segmentation of glands and nuclei, solidifying its role in modern medical image analysis.
Artificial Intelligence in Bone Metastasis Analysis: Current Advancements, Opportunities and Challenges
Apr 30, 2024
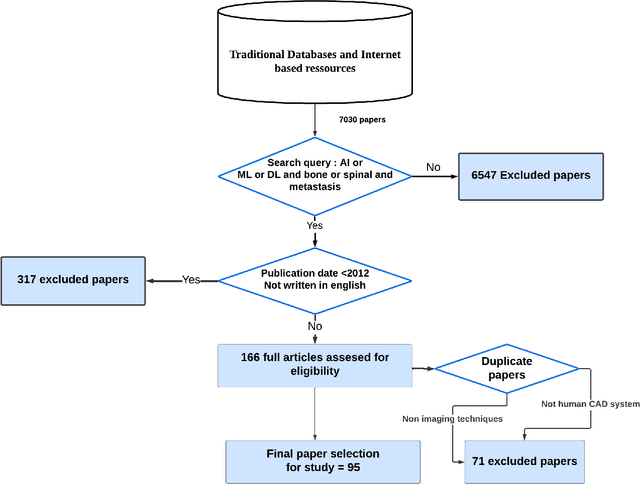
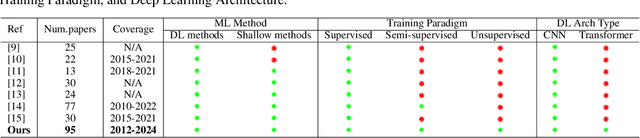
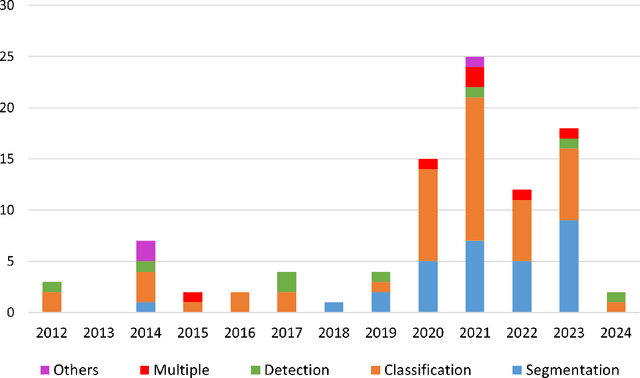
In recent years, Artificial Intelligence (AI) has been widely used in medicine, particularly in the analysis of medical imaging, which has been driven by advances in computer vision and deep learning methods. This is particularly important in overcoming the challenges posed by diseases such as Bone Metastases (BM), a common and complex malignancy of the bones. Indeed, there have been an increasing interest in developing Machine Learning (ML) techniques into oncologic imaging for BM analysis. In order to provide a comprehensive overview of the current state-of-the-art and advancements for BM analysis using artificial intelligence, this review is conducted with the accordance with PRISMA guidelines. Firstly, this review highlights the clinical and oncologic perspectives of BM and the used medical imaging modalities, with discussing their advantages and limitations. Then the review focuses on modern approaches with considering the main BM analysis tasks, which includes: classification, detection and segmentation. The results analysis show that ML technologies can achieve promising performance for BM analysis and have significant potential to improve clinician efficiency and cope with time and cost limitations. Furthermore, there are requirements for further research to validate the clinical performance of ML tools and facilitate their integration into routine clinical practice.
Rethinking Attention Gated with Hybrid Dual Pyramid Transformer-CNN for Generalized Segmentation in Medical Imaging
Apr 28, 2024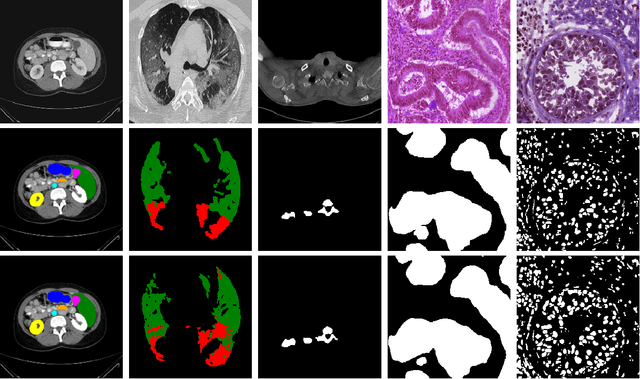
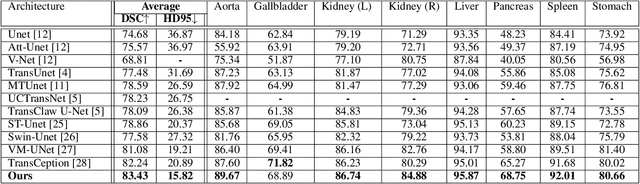
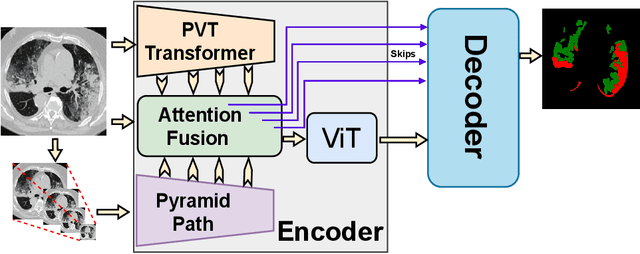
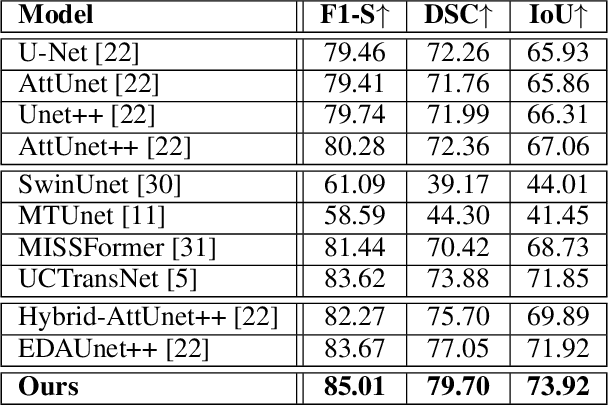
Inspired by the success of Transformers in Computer vision, Transformers have been widely investigated for medical imaging segmentation. However, most of Transformer architecture are using the recent transformer architectures as encoder or as parallel encoder with the CNN encoder. In this paper, we introduce a novel hybrid CNN-Transformer segmentation architecture (PAG-TransYnet) designed for efficiently building a strong CNN-Transformer encoder. Our approach exploits attention gates within a Dual Pyramid hybrid encoder. The contributions of this methodology can be summarized into three key aspects: (i) the utilization of Pyramid input for highlighting the prominent features at different scales, (ii) the incorporation of a PVT transformer to capture long-range dependencies across various resolutions, and (iii) the implementation of a Dual-Attention Gate mechanism for effectively fusing prominent features from both CNN and Transformer branches. Through comprehensive evaluation across different segmentation tasks including: abdominal multi-organs segmentation, infection segmentation (Covid-19 and Bone Metastasis), microscopic tissues segmentation (Gland and Nucleus). The proposed approach demonstrates state-of-the-art performance and exhibits remarkable generalization capabilities. This research represents a significant advancement towards addressing the pressing need for efficient and adaptable segmentation solutions in medical imaging applications.
Fair Graph Neural Network with Supervised Contrastive Regularization
Apr 09, 2024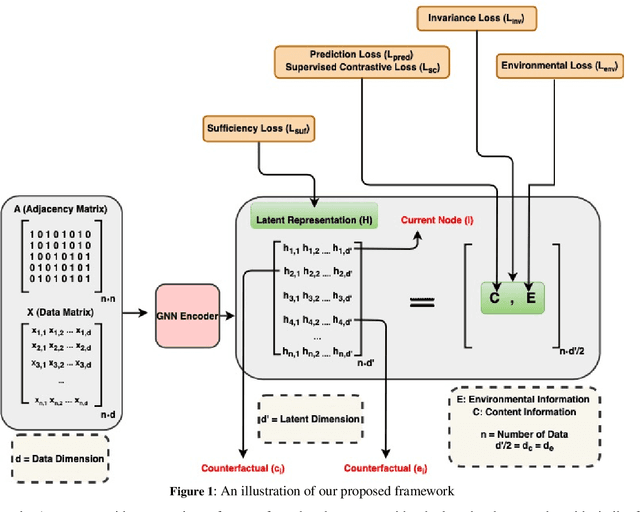


In recent years, Graph Neural Networks (GNNs) have made significant advancements, particularly in tasks such as node classification, link prediction, and graph representation. However, challenges arise from biases that can be hidden not only in the node attributes but also in the connections between entities. Therefore, ensuring fairness in graph neural network learning has become a critical problem. To address this issue, we propose a novel model for training fairness-aware GNN, which enhances the Counterfactual Augmented Fair Graph Neural Network Framework (CAF). Our approach integrates Supervised Contrastive Loss and Environmental Loss to enhance both accuracy and fairness. Experimental validation on three real datasets demonstrates the superiority of our proposed model over CAF and several other existing graph-based learning methods.