 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Cultural Signals in Large Language Models through Author Profiling
Mar 17, 2026Large language models (LLMs) are increasingly deployed in applications with societal impact, raising concerns about the cultural biases they encode. We probe these representations by evaluating whether LLMs can perform author profiling from song lyrics in a zero-shot setting, inferring singers' gender and ethnicity without task-specific fine-tuning. Across several open-source models evaluated on more than 10,000 lyrics, we find that LLMs achieve non-trivial profiling performance but demonstrate systematic cultural alignment: most models default toward North American ethnicity, while DeepSeek-1.5B aligns more strongly with Asian ethnicity. This finding emerges from both the models' prediction distributions and an analysis of their generated rationales. To quantify these disparities, we introduce two fairness metrics, Modality Accuracy Divergence (MAD) and Recall Divergence (RD), and show that Ministral-8B displays the strongest ethnicity bias among the evaluated models, whereas Gemma-12B shows the most balanced behavior. Our code is available on GitHub (https://github.com/ValentinLafargue/CulturalProbingLLM).
Evaluating Black-Box Vulnerabilities with Wasserstein-Constrained Data Perturbations
Mar 16, 2026The massive use of Machine Learning (ML) tools in industry comes with critical challenges, such as the lack of explainable models and the use of black-box algorithms. We address this issue by applying Optimal Transport theory in the analysis of responses of ML models to variations in the distribution of input variables. We find the closest distribution, in the Wasserstein sense, that satisfies a given constraintt and examine its impact on model behavior. Furthermore, we establish convergence results for this projected distribution and demonstrate our approach using examples and real-world datasets in both regression and classification settings.
Exact Functional ANOVA Decomposition for Categorical Inputs Models
Mar 03, 2026Functional ANOVA offers a principled framework for interpretability by decomposing a model's prediction into main effects and higher-order interactions. For independent features, this decomposition is well-defined, strongly linked with SHAP values, and serves as a cornerstone of additive explainability. However, the lack of an explicit closed-form expression for general dependent distributions has forced practitioners to rely on costly sampling-based approximations. We completely resolve this limitation for categorical inputs. By bridging functional analysis with the extension of discrete Fourier analysis, we derive a closed-form decomposition without any assumption. Our formulation is computationally very efficient. It seamlessly recovers the classical independent case and extends to arbitrary dependence structures, including distributions with non-rectangular support. Furthermore, leveraging the intrinsic link between SHAP and ANOVA under independence, our framework yields a natural generalization of SHAP values for the general categorical setting.
Token-Efficient Change Detection in LLM APIs
Feb 11, 2026Remote change detection in LLMs is a difficult problem. Existing methods are either too expensive for deployment at scale, or require initial white-box access to model weights or grey-box access to log probabilities. We aim to achieve both low cost and strict black-box operation, observing only output tokens. Our approach hinges on specific inputs we call Border Inputs, for which there exists more than one output top token. From a statistical perspective, optimal change detection depends on the model's Jacobian and the Fisher information of the output distribution. Analyzing these quantities in low-temperature regimes shows that border inputs enable powerful change detection tests. Building on this insight, we propose the Black-Box Border Input Tracking (B3IT) scheme. Extensive in-vivo and in-vitro experiments show that border inputs are easily found for non-reasoning tested endpoints, and achieve performance on par with the best available grey-box approaches. B3IT reduces costs by $30\times$ compared to existing methods, while operating in a strict black-box setting.
Explaining Models under Multivariate Bernoulli Distribution via Hoeffding Decomposition
Oct 08, 2025



Explaining the behavior of predictive models with random inputs can be achieved through sub-models decomposition, where such sub-models have easier interpretable features. Arising from the uncertainty quantification community, recent results have demonstrated the existence and uniqueness of a generalized Hoeffding decomposition for such predictive models when the stochastic input variables are correlated, based on concepts of oblique projection onto L 2 subspaces. This article focuses on the case where the input variables have Bernoulli distributions and provides a complete description of this decomposition. We show that in this case the underlying L 2 subspaces are one-dimensional and that the functional decomposition is explicit. This leads to a complete interpretability framework and theoretically allows reverse engineering. Explicit indicators of the influence of inputs on the output prediction (exemplified by Sobol' indices and Shapley effects) can be explicitly derived. Illustrated by numerical experiments, this type of analysis proves useful for addressing decision-support problems, based on binary decision diagrams, Boolean networks or binary neural networks. The article outlines perspectives for exploring high-dimensional settings and, beyond the case of binary inputs, extending these findings to models with finite countable inputs.
Exposing the Illusion of Fairness: Auditing Vulnerabilities to Distributional Manipulation Attacks
Jul 28, 2025Proving the compliance of AI algorithms has become an important challenge with the growing deployment of such algorithms for real-life applications. Inspecting possible biased behaviors is mandatory to satisfy the constraints of the regulations of the EU Artificial Intelligence's Act. Regulation-driven audits increasingly rely on global fairness metrics, with Disparate Impact being the most widely used. Yet such global measures depend highly on the distribution of the sample on which the measures are computed. We investigate first how to manipulate data samples to artificially satisfy fairness criteria, creating minimally perturbed datasets that remain statistically indistinguishable from the original distribution while satisfying prescribed fairness constraints. Then we study how to detect such manipulation. Our analysis (i) introduces mathematically sound methods for modifying empirical distributions under fairness constraints using entropic or optimal transport projections, (ii) examines how an auditee could potentially circumvent fairness inspections, and (iii) offers recommendations to help auditors detect such data manipulations. These results are validated through experiments on classical tabular datasets in bias detection.
When majority rules, minority loses: bias amplification of gradient descent
May 19, 2025Despite growing empirical evidence of bias amplification in machine learning, its theoretical foundations remain poorly understood. We develop a formal framework for majority-minority learning tasks, showing how standard training can favor majority groups and produce stereotypical predictors that neglect minority-specific features. Assuming population and variance imbalance, our analysis reveals three key findings: (i) the close proximity between ``full-data'' and stereotypical predictors, (ii) the dominance of a region where training the entire model tends to merely learn the majority traits, and (iii) a lower bound on the additional training required. Our results are illustrated through experiments in deep learning for tabular and image classification tasks.
PLS-based approach for fair representation learning
Feb 22, 2025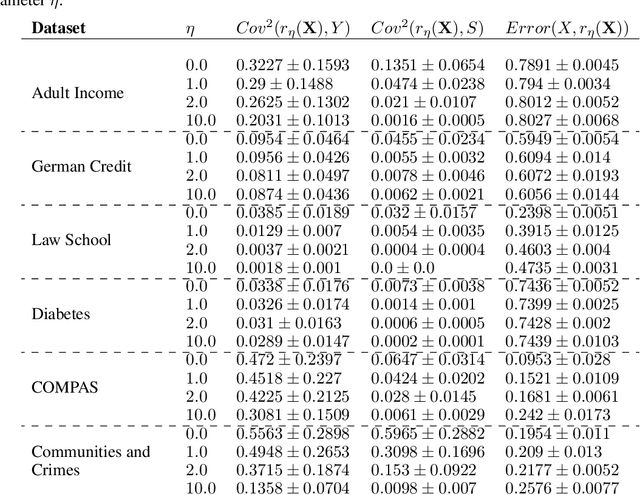
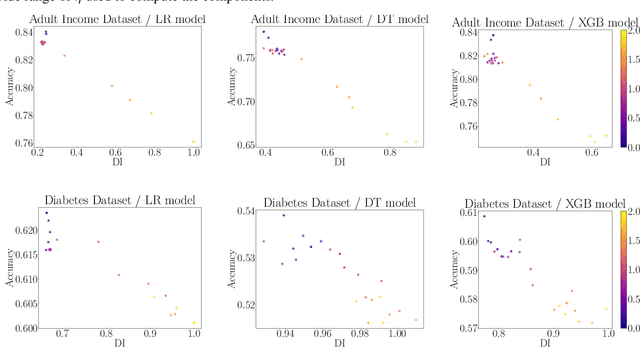

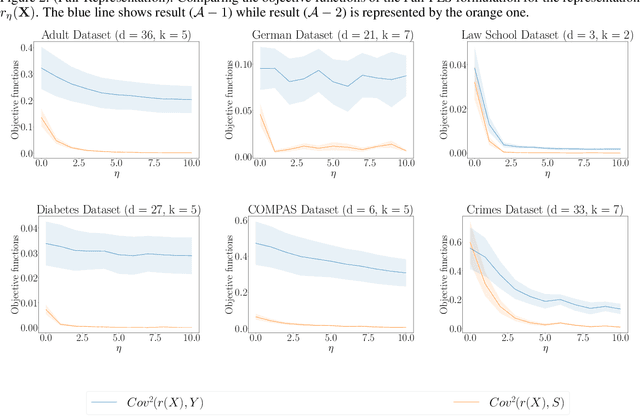
We revisit the problem of fair representation learning by proposing Fair Partial Least Squares (PLS) components. PLS is widely used in statistics to efficiently reduce the dimension of the data by providing representation tailored for the prediction. We propose a novel method to incorporate fairness constraints in the construction of PLS components. This new algorithm provides a feasible way to construct such features both in the linear and the non linear case using kernel embeddings. The efficiency of our method is evaluated on different datasets, and we prove its superiority with respect to standard fair PCA method.
Learning with Differentially Private (Sliced) Wasserstein Gradients
Feb 03, 2025In this work, we introduce a novel framework for privately optimizing objectives that rely on Wasserstein distances between data-dependent empirical measures. Our main theoretical contribution is, based on an explicit formulation of the Wasserstein gradient in a fully discrete setting, a control on the sensitivity of this gradient to individual data points, allowing strong privacy guarantees at minimal utility cost. Building on these insights, we develop a deep learning approach that incorporates gradient and activations clipping, originally designed for DP training of problems with a finite-sum structure. We further demonstrate that privacy accounting methods extend to Wasserstein-based objectives, facilitating large-scale private training. Empirical results confirm that our framework effectively balances accuracy and privacy, offering a theoretically sound solution for privacy-preserving machine learning tasks relying on optimal transport distances such as Wasserstein distance or sliced-Wasserstein distance.
Fair Graph Neural Network with Supervised Contrastive Regularization
Apr 09, 2024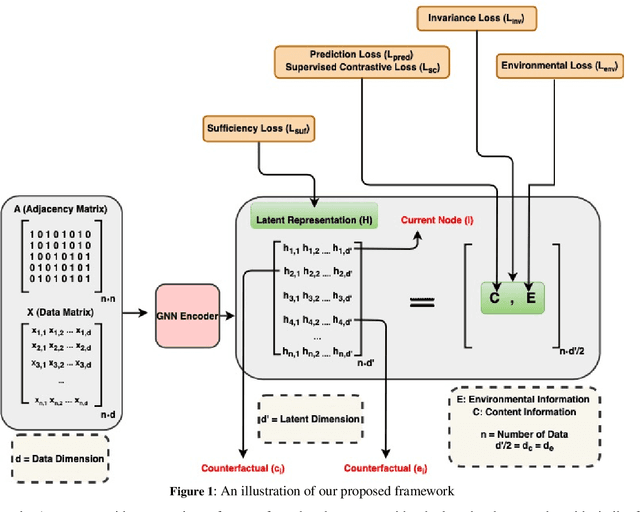


In recent years, Graph Neural Networks (GNNs) have made significant advancements, particularly in tasks such as node classification, link prediction, and graph representation. However, challenges arise from biases that can be hidden not only in the node attributes but also in the connections between entities. Therefore, ensuring fairness in graph neural network learning has become a critical problem. To address this issue, we propose a novel model for training fairness-aware GNN, which enhances the Counterfactual Augmented Fair Graph Neural Network Framework (CAF). Our approach integrates Supervised Contrastive Loss and Environmental Loss to enhance both accuracy and fairness. Experimental validation on three real datasets demonstrates the superiority of our proposed model over CAF and several other existing graph-based learning methods.