 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLS-based approach for fair representation learning
Feb 22, 2025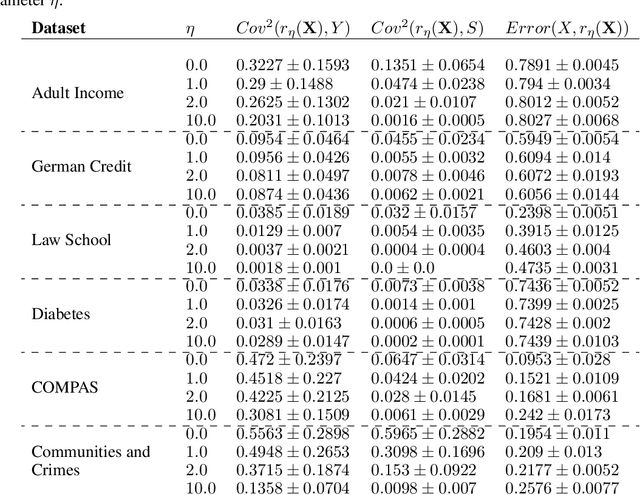
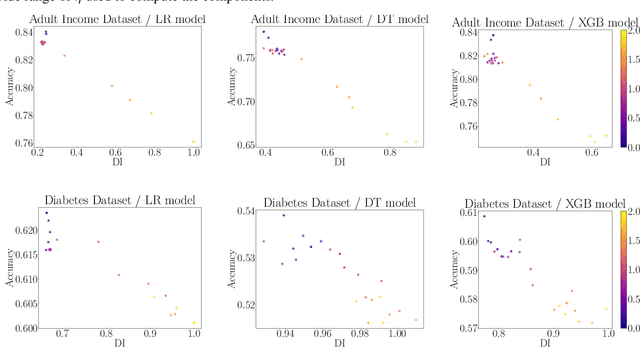

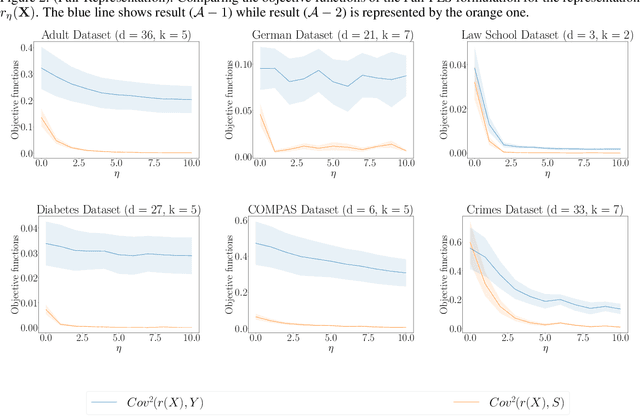
We revisit the problem of fair representation learning by proposing Fair Partial Least Squares (PLS) components. PLS is widely used in statistics to efficiently reduce the dimension of the data by providing representation tailored for the prediction. We propose a novel method to incorporate fairness constraints in the construction of PLS components. This new algorithm provides a feasible way to construct such features both in the linear and the non linear case using kernel embeddings. The efficiency of our method is evaluated on different datasets, and we prove its superiority with respect to standard fair PCA method.
Dancing in the Shadows: Harnessing Ambiguity for Fairer Classifiers
Jun 27, 2024
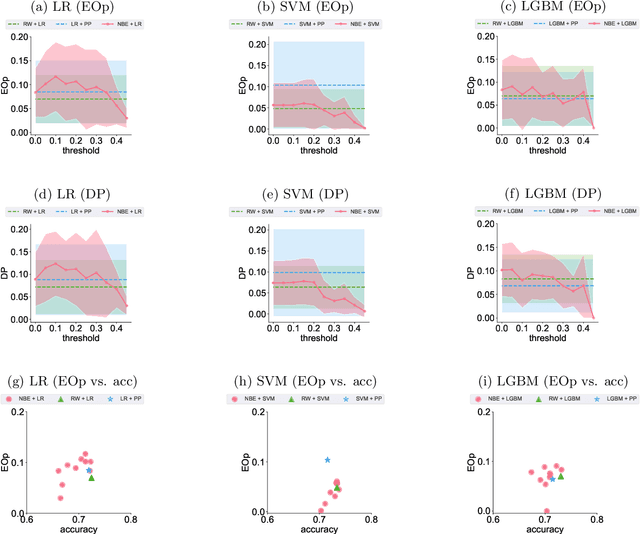
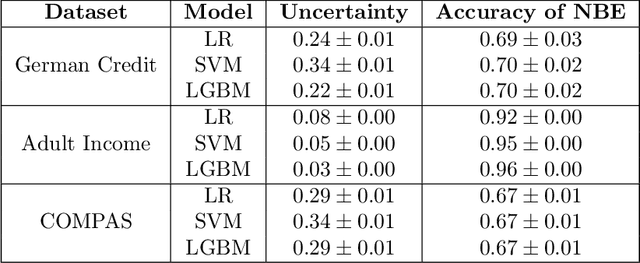
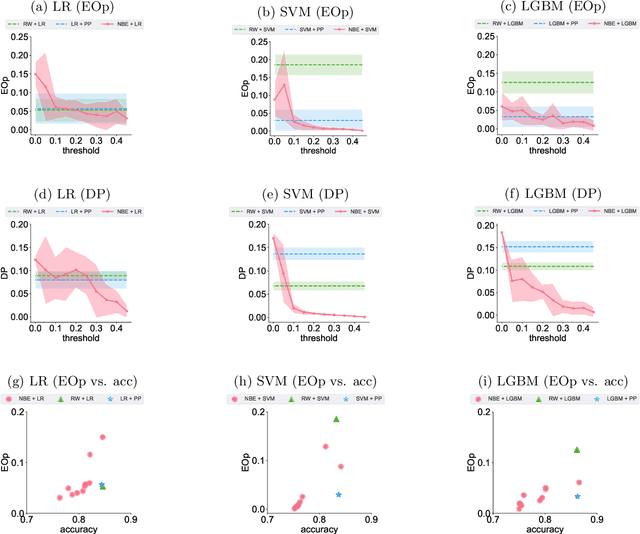
This paper introduces a novel approach to bolster algorithmic fairness in scenarios where sensitive information is only partially known. In particular, we propose to leverage instances with uncertain identity with regards to the sensitive attribute to train a conventional machine learning classifier. The enhanced fairness observed in the final predictions of this classifier highlights the promising potential of prioritizing ambiguity (i.e., non-normativity) as a means to improve fairness guarantees in real-world classification tasks.
Uncertainty in Fairness Assessment: Maintaining Stable Conclusions Despite Fluctuations
Feb 02, 2023



Several recent works encourage the use of a Bayesian framework when assessing performance and fairness metrics of a classification algorithm in a supervised setting. We propose the Uncertainty Matters (UM) framework that generalizes a Beta-Binomial approach to derive the posterior distribution of any criteria combination, allowing stable performance assessment in a bias-aware setting.We suggest modeling the confusion matrix of each demographic group using a Multinomial distribution updated through a Bayesian procedure. We extend UM to be applicable under the popular K-fold cross-validation procedure. Experiments highlight the benefits of UM over classical evaluation frameworks regarding informativeness and stability.
A Survey on Preserving Fairness Guarantees in Changing Environments
Nov 14, 2022
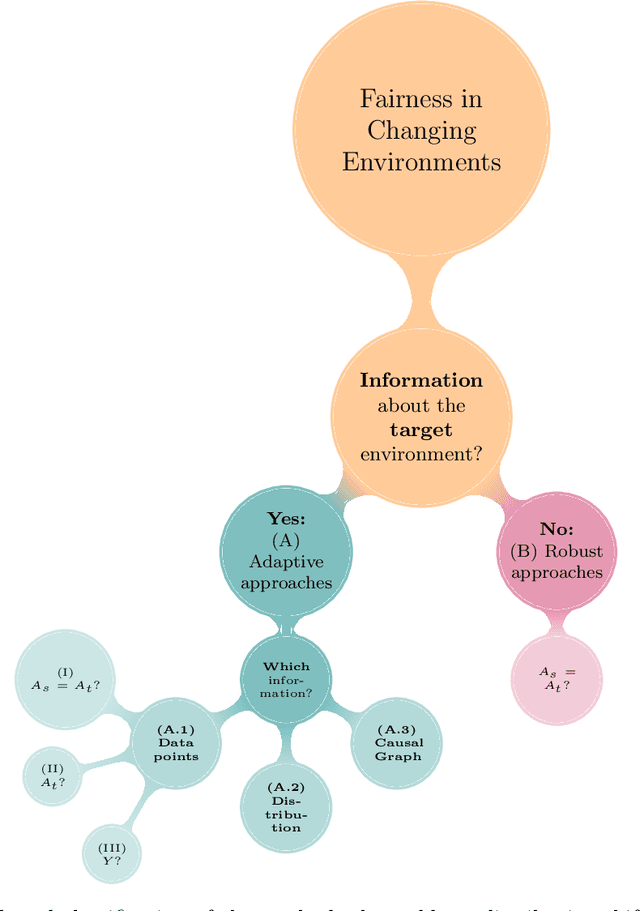

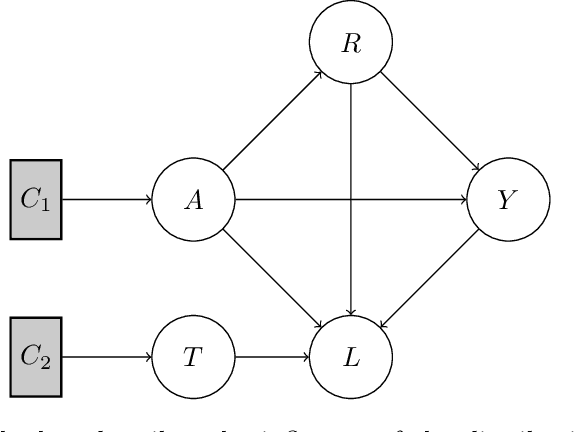
Human lives are increasingly being affected by the outcomes of automated decision-making systems and it is essential for the latter to be, not only accurate, but also fair. The literature of algorithmic fairness has grown considerably over the last decade, where most of the approaches are evaluated under the strong assumption that the train and test samples are independently and identically drawn from the same underlying distribution. However, in practice, dissimilarity between the training and deployment environments exists, which compromises the performance of the decision-making algorithm as well as its fairness guarantees in the deployment data. There is an emergent research line that studies how to preserve fairness guarantees when the data generating processes differ between the source (train) and target (test) domains, which is growing remarkably. With this survey, we aim to provide a wide and unifying overview on the topic. For such purpose, we propose a taxonomy of the existing approaches for fair classification under distribution shift, highlight benchmarking alternatives, point out the relation with other similar research fields and eventually, identify future venues of research.
Review of Mathematical frameworks for Fairness in Machine Learning
May 26, 2020
A review of the main fairness definitions and fair learning methodologies proposed in the literature over the last years is presented from a mathematical point of view. Following our independence-based approach, we consider how to build fair algorithms and the consequences on the degradation of their performance compared to the possibly unfair case. This corresponds to the price for fairness given by the criteria $\textit{statistical parity}$ or $\textit{equality of odds}$. Novel results giving the expressions of the optimal fair classifier and the optimal fair predictor (under a linear regression gaussian model) in the sense of $\textit{equality of odds}$ are presented.
A survey of bias in Machine Learning through the prism of Statistical Parity for the Adult Data Set
Apr 06, 2020

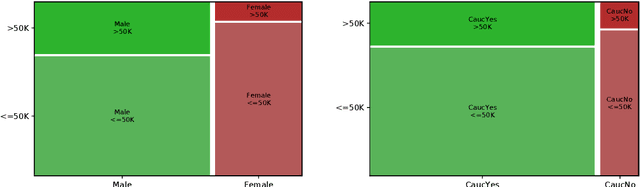
Applications based on Machine Learning models have now become an indispensable part of the everyday life and the professional world. A critical question then recently arised among the population: Do algorithmic decisions convey any type of discrimination against specific groups of population or minorities? In this paper, we show the importance of understanding how a bias can be introduced into automatic decisions. We first present a mathematical framework for the fair learning problem, specifically in the binary classification setting. We then propose to quantify the presence of bias by using the standard Disparate Impact index on the real and well-known Adult income data set. Finally, we check the performance of different approaches aiming to reduce the bias in binary classification outcomes. Importantly, we show that some intuitive methods are ineffective. This sheds light on the fact trying to make fair machine learning models may be a particularly challenging task, in particular when the training observations contain a bias.
Confidence Intervals for Testing Disparate Impact in Fair Learning
Jul 17, 2018We provide the asymptotic distribution of the major indexes used in the statistical literature to quantify disparate treatment in machine learning. We aim at promoting the use of confidence intervals when testing the so-called group disparate impact. We illustrate on some examples the importance of using confidence intervals and not a single value.