 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Preserving Fairness Guarantees in Changing Environments
Paper and Code
Nov 14, 2022
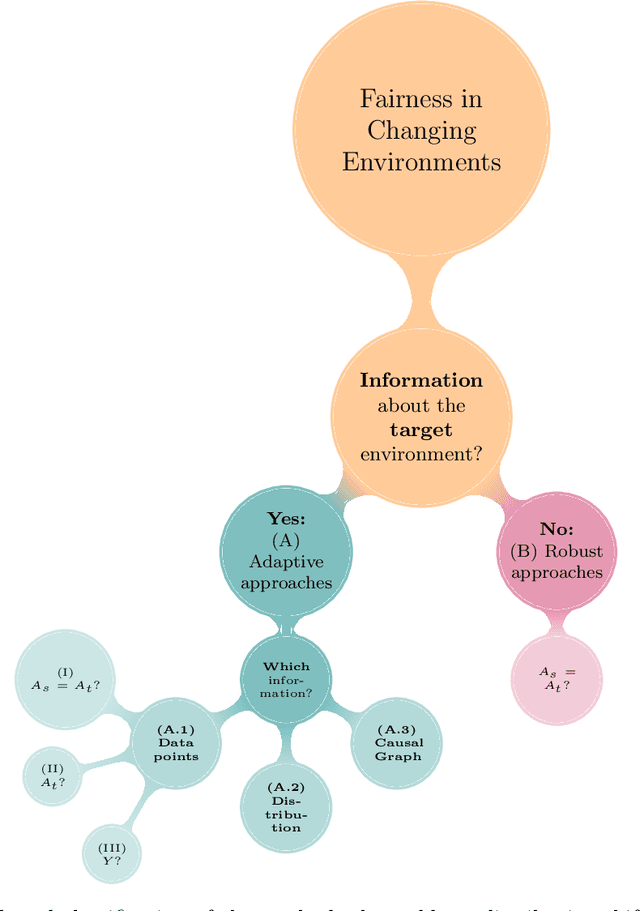

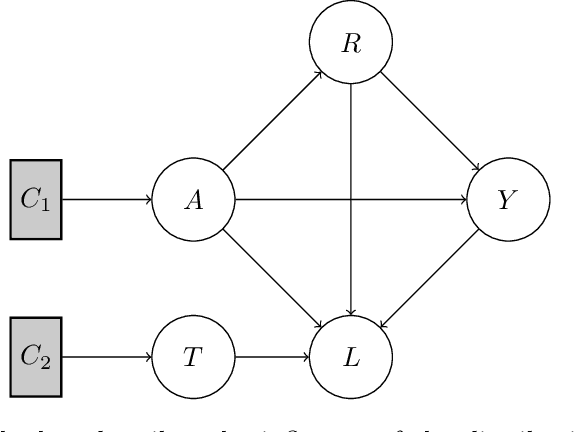
Human lives are increasingly being affected by the outcomes of automated decision-making systems and it is essential for the latter to be, not only accurate, but also fair. The literature of algorithmic fairness has grown considerably over the last decade, where most of the approaches are evaluated under the strong assumption that the train and test samples are independently and identically drawn from the same underlying distribution. However, in practice, dissimilarity between the training and deployment environments exists, which compromises the performance of the decision-making algorithm as well as its fairness guarantees in the deployment data. There is an emergent research line that studies how to preserve fairness guarantees when the data generating processes differ between the source (train) and target (test) domains, which is growing remarkably. With this survey, we aim to provide a wide and unifying overview on the topic. For such purpose, we propose a taxonomy of the existing approaches for fair classification under distribution shift, highlight benchmarking alternatives, point out the relation with other similar research fields and eventually, identify future venues of research.