 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnability with Partial Labels and Adaptive Nearest Neighbors
Mar 16, 2026Prior work on partial labels learning (PLL) has shown that learning is possible even when each instance is associated with a bag of labels, rather than a single accurate but costly label. However, the necessary conditions for learning with partial labels remain unclear, and existing PLL methods are effective only in specific scenarios. In this work, we mathematically characterize the settings in which PLL is feasible. In addition, we present PL A-$k$NN, an adaptive nearest-neighbors algorithm for PLL that is effective in general scenarios and enjoys strong performance guarantees. Experimental results corroborate that PL A-$k$NN can outperform state-of-the-art methods in general PLL scenarios.
Safe Fairness Guarantees Without Demographics in Classification: Spectral Uncertainty Set Perspective
Feb 12, 2026As automated classification systems become increasingly prevalent, concerns have emerged over their potential to reinforce and amplify existing societal biases. In the light of this issue, many methods have been proposed to enhance the fairness guarantees of classifiers. Most of the existing interventions assume access to group information for all instances, a requirement rarely met in practice. Fairness without access to demographic information has often been approached through robust optimization techniques,which target worst-case outcomes over a set of plausible distributions known as the uncertainty set. However, their effectiveness is strongly influenced by the chosen uncertainty set. In fact, existing approaches often overemphasize outliers or overly pessimistic scenarios, compromising both overall performance and fairness. To overcome these limitations, we introduce SPECTRE, a minimax-fair method that adjusts the spectrum of a simple Fourier feature mapping and constrains the extent to which the worst-case distribution can deviate from the empirical distribution. We perform extensive experiments on the American Community Survey datasets involving 20 states. The safeness of SPECTRE comes as it provides the highest average values on fairness guarantees together with the smallest interquartile range in comparison to state-of-the-art approaches, even compared to those with access to demographic group information. In addition, we provide a theoretical analysis that derives computable bounds on the worst-case error for both individual groups and the overall population, as well as characterizes the worst-case distributions responsible for these extremal performances
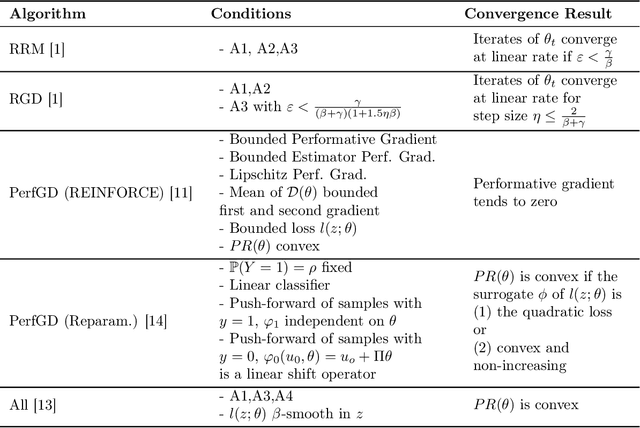
Dissecting Performative Prediction: A Comprehensive Survey
Feb 10, 2026The field of performative prediction had its beginnings in 2020 with the seminal paper "Performative Prediction" by Perdomo et al., which established a novel machine learning setup where the deployment of a predictive model causes a distribution shift in the environment, which in turn causes a mismatch between the distribution expected by the predictive model and the real distribution. This shift is defined by a so-called distribution map. In the half-decade since, a literature has emerged which has, among other things, introduced new solution concepts to the original setup, extended the setup, offered new theoretical analyses, and examined the intersection of performative prediction and other established fields. In this survey, we first lay out the performative prediction setting and explain the different optimization targets: performative stability and performative optimality. We introduce a new way of classifying different performative prediction settings, based on how much information is available about the distribution map. We survey existing implementations of distribution maps and existing methods to address the problem of performative prediction, while examining different ways to categorize them. Finally, we point out known and previously unknown connections that can be drawn to other fields, in the hopes of stimulating future research.
The Decoupled Risk Landscape in Performative Prediction
Jun 10, 2025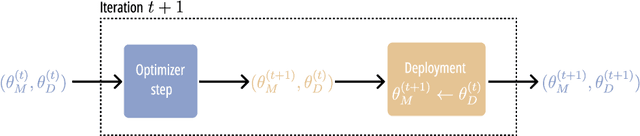
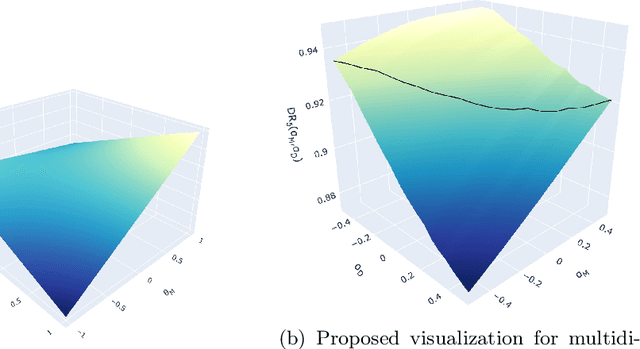
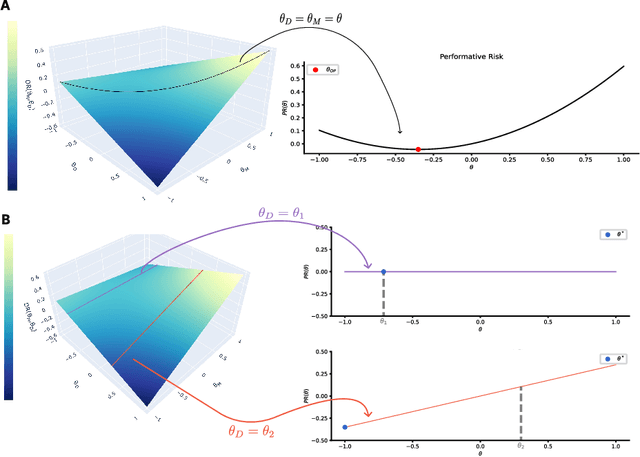
Performative Prediction addresses scenarios where deploying a model induces a distribution shift in the input data, such as individuals modifying their features and reapplying for a bank loan after rejection. Literature has had a theoretical perspective giving mathematical guarantees for convergence (either to the stable or optimal point). We believe that visualization of the loss landscape can complement this theoretical advances with practical insights. Therefore, (1) we introduce a simple decoupled risk visualization method inspired in the two-step process that performative prediction is. Our approach visualizes the risk landscape with respect to two parameter vectors: model parameters and data parameters. We use this method to propose new properties of the interest points, to examine how existing algorithms traverse the risk landscape and perform under more realistic conditions, including strategic classification with non-linear models. (2) Building on this decoupled risk visualization, we introduce a novel setting - extended Performative Prediction - which captures scenarios where the distribution reacts to a model different from the decision-making one, reflecting the reality that agents often lack full access to the deployed model.
A Review on Self-Supervised Learning for Time Series Anomaly Detection: Recent Advances and Open Challenges
Jan 25, 2025Time series anomaly detection presents various challenges due to the sequential and dynamic nature of time-dependent data. Traditional unsupervised methods frequently encounter difficulties in generalization, often overfitting to known normal patterns observed during training and struggling to adapt to unseen normality. In response to this limitation, self-supervised techniques for time series have garnered attention as a potential solution to undertake this obstacle and enhance the performance of anomaly detectors. This paper presents a comprehensive review of the recent methods that make use of self-supervised learning for time series anomaly detection. A taxonomy is proposed to categorize these methods based on their primary characteristics, facilitating a clear understanding of their diversity within this field. The information contained in this survey, along with additional details that will be periodically updated, is available on the following GitHub repository: https://github.com/Aitorzan3/Awesome-Self-Supervised-Time-Series-Anomaly-Detection.
Supervised Learning with Evolving Tasks and Performance Guarantees
Jan 09, 2025Multiple supervised learning scenarios are composed by a sequence of classification tasks. For instance, multi-task learning and continual learning aim to learn a sequence of tasks that is either fixed or grows over time. Existing techniques for learning tasks that are in a sequence are tailored to specific scenarios, lacking adaptability to others. In addition, most of existing techniques consider situations in which the order of the tasks in the sequence is not relevant. However, it is common that tasks in a sequence are evolving in the sense that consecutive tasks often have a higher similarity. This paper presents a learning methodology that is applicable to multiple supervised learning scenarios and adapts to evolving tasks. Differently from existing techniques, we provide computable tight performance guarantees and analytically characterize the increase in the effective sample size. Experiments on benchmark datasets show the performance improvement of the proposed methodology in multiple scenarios and the reliability of the presented performance guarantees.
Craftium: An Extensible Framework for Creating Reinforcement Learning Environments
Jul 04, 2024Most Reinforcement Learning (RL) environments are created by adapting existing physics simulators or video games. However, they usually lack the flexibility required for analyzing specific characteristics of RL methods often relevant to research. This paper presents Craftium, a novel framework for exploring and creating rich 3D visual RL environments that builds upon the Minetest game engine and the popular Gymnasium API. Minetest is built to be extended and can be used to easily create voxel-based 3D environments (often similar to Minecraft), while Gymnasium offers a simple and common interface for RL research. Craftium provides a platform that allows practitioners to create fully customized environments to suit their specific research requirements, ranging from simple visual tasks to infinite and procedurally generated worlds. We also provide five ready-to-use environments for benchmarking and as examples of how to develop new ones. The code and documentation are available at https://github.com/mikelma/craftium/.
Dancing in the Shadows: Harnessing Ambiguity for Fairer Classifiers
Jun 27, 2024
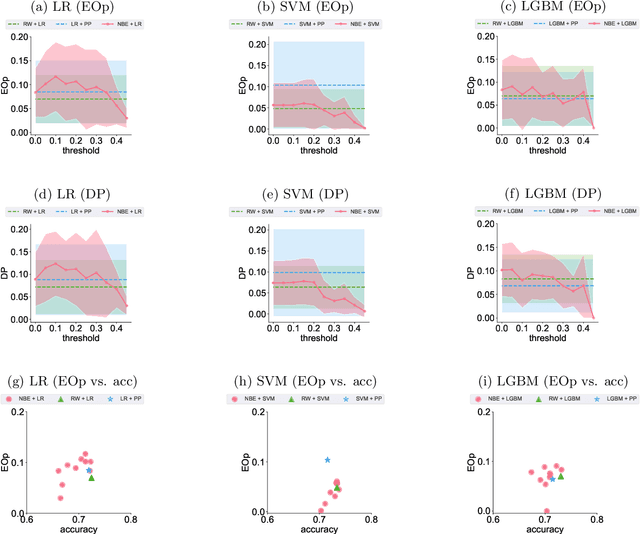
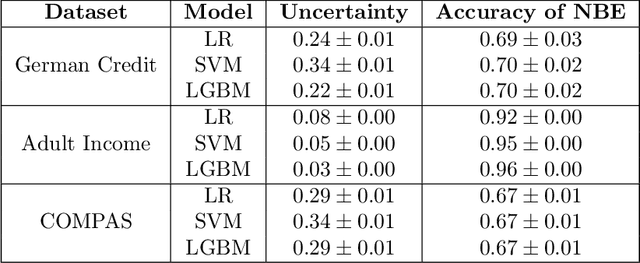
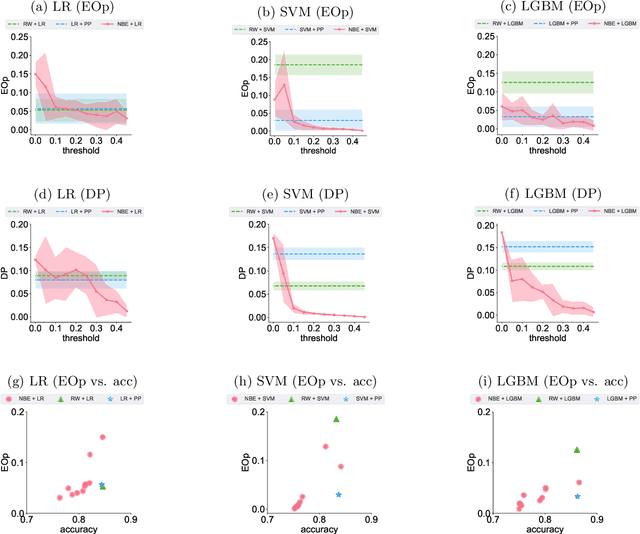
This paper introduces a novel approach to bolster algorithmic fairness in scenarios where sensitive information is only partially known. In particular, we propose to leverage instances with uncertain identity with regards to the sensitive attribute to train a conventional machine learning classifier. The enhanced fairness observed in the final predictions of this classifier highlights the promising potential of prioritizing ambiguity (i.e., non-normativity) as a means to improve fairness guarantees in real-world classification tasks.
Uncertainty-Aware Explanations Through Probabilistic Self-Explainable Neural Networks
Mar 20, 2024The lack of transparency of Deep Neural Networks continues to be a limitation that severely undermines their reliability and usage in high-stakes applications. Promising approaches to overcome such limitations are Prototype-Based Self-Explainable Neural Networks (PSENNs), whose predictions rely on the similarity between the input at hand and a set of prototypical representations of the output classes, offering therefore a deep, yet transparent-by-design, architecture. So far, such models have been designed by considering pointwise estimates for the prototypes, which remain fixed after the learning phase of the model. In this paper, we introduce a probabilistic reformulation of PSENNs, called Prob-PSENN, which replaces point estimates for the prototypes with probability distributions over their values. This provides not only a more flexible framework for an end-to-end learning of prototypes, but can also capture the explanatory uncertainty of the model, which is a missing feature in previous approaches. In addition, since the prototypes determine both the explanation and the prediction, Prob-PSENNs allow us to detect when the model is making uninformed or uncertain predictions, and to obtain valid explanations for them. Our experiments demonstrate that Prob-PSENNs provide more meaningful and robust explanations than their non-probabilistic counterparts, thus enhancing the explainability and reliability of the models.
Time-dependent Probabilistic Generative Models for Disease Progression
Nov 15, 2023Electronic health records contain valuable information for monitoring patients' health trajectories over time. Disease progression models have been developed to understand the underlying patterns and dynamics of diseases using these data as sequences. However, analyzing temporal data from EHRs is challenging due to the variability and irregularities present in medical records. We propose a Markovian generative model of treatments developed to (i) model the irregular time intervals between medical events; (ii) classify treatments into subtypes based on the patient sequence of medical events and the time intervals between them; and (iii) segment treatments into subsequences of disease progression patterns. We assume that sequences have an associated structure of latent variables: a latent class representing the different subtypes of treatments; and a set of latent stages indicating the phase of progression of the treatments. We use the Expectation-Maximization algorithm to learn the model, which is efficiently solved with a dynamic programming-based method. Various parametric models have been employed to model the time intervals between medical events during the learning process, including the geometric, exponential, and Weibull distributions. The results demonstrate the effectiveness of our model in recovering the underlying model from data and accurately modeling the irregular time intervals between medical actions.