 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Generalized Cross-Entropy
Mar 20, 2026Loss functions play a central role in supervised classification. Cross-entropy (CE) is widely used, whereas the mean absolute error (MAE) loss can offer robustness but is difficult to optimize. Interpolating between the CE and MAE losses, generalized cross-entropy (GCE) has recently been introduced to provide a trade-off between optimization difficulty and robustness. Existing formulations of GCE result in a non-convex optimization over classification margins that is prone to underfitting, leading to poor performances with complex datasets. In this paper, we propose a minimax formulation of generalized cross-entropy (MGCE) that results in a convex optimization over classification margins. Moreover, we show that MGCEs can provide an upper bound on the classification error. The proposed bilevel convex optimization can be efficiently implemented using stochastic gradient computed via implicit differentiation. Using benchmark datasets, we show that MGCE achieves strong accuracy, faster convergence, and better calibration, especially in the presence of label noise.
Learnability with Partial Labels and Adaptive Nearest Neighbors
Mar 16, 2026Prior work on partial labels learning (PLL) has shown that learning is possible even when each instance is associated with a bag of labels, rather than a single accurate but costly label. However, the necessary conditions for learning with partial labels remain unclear, and existing PLL methods are effective only in specific scenarios. In this work, we mathematically characterize the settings in which PLL is feasible. In addition, we present PL A-$k$NN, an adaptive nearest-neighbors algorithm for PLL that is effective in general scenarios and enjoys strong performance guarantees. Experimental results corroborate that PL A-$k$NN can outperform state-of-the-art methods in general PLL scenarios.
Safe Fairness Guarantees Without Demographics in Classification: Spectral Uncertainty Set Perspective
Feb 12, 2026As automated classification systems become increasingly prevalent, concerns have emerged over their potential to reinforce and amplify existing societal biases. In the light of this issue, many methods have been proposed to enhance the fairness guarantees of classifiers. Most of the existing interventions assume access to group information for all instances, a requirement rarely met in practice. Fairness without access to demographic information has often been approached through robust optimization techniques,which target worst-case outcomes over a set of plausible distributions known as the uncertainty set. However, their effectiveness is strongly influenced by the chosen uncertainty set. In fact, existing approaches often overemphasize outliers or overly pessimistic scenarios, compromising both overall performance and fairness. To overcome these limitations, we introduce SPECTRE, a minimax-fair method that adjusts the spectrum of a simple Fourier feature mapping and constrains the extent to which the worst-case distribution can deviate from the empirical distribution. We perform extensive experiments on the American Community Survey datasets involving 20 states. The safeness of SPECTRE comes as it provides the highest average values on fairness guarantees together with the smallest interquartile range in comparison to state-of-the-art approaches, even compared to those with access to demographic group information. In addition, we provide a theoretical analysis that derives computable bounds on the worst-case error for both individual groups and the overall population, as well as characterizes the worst-case distributions responsible for these extremal performances
Adaptive Multi-task Learning for Probabilistic Load Forecasting
Dec 23, 2025Simultaneous load forecasting across multiple entities (e.g., regions, buildings) is crucial for the efficient, reliable, and cost-effective operation of power systems. Accurate load forecasting is a challenging problem due to the inherent uncertainties in load demand, dynamic changes in consumption patterns, and correlations among entities. Multi-task learning has emerged as a powerful machine learning approach that enables the simultaneous learning across multiple related problems. However, its application to load forecasting remains underexplored and is limited to offline learning-based methods, which cannot capture changes in consumption patterns. This paper presents an adaptive multi-task learning method for probabilistic load forecasting. The proposed method can dynamically adapt to changes in consumption patterns and correlations among entities. In addition, the techniques presented provide reliable probabilistic predictions for loads of multiples entities and assess load uncertainties. Specifically, the method is based on vectorvalued hidden Markov models and uses a recursive process to update the model parameters and provide predictions with the most recent parameters. The performance of the proposed method is evaluated using datasets that contain the load demand of multiple entities and exhibit diverse and dynamic consumption patterns. The experimental results show that the presented techniques outperform existing methods both in terms of forecasting performance and uncertainty assessment.
On the Optimality of the Median-of-Means Estimator under Adversarial Contamination
Oct 09, 2025The Median-of-Means (MoM) is a robust estimator widely used in machine learning that is known to be (minimax) optimal in scenarios where samples are i.i.d. In more grave scenarios, samples are contaminated by an adversary that can inspect and modify the data. Previous work has theoretically shown the suitability of the MoM estimator in certain contaminated settings. However, the (minimax) optimality of MoM and its limitations under adversarial contamination remain unknown beyond the Gaussian case. In this paper, we present upper and lower bounds for the error of MoM under adversarial contamination for multiple classes of distributions. In particular, we show that MoM is (minimax) optimal in the class of distributions with finite variance, as well as in the class of distributions with infinite variance and finite absolute $(1+r)$-th moment. We also provide lower bounds for MoM's error that match the order of the presented upper bounds, and show that MoM is sub-optimal for light-tailed distributions.
Split Conformal Classification with Unsupervised Calibration
Oct 08, 2025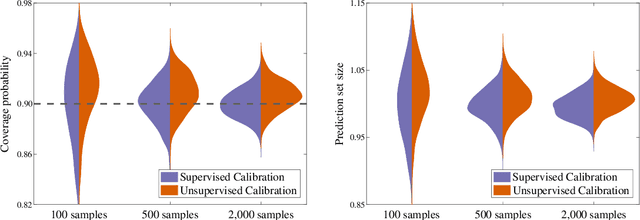
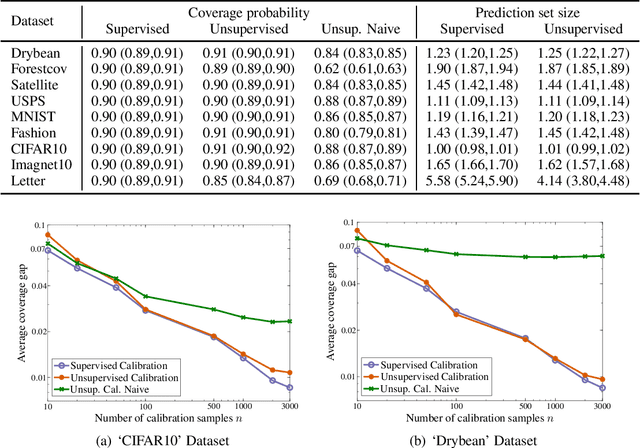
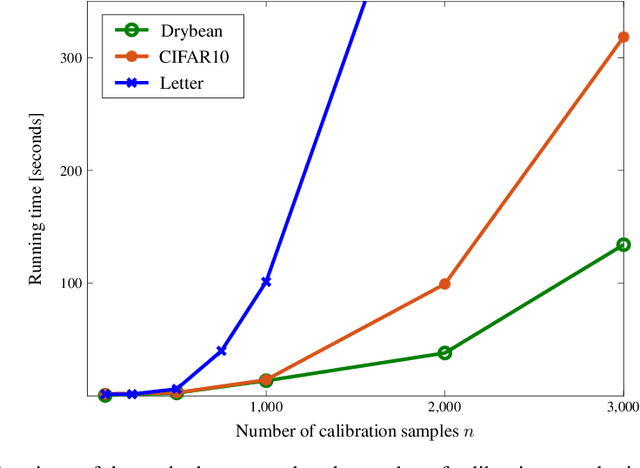
Methods for split conformal prediction leverage calibration samples to transform any prediction rule into a set-prediction rule that complies with a target coverage probability. Existing methods provide remarkably strong performance guarantees with minimal computational costs. However, they require to use calibration samples composed by labeled examples different to those used for training. This requirement can be highly inconvenient, as it prevents the use of all labeled examples for training and may require acquiring additional labels solely for calibration. This paper presents an effective methodology for split conformal prediction with unsupervised calibration for classification tasks. In the proposed approach, set-prediction rules are obtained using unsupervised calibration samples together with supervised training samples previously used to learn the classification rule. Theoretical and experimental results show that the presented methods can achieve performance comparable to that with supervised calibration, at the expenses of a moderate degradation in performance guarantees and computational efficiency.
Reliable Programmatic Weak Supervision with Confidence Intervals for Label Probabilities
Aug 05, 2025



The accurate labeling of datasets is often both costly and time-consuming. Given an unlabeled dataset, programmatic weak supervision obtains probabilistic predictions for the labels by leveraging multiple weak labeling functions (LFs) that provide rough guesses for labels. Weak LFs commonly provide guesses with assorted types and unknown interdependences that can result in unreliable predictions. Furthermore, existing techniques for programmatic weak supervision cannot provide assessments for the reliability of the probabilistic predictions for labels. This paper presents a methodology for programmatic weak supervision that can provide confidence intervals for label probabilities and obtain more reliable predictions. In particular, the methods proposed use uncertainty sets of distributions that encapsulate the information provided by LFs with unrestricted behavior and typology. Experiments on multiple benchmark datasets show the improvement of the presented methods over the state-of-the-art and the practicality of the confidence intervals presented.
Multi-task Online Learning for Probabilistic Load Forecasting
Feb 06, 2025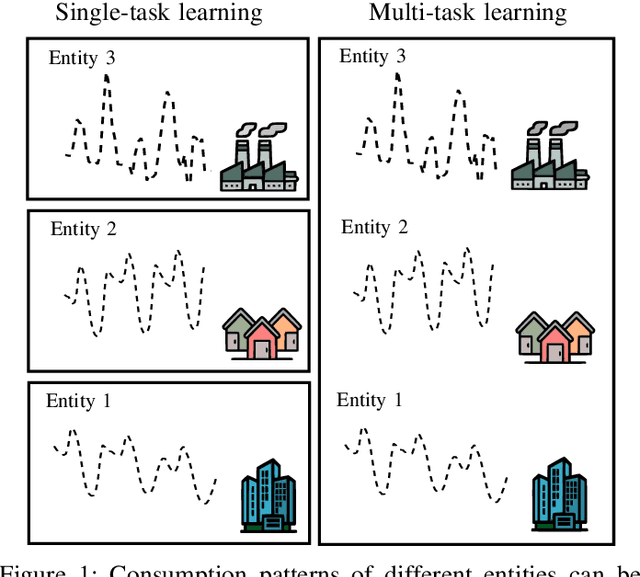


Load forecasting is essential for the efficient, reliable, and cost-effective management of power systems. Load forecasting performance can be improved by learning the similarities among multiple entities (e.g., regions, buildings). Techniques based on multi-task learning obtain predictions by leveraging consumption patterns from the historical load demand of multiple entities and their relationships. However, existing techniques cannot effectively assess inherent uncertainties in load demand or account for dynamic changes in consumption patterns. This paper proposes a multi-task learning technique for online and probabilistic load forecasting. This technique provides accurate probabilistic predictions for the loads of multiple entities by leveraging their dynamic similarities. The method's performance is evaluated using datasets that register the load demand of multiple entities and contain diverse and dynamic consumption patterns. The experimental results show that the proposed method can significantly enhance the effectiveness of current multi-task learning approaches across a wide variety of load consumption scenarios.
Supervised Learning with Evolving Tasks and Performance Guarantees
Jan 09, 2025Multiple supervised learning scenarios are composed by a sequence of classification tasks. For instance, multi-task learning and continual learning aim to learn a sequence of tasks that is either fixed or grows over time. Existing techniques for learning tasks that are in a sequence are tailored to specific scenarios, lacking adaptability to others. In addition, most of existing techniques consider situations in which the order of the tasks in the sequence is not relevant. However, it is common that tasks in a sequence are evolving in the sense that consecutive tasks often have a higher similarity. This paper presents a learning methodology that is applicable to multiple supervised learning scenarios and adapts to evolving tasks. Differently from existing techniques, we provide computable tight performance guarantees and analytically characterize the increase in the effective sample size. Experiments on benchmark datasets show the performance improvement of the proposed methodology in multiple scenarios and the reliability of the presented performance guarantees.
Minimax Forward and Backward Learning of Evolving Tasks with Performance Guarantees
Oct 24, 2023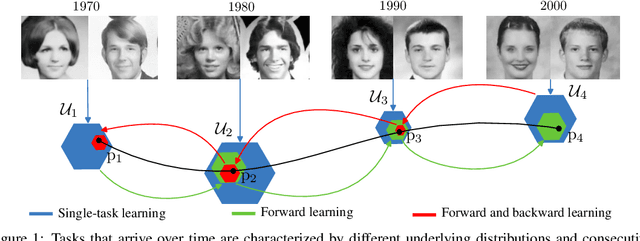
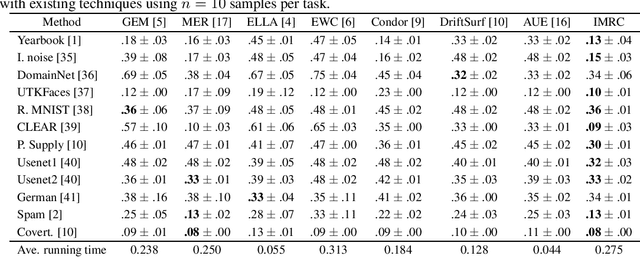
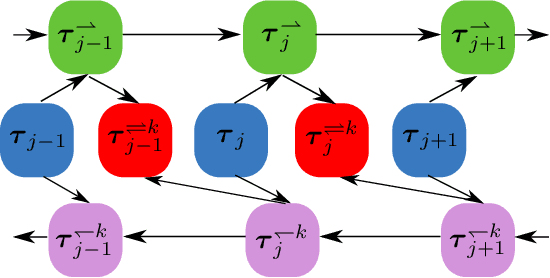

For a sequence of classification tasks that arrive over time, it is common that tasks are evolving in the sense that consecutive tasks often have a higher similarity. The incremental learning of a growing sequence of tasks holds promise to enable accurate classification even with few samples per task by leveraging information from all the tasks in the sequence (forward and backward learning). However, existing techniques developed for continual learning and concept drift adaptation are either designed for tasks with time-independent similarities or only aim to learn the last task in the sequence. This paper presents incremental minimax risk classifiers (IMRCs) that effectively exploit forward and backward learning and account for evolving tasks. In addition, we analytically characterize the performance improvement provided by forward and backward learning in terms of the tasks' expected quadratic change and the number of tasks. The experimental evaluation shows that IMRCs can result in a significant performance improvement, especially for reduced sample sizes.