 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax risk classifiers with 0-1 loss
Paper and Code


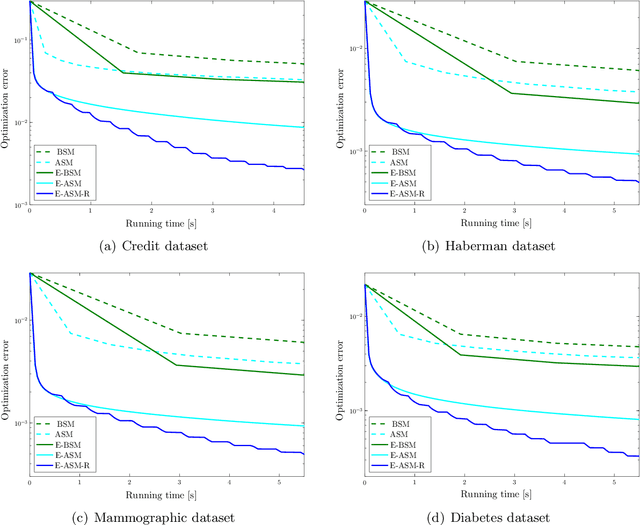
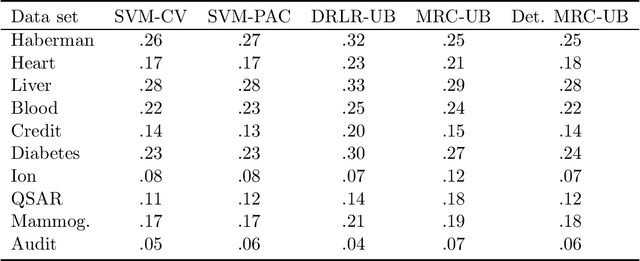
Supervised classification techniques use training samples to learn a classification rule with small expected 0-1-loss (error probability). Conventional methods enable tractable learning and provide out-of-sample generalization by using surrogate losses instead of the 0-1-loss and considering specific families of rules (hypothesis classes). This paper presents minimax risk classifiers (MRCs) that minimize the worst-case 0-1-loss over general classification rules and provide tight performance guarantees at learning. We show that MRCs are strongly universally consistent using feature mappings given by characteristic kernels. The paper also proposes efficient optimization techniques for MRC learning and shows that the methods presented can provide accurate classification together with tight performance guarantees