 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Fairness Guarantees Without Demographics in Classification: Spectral Uncertainty Set Perspective
Feb 12, 2026As automated classification systems become increasingly prevalent, concerns have emerged over their potential to reinforce and amplify existing societal biases. In the light of this issue, many methods have been proposed to enhance the fairness guarantees of classifiers. Most of the existing interventions assume access to group information for all instances, a requirement rarely met in practice. Fairness without access to demographic information has often been approached through robust optimization techniques,which target worst-case outcomes over a set of plausible distributions known as the uncertainty set. However, their effectiveness is strongly influenced by the chosen uncertainty set. In fact, existing approaches often overemphasize outliers or overly pessimistic scenarios, compromising both overall performance and fairness. To overcome these limitations, we introduce SPECTRE, a minimax-fair method that adjusts the spectrum of a simple Fourier feature mapping and constrains the extent to which the worst-case distribution can deviate from the empirical distribution. We perform extensive experiments on the American Community Survey datasets involving 20 states. The safeness of SPECTRE comes as it provides the highest average values on fairness guarantees together with the smallest interquartile range in comparison to state-of-the-art approaches, even compared to those with access to demographic group information. In addition, we provide a theoretical analysis that derives computable bounds on the worst-case error for both individual groups and the overall population, as well as characterizes the worst-case distributions responsible for these extremal performances
Who Pays for Fairness? Rethinking Recourse under Social Burden
Sep 04, 2025



Machine learning based predictions are increasingly used in sensitive decision-making applications that directly affect our lives. This has led to extensive research into ensuring the fairness of classifiers. Beyond just fair classification, emerging legislation now mandates that when a classifier delivers a negative decision, it must also offer actionable steps an individual can take to reverse that outcome. This concept is known as algorithmic recourse. Nevertheless, many researchers have expressed concerns about the fairness guarantees within the recourse process itself. In this work, we provide a holistic theoretical characterization of unfairness in algorithmic recourse, formally linking fairness guarantees in recourse and classification, and highlighting limitations of the standard equal cost paradigm. We then introduce a novel fairness framework based on social burden, along with a practical algorithm (MISOB), broadly applicable under real-world conditions. Empirical results on real-world datasets show that MISOB reduces the social burden across all groups without compromising overall classifier accuracy.
Dancing in the Shadows: Harnessing Ambiguity for Fairer Classifiers
Jun 27, 2024
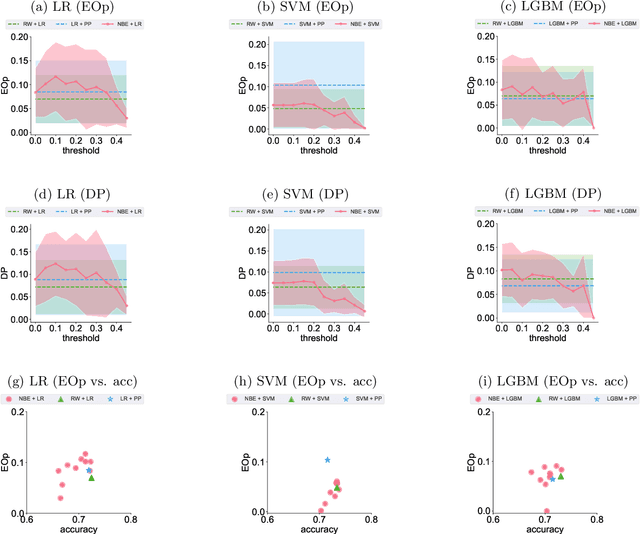
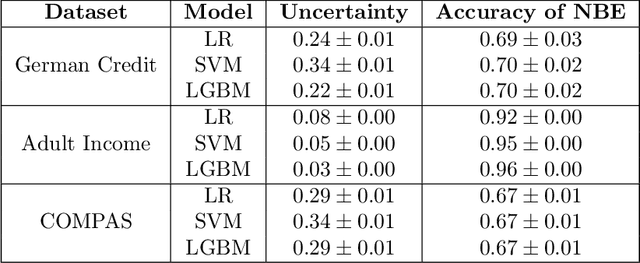
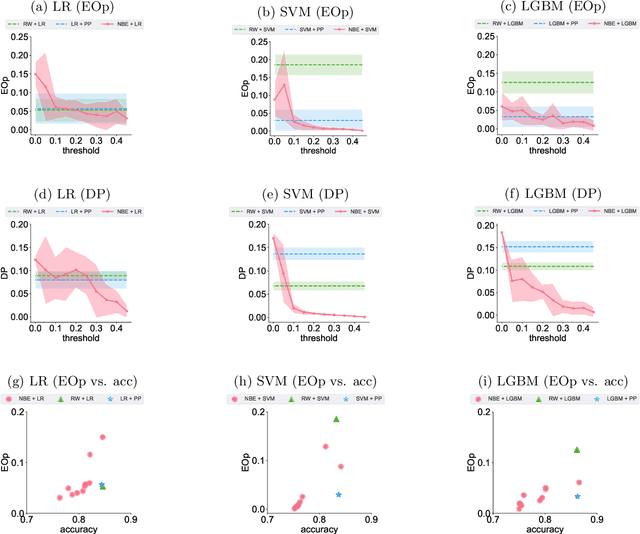
This paper introduces a novel approach to bolster algorithmic fairness in scenarios where sensitive information is only partially known. In particular, we propose to leverage instances with uncertain identity with regards to the sensitive attribute to train a conventional machine learning classifier. The enhanced fairness observed in the final predictions of this classifier highlights the promising potential of prioritizing ambiguity (i.e., non-normativity) as a means to improve fairness guarantees in real-world classification tasks.
Uncertainty in Fairness Assessment: Maintaining Stable Conclusions Despite Fluctuations
Feb 02, 2023



Several recent works encourage the use of a Bayesian framework when assessing performance and fairness metrics of a classification algorithm in a supervised setting. We propose the Uncertainty Matters (UM) framework that generalizes a Beta-Binomial approach to derive the posterior distribution of any criteria combination, allowing stable performance assessment in a bias-aware setting.We suggest modeling the confusion matrix of each demographic group using a Multinomial distribution updated through a Bayesian procedure. We extend UM to be applicable under the popular K-fold cross-validation procedure. Experiments highlight the benefits of UM over classical evaluation frameworks regarding informativeness and stability.
A Survey on Preserving Fairness Guarantees in Changing Environments
Nov 14, 2022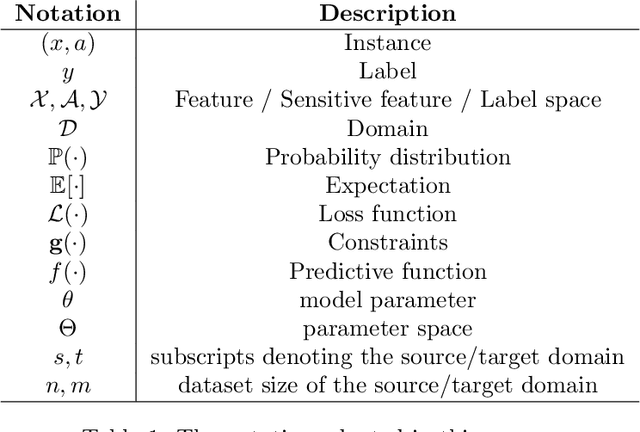
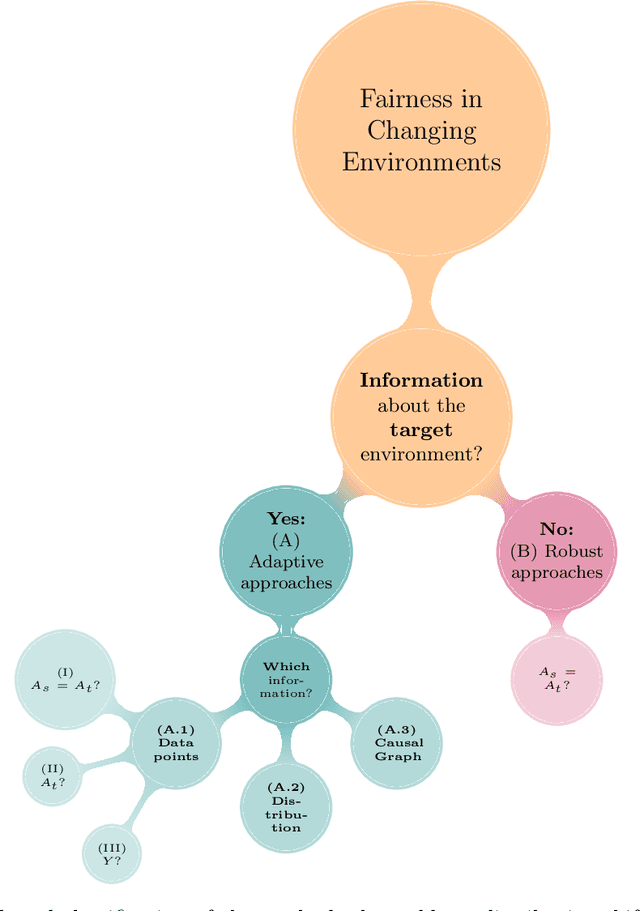

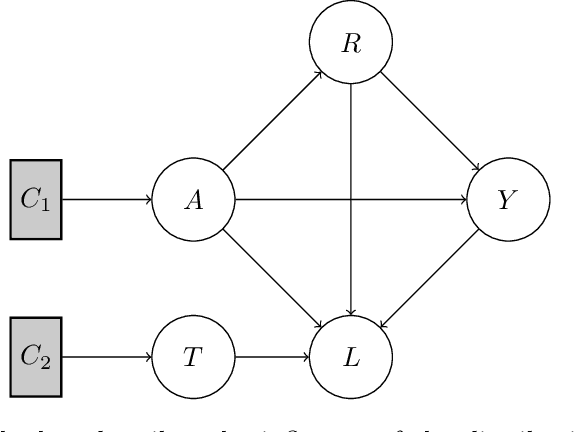
Human lives are increasingly being affected by the outcomes of automated decision-making systems and it is essential for the latter to be, not only accurate, but also fair. The literature of algorithmic fairness has grown considerably over the last decade, where most of the approaches are evaluated under the strong assumption that the train and test samples are independently and identically drawn from the same underlying distribution. However, in practice, dissimilarity between the training and deployment environments exists, which compromises the performance of the decision-making algorithm as well as its fairness guarantees in the deployment data. There is an emergent research line that studies how to preserve fairness guarantees when the data generating processes differ between the source (train) and target (test) domains, which is growing remarkably. With this survey, we aim to provide a wide and unifying overview on the topic. For such purpose, we propose a taxonomy of the existing approaches for fair classification under distribution shift, highlight benchmarking alternatives, point out the relation with other similar research fields and eventually, identify future venues of research.