 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Performative Prediction: A Comprehensive Survey
Feb 10, 2026The field of performative prediction had its beginnings in 2020 with the seminal paper "Performative Prediction" by Perdomo et al., which established a novel machine learning setup where the deployment of a predictive model causes a distribution shift in the environment, which in turn causes a mismatch between the distribution expected by the predictive model and the real distribution. This shift is defined by a so-called distribution map. In the half-decade since, a literature has emerged which has, among other things, introduced new solution concepts to the original setup, extended the setup, offered new theoretical analyses, and examined the intersection of performative prediction and other established fields. In this survey, we first lay out the performative prediction setting and explain the different optimization targets: performative stability and performative optimality. We introduce a new way of classifying different performative prediction settings, based on how much information is available about the distribution map. We survey existing implementations of distribution maps and existing methods to address the problem of performative prediction, while examining different ways to categorize them. Finally, we point out known and previously unknown connections that can be drawn to other fields, in the hopes of stimulating future research.
The Decoupled Risk Landscape in Performative Prediction
Jun 10, 2025
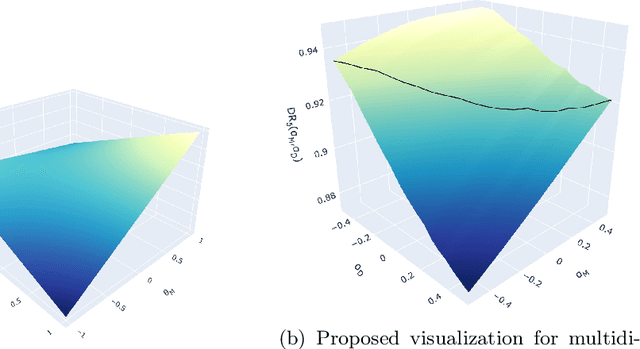
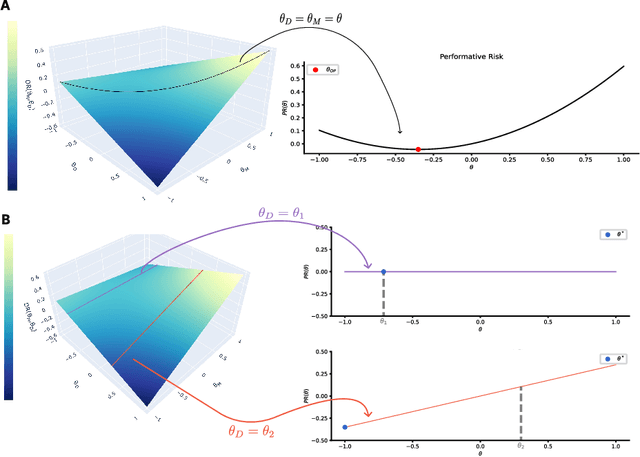
Performative Prediction addresses scenarios where deploying a model induces a distribution shift in the input data, such as individuals modifying their features and reapplying for a bank loan after rejection. Literature has had a theoretical perspective giving mathematical guarantees for convergence (either to the stable or optimal point). We believe that visualization of the loss landscape can complement this theoretical advances with practical insights. Therefore, (1) we introduce a simple decoupled risk visualization method inspired in the two-step process that performative prediction is. Our approach visualizes the risk landscape with respect to two parameter vectors: model parameters and data parameters. We use this method to propose new properties of the interest points, to examine how existing algorithms traverse the risk landscape and perform under more realistic conditions, including strategic classification with non-linear models. (2) Building on this decoupled risk visualization, we introduce a novel setting - extended Performative Prediction - which captures scenarios where the distribution reacts to a model different from the decision-making one, reflecting the reality that agents often lack full access to the deployed model.
Addressing Missing Sources with Adversarial Support-Matching
Mar 24, 2022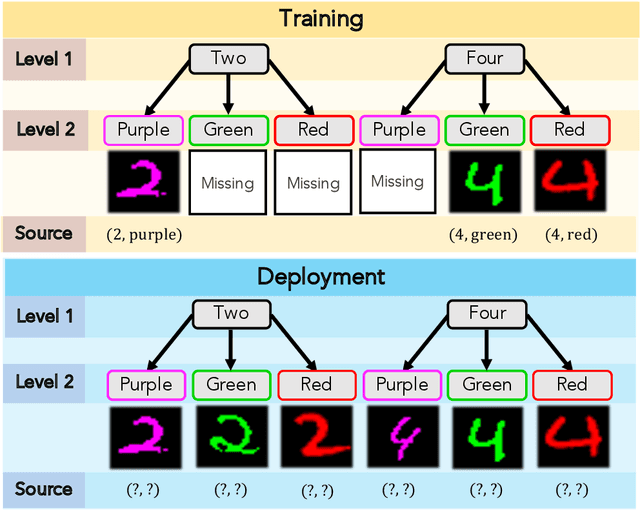
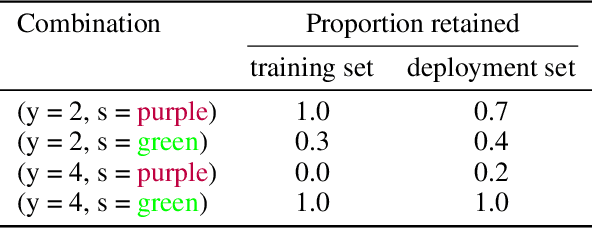
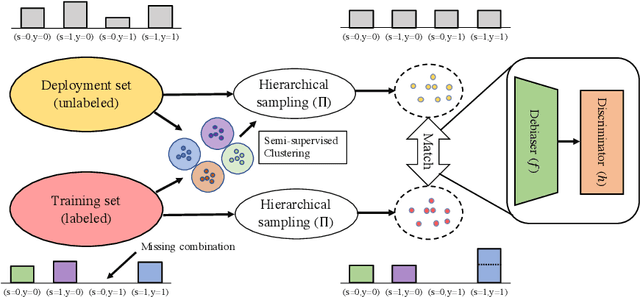
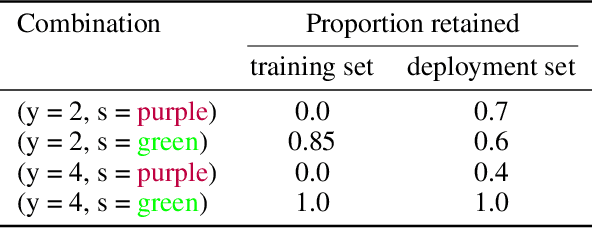
When trained on diverse labeled data, machine learning models have proven themselves to be a powerful tool in all facets of society. However, due to budget limitations, deliberate or non-deliberate censorship, and other problems during data collection and curation, the labeled training set might exhibit a systematic shortage of data for certain groups. We investigate a scenario in which the absence of certain data is linked to the second level of a two-level hierarchy in the data. Inspired by the idea of protected groups from algorithmic fairness, we refer to the partitions carved by this second level as "subgroups"; we refer to combinations of subgroups and classes, or leaves of the hierarchy, as "sources". To characterize the problem, we introduce the concept of classes with incomplete subgroup support. The representational bias in the training set can give rise to spurious correlations between the classes and the subgroups which render standard classification models ungeneralizable to unseen sources. To overcome this bias, we make use of an additional, diverse but unlabeled dataset, called the "deployment set", to learn a representation that is invariant to subgroup. This is done by adversarially matching the support of the training and deployment sets in representation space. In order to learn the desired invariance, it is paramount that the sets of samples observed by the discriminator are balanced by class; this is easily achieved for the training set, but requires using semi-supervised clustering for the deployment set. We demonstrate the effectiveness of our method with experiments on several datasets and variants of the problem.
Null-sampling for Interpretable and Fair Representations
Aug 12, 2020



We propose to learn invariant representations, in the data domain, to achieve interpretability in algorithmic fairness. Invariance implies a selectivity for high level, relevant correlations w.r.t. class label annotations, and a robustness to irrelevant correlations with protected characteristics such as race or gender. We introduce a non-trivial setup in which the training set exhibits a strong bias such that class label annotations are irrelevant and spurious correlations cannot be distinguished. To address this problem, we introduce an adversarially trained model with a null-sampling procedure to produce invariant representations in the data domain. To enable disentanglement, a partially-labelled representative set is used. By placing the representations into the data domain, the changes made by the model are easily examinable by human auditors. We show the effectiveness of our method on both image and tabular datasets: Coloured MNIST, the CelebA and the Adult dataset.
Interpretable Fairness via Target Labels in Gaussian Process Models
Oct 18, 2018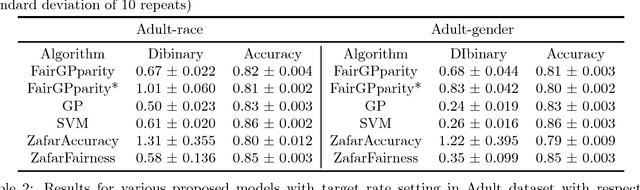
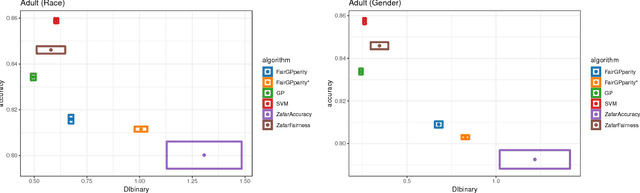
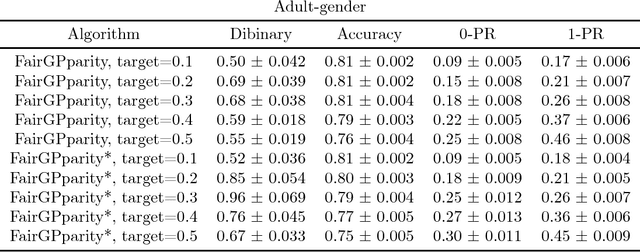
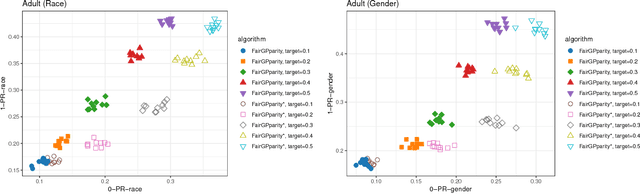
Addressing fairness in machine learning models has recently attracted a lot of attention, as it will ensure continued confidence of the general public in the deployment of machine learning systems. Here, we focus on mitigating harm of a biased system that offers much better quality outputs for certain groups than for others. We show that bias in the output can naturally be handled in Gaussian process classification (GPC) models by introducing a latent target output that will modulate the likelihood function. This simple formulation has several advantages: first, it is a unified framework for several notions of fairness (demographic parity, equalized odds, and equal opportunity); second, it allows encoding our knowledge of what the bias in outputs should be; and third, it can be solved by using off-the-shelf GPC packages.
Weakly Supervised One-Shot Detection with Attention Similarity Networks
Jun 27, 2018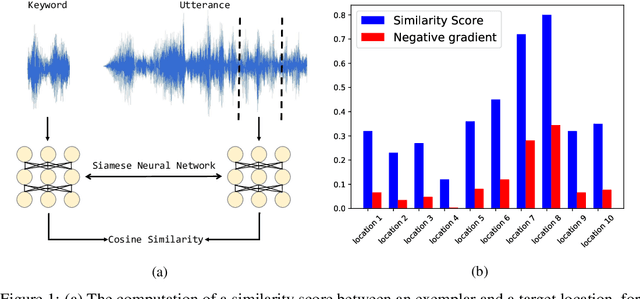
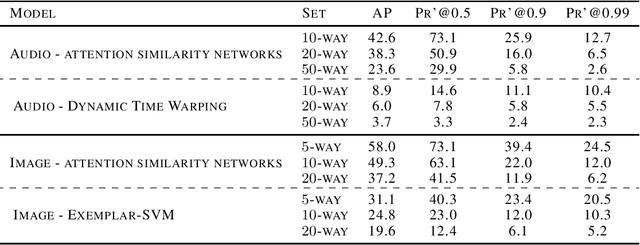

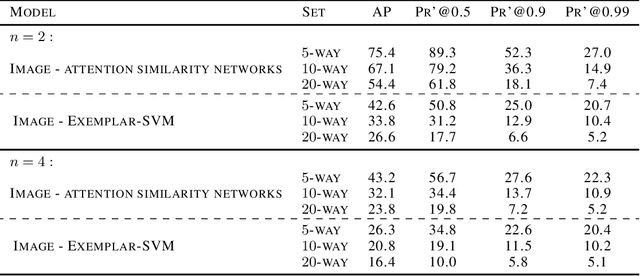
Neural network models that are not conditioned on class identities were shown to facilitate knowledge transfer between classes and to be well-suited for one-shot learning tasks. Following this motivation, we further explore and establish such models and present a novel neural network architecture for the task of weakly supervised one-shot detection. Our model is only conditioned on a single exemplar of an unseen class and a larger target example that may or may not contain an instance of the same class as the exemplar. By pairing a Siamese similarity network with an attention mechanism, we design a model that manages to simultaneously identify and localise instances of classes unseen at training time. In experiments with datasets from the computer vision and audio domains, the proposed method considerably outperforms the baseline methods for the weakly supervised one-shot detection task.