 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOkapi: Generalising Better by Making Statistical Matches Match
Nov 07, 2022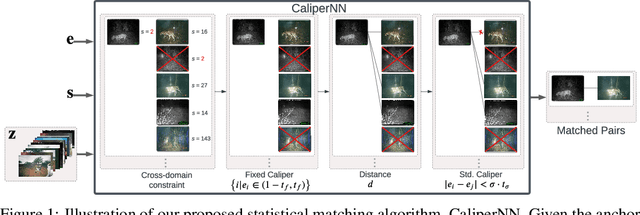
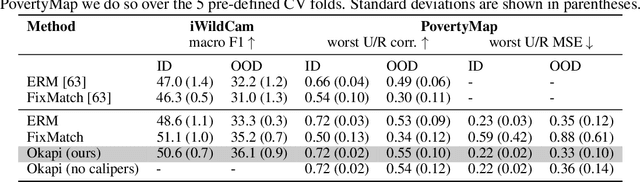
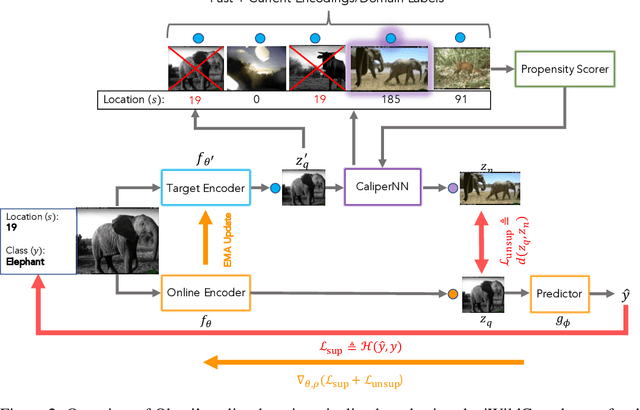

We propose Okapi, a simple, efficient, and general method for robust semi-supervised learning based on online statistical matching. Our method uses a nearest-neighbours-based matching procedure to generate cross-domain views for a consistency loss, while eliminating statistical outliers. In order to perform the online matching in a runtime- and memory-efficient way, we draw upon the self-supervised literature and combine a memory bank with a slow-moving momentum encoder. The consistency loss is applied within the feature space, rather than on the predictive distribution, making the method agnostic to both the modality and the task in question. We experiment on the WILDS 2.0 datasets Sagawa et al., which significantly expands the range of modalities, applications, and shifts available for studying and benchmarking real-world unsupervised adaptation. Contrary to Sagawa et al., we show that it is in fact possible to leverage additional unlabelled data to improve upon empirical risk minimisation (ERM) results with the right method. Our method outperforms the baseline methods in terms of out-of-distribution (OOD) generalisation on the iWildCam (a multi-class classification task) and PovertyMap (a regression task) image datasets as well as the CivilComments (a binary classification task) text dataset. Furthermore, from a qualitative perspective, we show the matches obtained from the learned encoder are strongly semantically related. Code for our paper is publicly available at https://github.com/wearepal/okapi/.
Addressing Missing Sources with Adversarial Support-Matching
Mar 24, 2022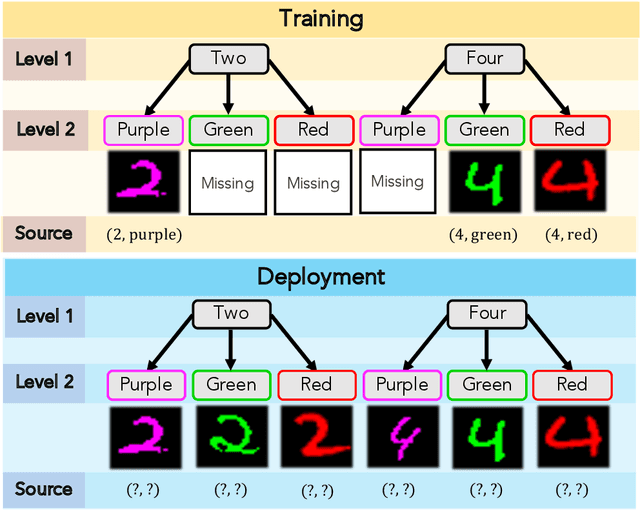
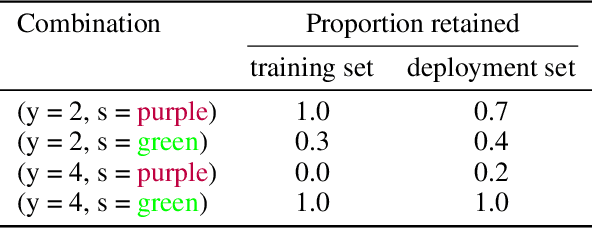
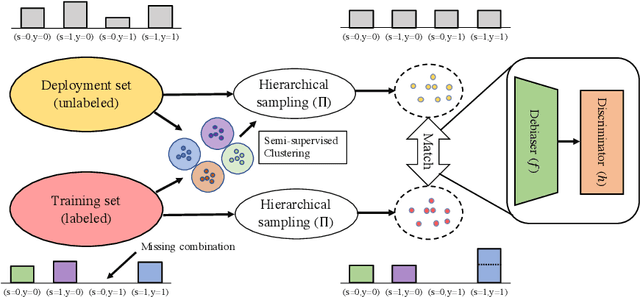
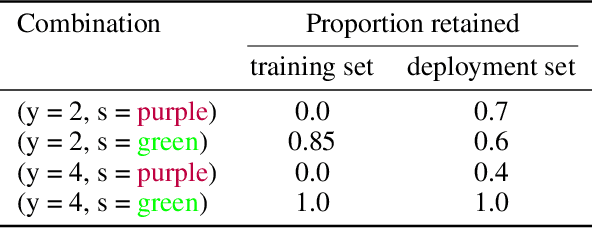
When trained on diverse labeled data, machine learning models have proven themselves to be a powerful tool in all facets of society. However, due to budget limitations, deliberate or non-deliberate censorship, and other problems during data collection and curation, the labeled training set might exhibit a systematic shortage of data for certain groups. We investigate a scenario in which the absence of certain data is linked to the second level of a two-level hierarchy in the data. Inspired by the idea of protected groups from algorithmic fairness, we refer to the partitions carved by this second level as "subgroups"; we refer to combinations of subgroups and classes, or leaves of the hierarchy, as "sources". To characterize the problem, we introduce the concept of classes with incomplete subgroup support. The representational bias in the training set can give rise to spurious correlations between the classes and the subgroups which render standard classification models ungeneralizable to unseen sources. To overcome this bias, we make use of an additional, diverse but unlabeled dataset, called the "deployment set", to learn a representation that is invariant to subgroup. This is done by adversarially matching the support of the training and deployment sets in representation space. In order to learn the desired invariance, it is paramount that the sets of samples observed by the discriminator are balanced by class; this is easily achieved for the training set, but requires using semi-supervised clustering for the deployment set. We demonstrate the effectiveness of our method with experiments on several datasets and variants of the problem.
Null-sampling for Interpretable and Fair Representations
Aug 12, 2020



We propose to learn invariant representations, in the data domain, to achieve interpretability in algorithmic fairness. Invariance implies a selectivity for high level, relevant correlations w.r.t. class label annotations, and a robustness to irrelevant correlations with protected characteristics such as race or gender. We introduce a non-trivial setup in which the training set exhibits a strong bias such that class label annotations are irrelevant and spurious correlations cannot be distinguished. To address this problem, we introduce an adversarially trained model with a null-sampling procedure to produce invariant representations in the data domain. To enable disentanglement, a partially-labelled representative set is used. By placing the representations into the data domain, the changes made by the model are easily examinable by human auditors. We show the effectiveness of our method on both image and tabular datasets: Coloured MNIST, the CelebA and the Adult dataset.