 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Inference of Vision Transformers by Training-Free Tokenization
Nov 23, 2024



The cost of deploying vision transformers increasingly represents a barrier to wider industrial adoption. Existing compression requires additional end-to-end fine-tuning or incurs a significant drawback to runtime, thus making them ill-suited for online inference. We introduce the $\textbf{Visual Word Tokenizer}$ (VWT), a training-free method for reducing energy costs while retaining performance and runtime. The VWT groups patches (visual subwords) that are frequently used into visual words while infrequent ones remain intact. To do so, intra-image or inter-image statistics are leveraged to identify similar visual concepts for compression. Experimentally, we demonstrate a reduction in wattage of up to 19% with only a 20% increase in runtime at most. Comparative approaches of 8-bit quantization and token merging achieve a lower or similar energy efficiency but exact a higher toll on runtime (up to $2\times$ or more). Our results indicate that VWTs are well-suited for efficient online inference with a marginal compromise on performance.
Distribution Matching for Multi-Task Learning of Classification Tasks: a Large-Scale Study on Faces & Beyond
Jan 03, 2024

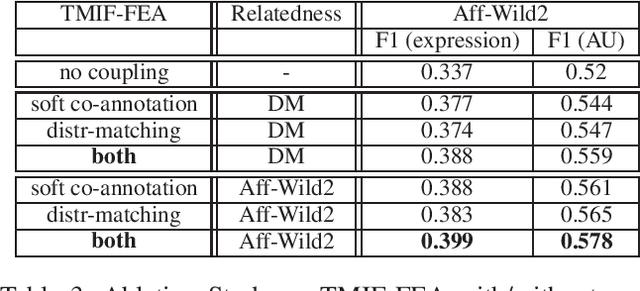
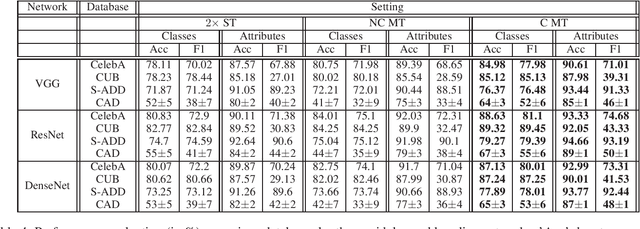
Multi-Task Learning (MTL) is a framework, where multiple related tasks are learned jointly and benefit from a shared representation space, or parameter transfer. To provide sufficient learning support, modern MTL uses annotated data with full, or sufficiently large overlap across tasks, i.e., each input sample is annotated for all, or most of the tasks. However, collecting such annotations is prohibitive in many real applications, and cannot benefit from datasets available for individual tasks. In this work, we challenge this setup and show that MTL can be successful with classification tasks with little, or non-overlapping annotations, or when there is big discrepancy in the size of labeled data per task. We explore task-relatedness for co-annotation and co-training, and propose a novel approach, where knowledge exchange is enabled between the tasks via distribution matching. To demonstrate the general applicability of our method, we conducted diverse case studies in the domains of affective computing, face recognition, species recognition, and shopping item classification using nine datasets. Our large-scale study of affective tasks for basic expression recognition and facial action unit detection illustrates that our approach is network agnostic and brings large performance improvements compared to the state-of-the-art in both tasks and across all studied databases. In all case studies, we show that co-training via task-relatedness is advantageous and prevents negative transfer (which occurs when MT model's performance is worse than that of at least one single-task model).
Okapi: Generalising Better by Making Statistical Matches Match
Nov 07, 2022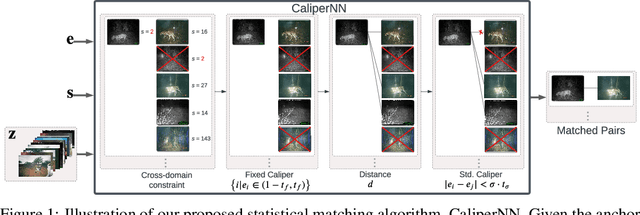
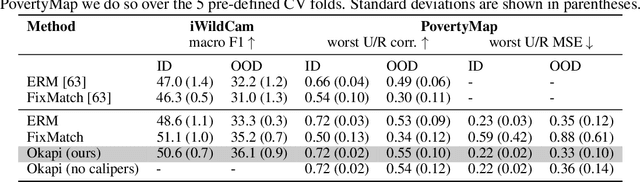
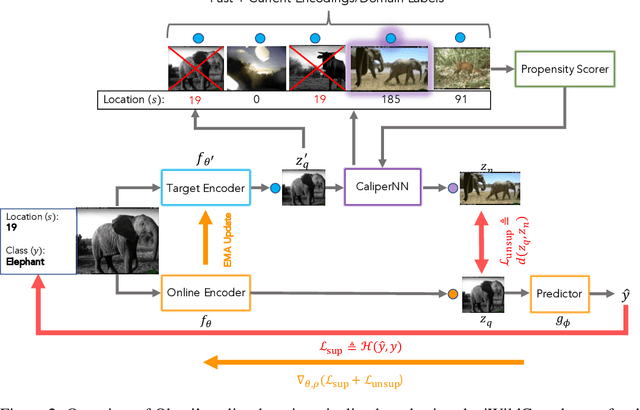

We propose Okapi, a simple, efficient, and general method for robust semi-supervised learning based on online statistical matching. Our method uses a nearest-neighbours-based matching procedure to generate cross-domain views for a consistency loss, while eliminating statistical outliers. In order to perform the online matching in a runtime- and memory-efficient way, we draw upon the self-supervised literature and combine a memory bank with a slow-moving momentum encoder. The consistency loss is applied within the feature space, rather than on the predictive distribution, making the method agnostic to both the modality and the task in question. We experiment on the WILDS 2.0 datasets Sagawa et al., which significantly expands the range of modalities, applications, and shifts available for studying and benchmarking real-world unsupervised adaptation. Contrary to Sagawa et al., we show that it is in fact possible to leverage additional unlabelled data to improve upon empirical risk minimisation (ERM) results with the right method. Our method outperforms the baseline methods in terms of out-of-distribution (OOD) generalisation on the iWildCam (a multi-class classification task) and PovertyMap (a regression task) image datasets as well as the CivilComments (a binary classification task) text dataset. Furthermore, from a qualitative perspective, we show the matches obtained from the learned encoder are strongly semantically related. Code for our paper is publicly available at https://github.com/wearepal/okapi/.
Free-HeadGAN: Neural Talking Head Synthesis with Explicit Gaze Control
Aug 03, 2022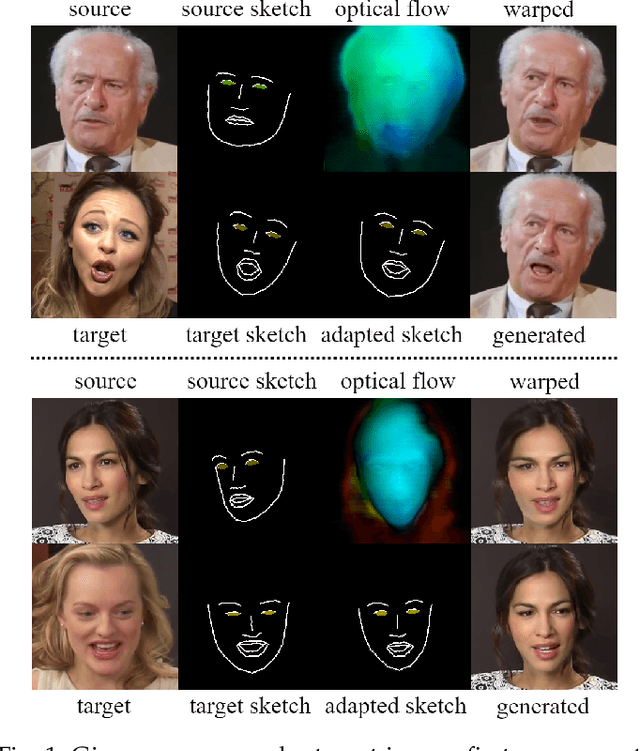
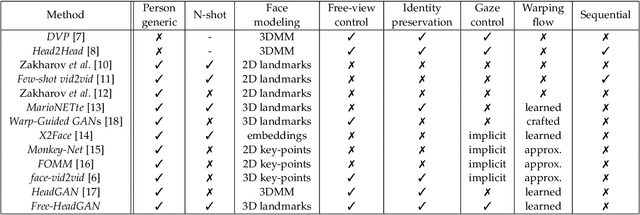
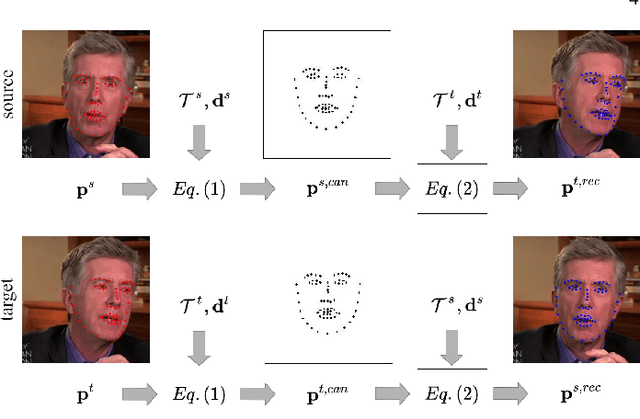
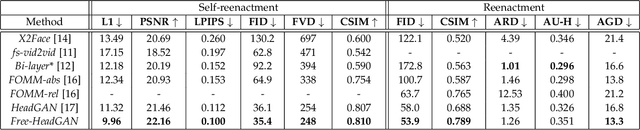
We present Free-HeadGAN, a person-generic neural talking head synthesis system. We show that modeling faces with sparse 3D facial landmarks are sufficient for achieving state-of-the-art generative performance, without relying on strong statistical priors of the face, such as 3D Morphable Models. Apart from 3D pose and facial expressions, our method is capable of fully transferring the eye gaze, from a driving actor to a source identity. Our complete pipeline consists of three components: a canonical 3D key-point estimator that regresses 3D pose and expression-related deformations, a gaze estimation network and a generator that is built upon the architecture of HeadGAN. We further experiment with an extension of our generator to accommodate few-shot learning using an attention mechanism, in case more than one source images are available. Compared to the latest models for reenactment and motion transfer, our system achieves higher photo-realism combined with superior identity preservation, while offering explicit gaze control.
RealPatch: A Statistical Matching Framework for Model Patching with Real Samples
Aug 03, 2022
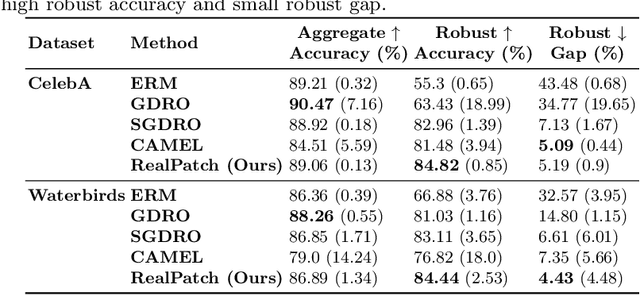
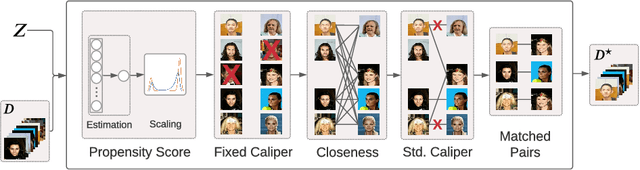

Machine learning classifiers are typically trained to minimise the average error across a dataset. Unfortunately, in practice, this process often exploits spurious correlations caused by subgroup imbalance within the training data, resulting in high average performance but highly variable performance across subgroups. Recent work to address this problem proposes model patching with CAMEL. This previous approach uses generative adversarial networks to perform intra-class inter-subgroup data augmentations, requiring (a) the training of a number of computationally expensive models and (b) sufficient quality of model's synthetic outputs for the given domain. In this work, we propose RealPatch, a framework for simpler, faster, and more data-efficient data augmentation based on statistical matching. Our framework performs model patching by augmenting a dataset with real samples, mitigating the need to train generative models for the target task. We demonstrate the effectiveness of RealPatch on three benchmark datasets, CelebA, Waterbirds and a subset of iWildCam, showing improvements in worst-case subgroup performance and in subgroup performance gap in binary classification. Furthermore, we conduct experiments with the imSitu dataset with 211 classes, a setting where generative model-based patching such as CAMEL is impractical. We show that RealPatch can successfully eliminate dataset leakage while reducing model leakage and maintaining high utility. The code for RealPatch can be found at https://github.com/wearepal/RealPatch.
DAD-3DHeads: A Large-scale Dense, Accurate and Diverse Dataset for 3D Head Alignment from a Single Image
Apr 11, 2022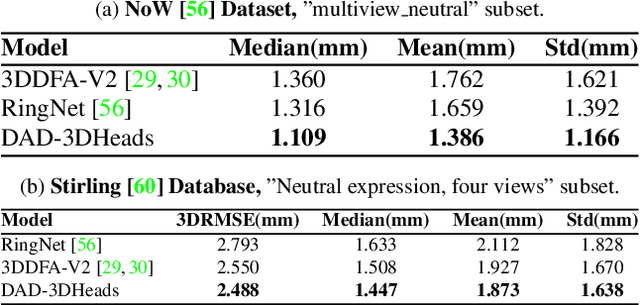
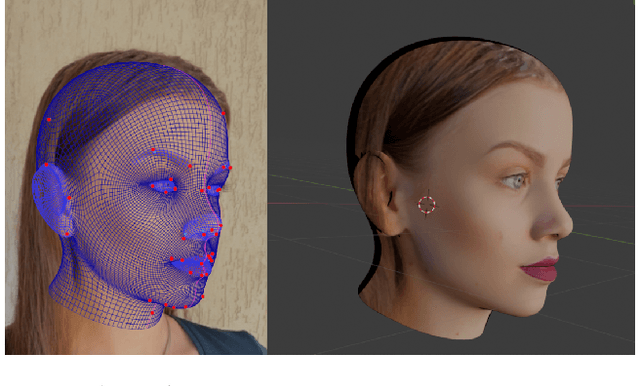
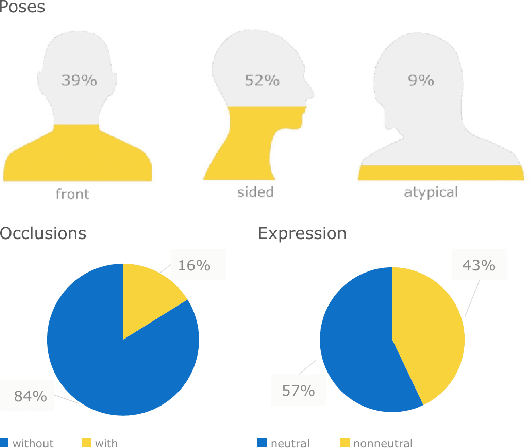
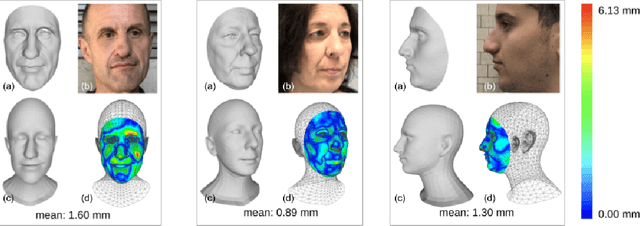
We present DAD-3DHeads, a dense and diverse large-scale dataset, and a robust model for 3D Dense Head Alignment in the wild. It contains annotations of over 3.5K landmarks that accurately represent 3D head shape compared to the ground-truth scans. The data-driven model, DAD-3DNet, trained on our dataset, learns shape, expression, and pose parameters, and performs 3D reconstruction of a FLAME mesh. The model also incorporates a landmark prediction branch to take advantage of rich supervision and co-training of multiple related tasks. Experimentally, DAD-3DNet outperforms or is comparable to the state-of-the-art models in (i) 3D Head Pose Estimation on AFLW2000-3D and BIWI, (ii) 3D Face Shape Reconstruction on NoW and Feng, and (iii) 3D Dense Head Alignment and 3D Landmarks Estimation on DAD-3DHeads dataset. Finally, the diversity of DAD-3DHeads in camera angles, facial expressions, and occlusions enables a benchmark to study in-the-wild generalization and robustness to distribution shifts. The dataset webpage is https://p.farm/research/dad-3dheads.
Addressing Missing Sources with Adversarial Support-Matching
Mar 24, 2022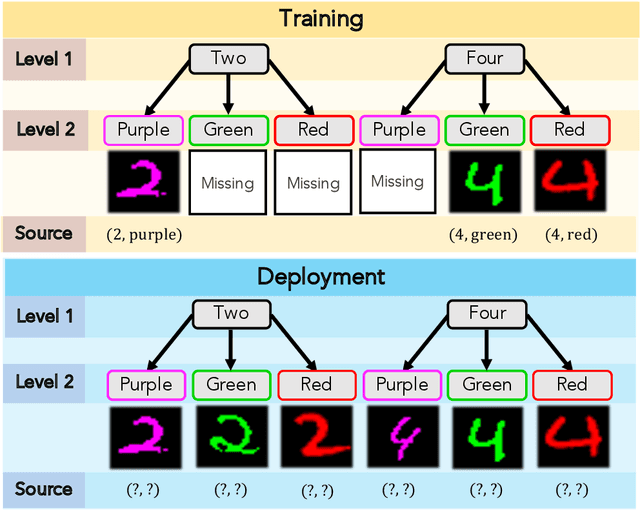
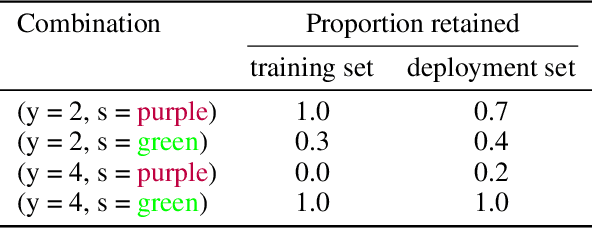
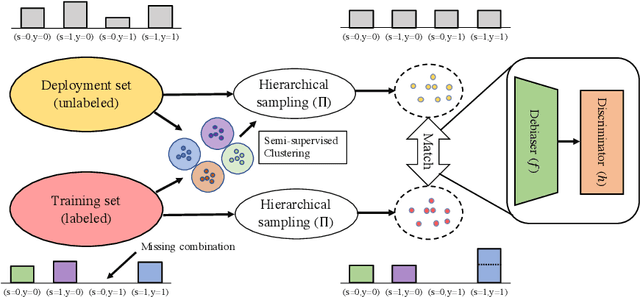
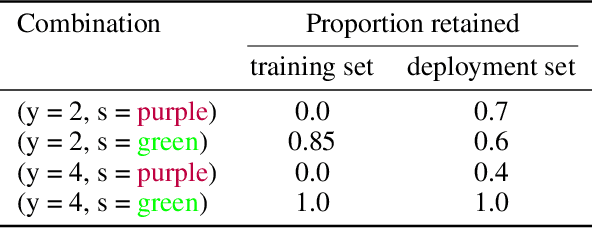
When trained on diverse labeled data, machine learning models have proven themselves to be a powerful tool in all facets of society. However, due to budget limitations, deliberate or non-deliberate censorship, and other problems during data collection and curation, the labeled training set might exhibit a systematic shortage of data for certain groups. We investigate a scenario in which the absence of certain data is linked to the second level of a two-level hierarchy in the data. Inspired by the idea of protected groups from algorithmic fairness, we refer to the partitions carved by this second level as "subgroups"; we refer to combinations of subgroups and classes, or leaves of the hierarchy, as "sources". To characterize the problem, we introduce the concept of classes with incomplete subgroup support. The representational bias in the training set can give rise to spurious correlations between the classes and the subgroups which render standard classification models ungeneralizable to unseen sources. To overcome this bias, we make use of an additional, diverse but unlabeled dataset, called the "deployment set", to learn a representation that is invariant to subgroup. This is done by adversarially matching the support of the training and deployment sets in representation space. In order to learn the desired invariance, it is paramount that the sets of samples observed by the discriminator are balanced by class; this is easily achieved for the training set, but requires using semi-supervised clustering for the deployment set. We demonstrate the effectiveness of our method with experiments on several datasets and variants of the problem.
Distribution Matching for Heterogeneous Multi-Task Learning: a Large-scale Face Study
May 08, 2021
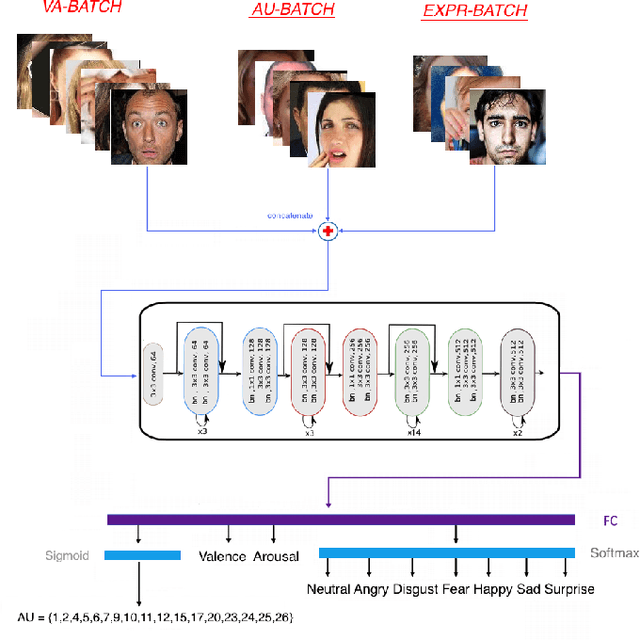

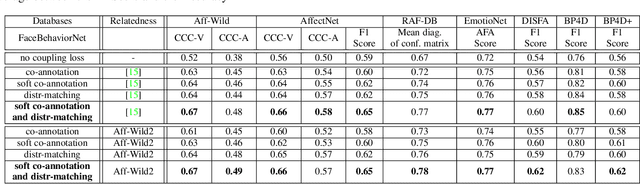
Multi-Task Learning has emerged as a methodology in which multiple tasks are jointly learned by a shared learning algorithm, such as a DNN. MTL is based on the assumption that the tasks under consideration are related; therefore it exploits shared knowledge for improving performance on each individual task. Tasks are generally considered to be homogeneous, i.e., to refer to the same type of problem. Moreover, MTL is usually based on ground truth annotations with full, or partial overlap across tasks. In this work, we deal with heterogeneous MTL, simultaneously addressing detection, classification & regression problems. We explore task-relatedness as a means for co-training, in a weakly-supervised way, tasks that contain little, or even non-overlapping annotations. Task-relatedness is introduced in MTL, either explicitly through prior expert knowledge, or through data-driven studies. We propose a novel distribution matching approach, in which knowledge exchange is enabled between tasks, via matching of their predictions' distributions. Based on this approach, we build FaceBehaviorNet, the first framework for large-scale face analysis, by jointly learning all facial behavior tasks. We develop case studies for: i) continuous affect estimation, action unit detection, basic emotion recognition; ii) attribute detection, face identification. We illustrate that co-training via task relatedness alleviates negative transfer. Since FaceBehaviorNet learns features that encapsulate all aspects of facial behavior, we conduct zero-/few-shot learning to perform tasks beyond the ones that it has been trained for, such as compound emotion recognition. By conducting a very large experimental study, utilizing 10 databases, we illustrate that our approach outperforms, by large margins, the state-of-the-art in all tasks and in all databases, even in these which have not been used in its training.
Head2HeadFS: Video-based Head Reenactment with Few-shot Learning
Mar 30, 2021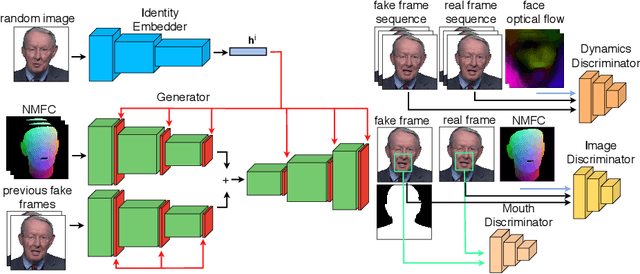
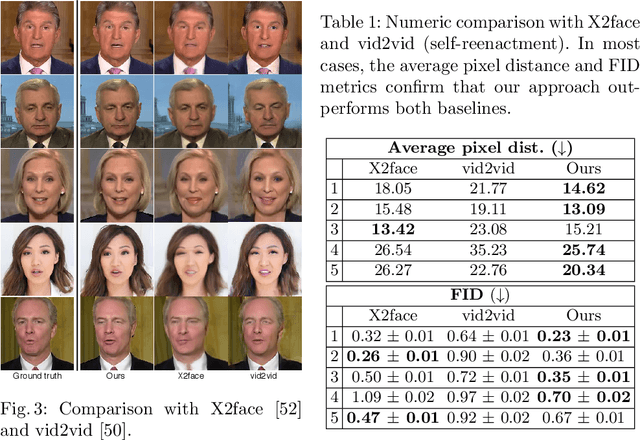


Over the past years, a substantial amount of work has been done on the problem of facial reenactment, with the solutions coming mainly from the graphics community. Head reenactment is an even more challenging task, which aims at transferring not only the facial expression, but also the entire head pose from a source person to a target. Current approaches either train person-specific systems, or use facial landmarks to model human heads, a representation that might transfer unwanted identity attributes from the source to the target. We propose head2headFS, a novel easily adaptable pipeline for head reenactment. We condition synthesis of the target person on dense 3D face shape information from the source, which enables high quality expression and pose transfer. Our video-based rendering network is fine-tuned under a few-shot learning strategy, using only a few samples. This allows for fast adaptation of a generic generator trained on a multiple-person dataset, into a person-specific one.
HeadGAN: Video-and-Audio-Driven Talking Head Synthesis
Dec 15, 2020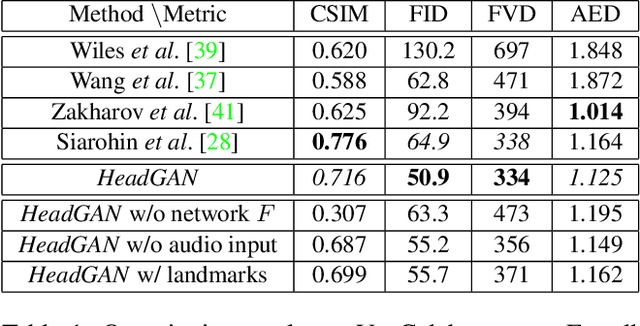
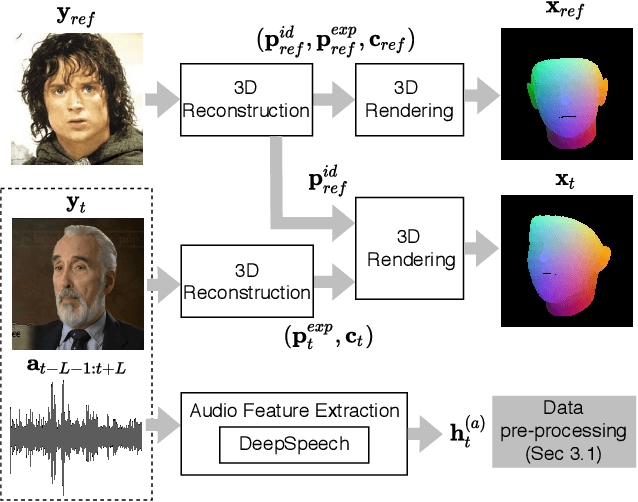
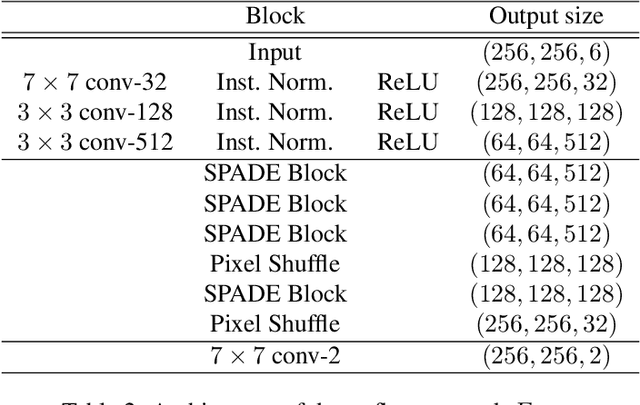
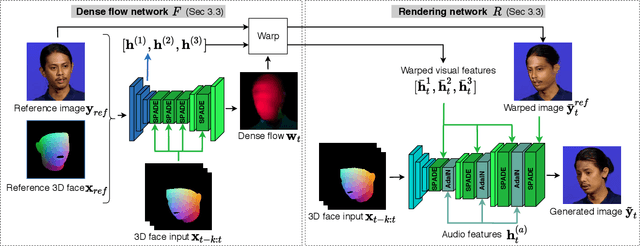
Recent attempts to solve the problem of talking head synthesis using a single reference image have shown promising results. However, most of them fail to meet the identity preservation problem, or perform poorly in terms of photo-realism, especially in extreme head poses. We propose HeadGAN, a novel reenactment approach that conditions synthesis on 3D face representations, which can be extracted from any driving video and adapted to the facial geometry of any source. We improve the plausibility of mouth movements, by utilising audio features as a complementary input to the Generator. Quantitative and qualitative experiments demonstrate the merits of our approach.