 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAD-3DHeads: A Large-scale Dense, Accurate and Diverse Dataset for 3D Head Alignment from a Single Image
Apr 11, 2022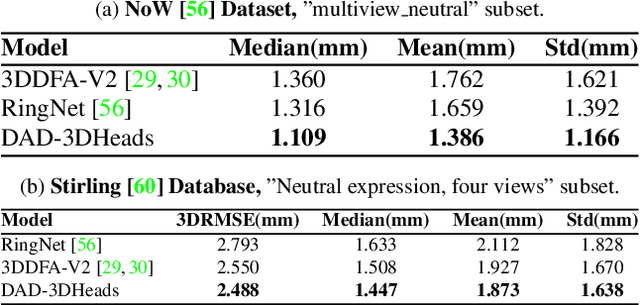
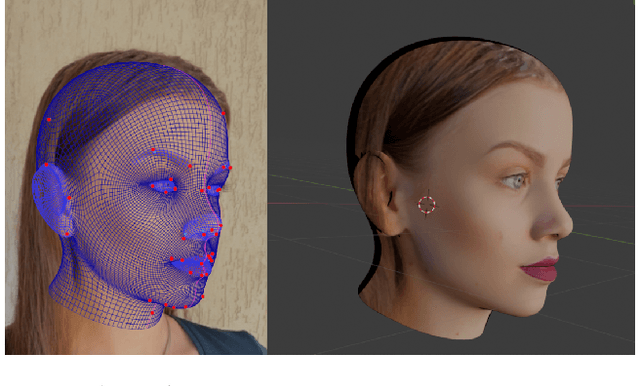
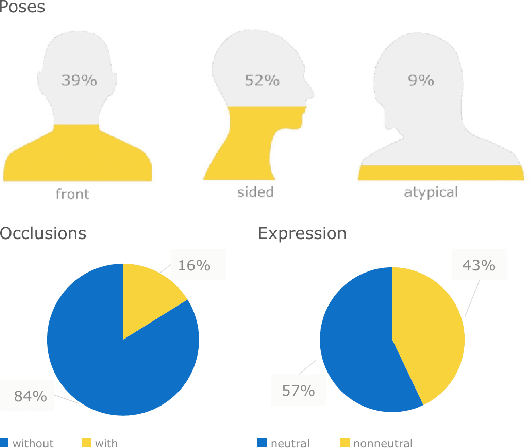
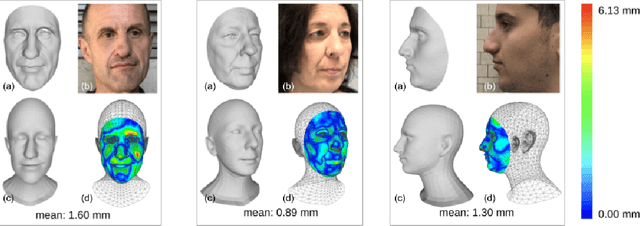
We present DAD-3DHeads, a dense and diverse large-scale dataset, and a robust model for 3D Dense Head Alignment in the wild. It contains annotations of over 3.5K landmarks that accurately represent 3D head shape compared to the ground-truth scans. The data-driven model, DAD-3DNet, trained on our dataset, learns shape, expression, and pose parameters, and performs 3D reconstruction of a FLAME mesh. The model also incorporates a landmark prediction branch to take advantage of rich supervision and co-training of multiple related tasks. Experimentally, DAD-3DNet outperforms or is comparable to the state-of-the-art models in (i) 3D Head Pose Estimation on AFLW2000-3D and BIWI, (ii) 3D Face Shape Reconstruction on NoW and Feng, and (iii) 3D Dense Head Alignment and 3D Landmarks Estimation on DAD-3DHeads dataset. Finally, the diversity of DAD-3DHeads in camera angles, facial expressions, and occlusions enables a benchmark to study in-the-wild generalization and robustness to distribution shifts. The dataset webpage is https://p.farm/research/dad-3dheads.
FEAR: Fast, Efficient, Accurate and Robust Visual Tracker
Dec 15, 2021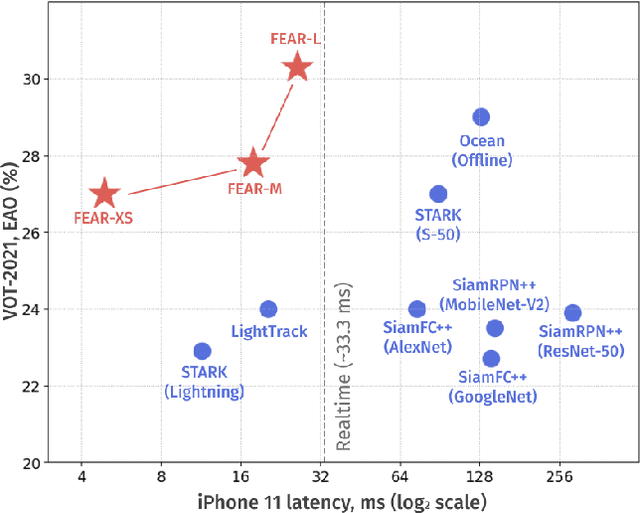

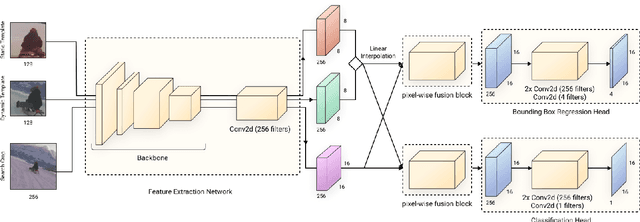

We present FEAR, a novel, fast, efficient, accurate, and robust Siamese visual tracker. We introduce an architecture block for object model adaption, called dual-template representation, and a pixel-wise fusion block to achieve extra flexibility and efficiency of the model. The dual-template module incorporates temporal information with only a single learnable parameter, while the pixel-wise fusion block encodes more discriminative features with fewer parameters compared to standard correlation modules. By plugging-in sophisticated backbones with the novel modules, FEAR-M and FEAR-L trackers surpass most Siamesetrackers on several academic benchmarks in both accuracy and efficiencies. Employed with the lightweight backbone, the optimized version FEAR-XS offers more than 10 times faster tracking than current Siamese trackers while maintaining near state-of-the-art results. FEAR-XS tracker is 2.4x smaller and 4.3x faster than LightTrack [62] with superior accuracy. In addition, we expand the definition of the model efficiency by introducing a benchmark on energy consumption and execution speed. Source code, pre-trained models, and evaluation protocol will be made available upon request
Robust Audio-Based Vehicle Counting in Low-to-Moderate Traffic Flow
Oct 22, 2020
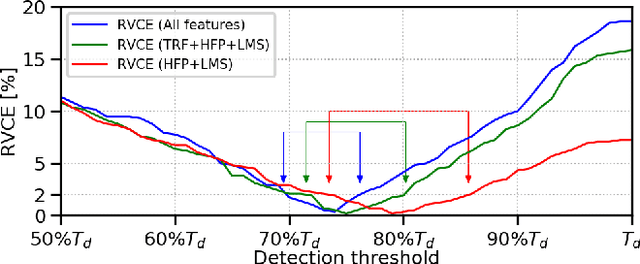
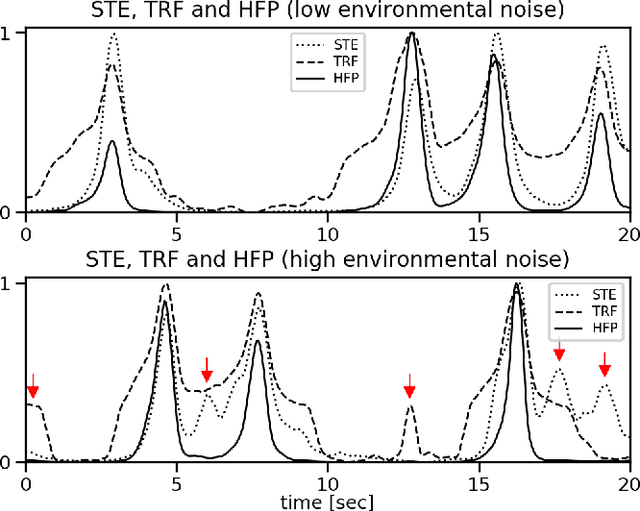
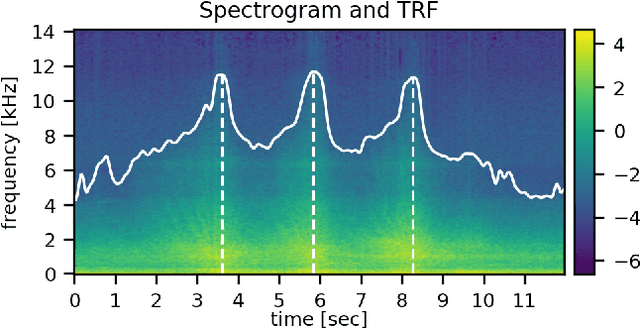
The paper presents a method for audio-based vehicle counting (VC) in low-to-moderate traffic using one-channel sound. We formulate VC as a regression problem, i.e., we predict the distance between a vehicle and the microphone. Minima of the proposed distance function correspond to vehicles passing by the microphone. VC is carried out via local minima detection in the predicted distance. We propose to set the minima detection threshold at a point where the probabilities of false positives and false negatives coincide so they statistically cancel each other in total vehicle number. The method is trained and tested on a traffic-monitoring dataset comprising $422$ short, $20$-second one-channel sound files with a total of $ 1421 $ vehicles passing by the microphone. Relative VC error in a traffic location not used in the training is below $ 2 \%$ within a wide range of detection threshold values. Experimental results show that the regression accuracy in noisy environments is improved by introducing a novel high-frequency power feature.
Neural Network-based Acoustic Vehicle Counting
Oct 22, 2020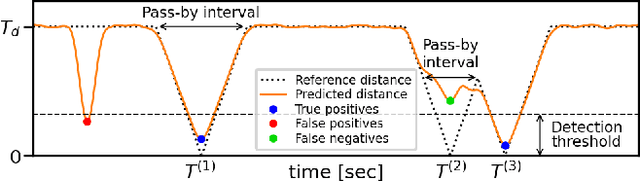

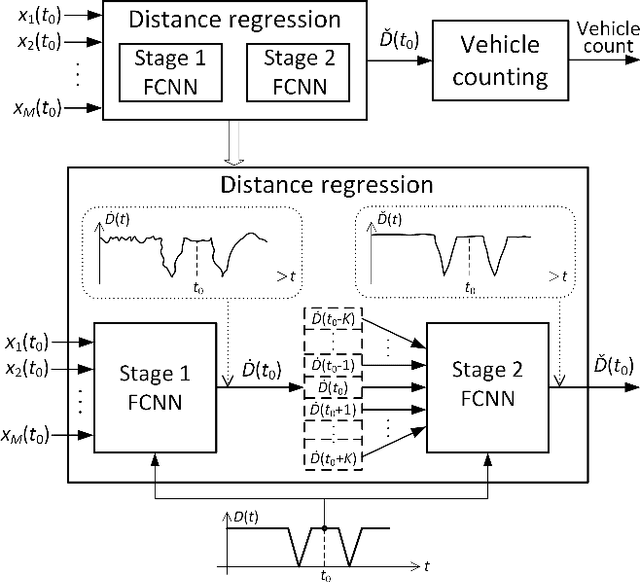
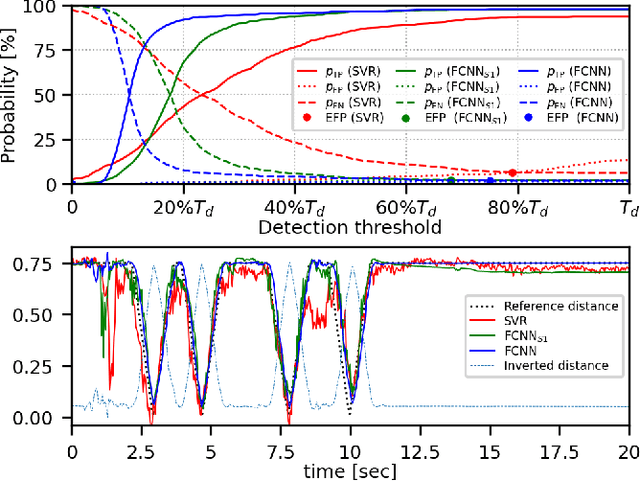
This paper addresses acoustic vehicle counting using one-channel audio. We predict the pass-by instants of vehicles from local minima of a vehicle-to-microphone distance predicted from audio. The distance is predicted via a two-stage (coarse-fine) regression, both realised using neural networks (NNs). Experiments show that the NN-based distance regression outperforms by far the previously proposed support vector regression. The $ 95\% $ confidence interval for the mean of vehicle counting error is within $[0.28\%, -0.55\%]$. Besides the minima-based counting, we propose a deep learning counting which operates on the predicted distance without detecting local minima. Results also show that removing low frequencies in features improves the counting performance.
ALFA: Agglomerative Late Fusion Algorithm for Object Detection
Jul 13, 2019
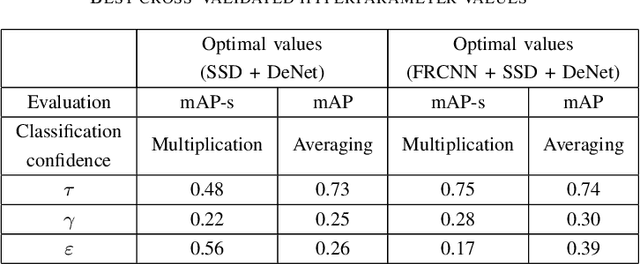
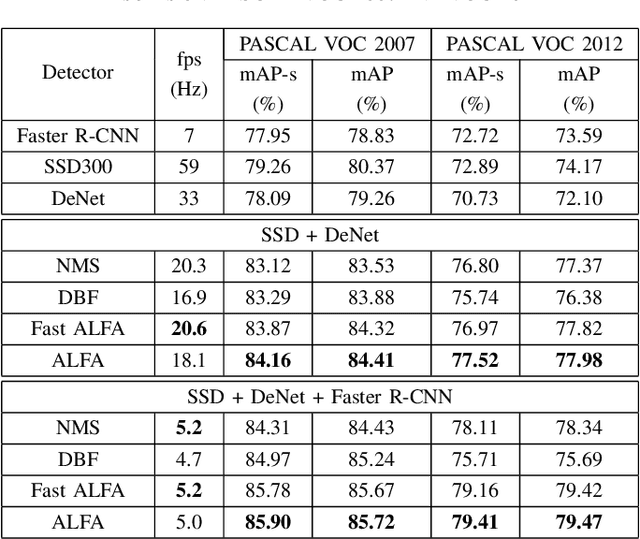
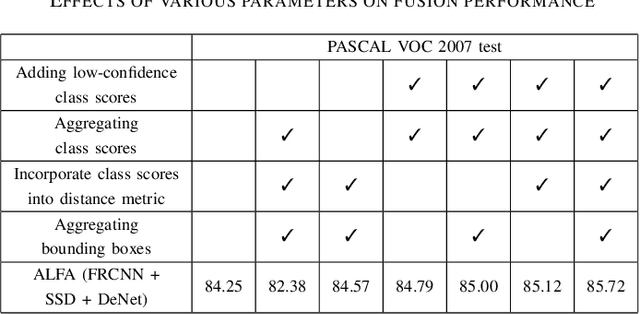
We propose ALFA - a novel late fusion algorithm for object detection. ALFA is based on agglomerative clustering of object detector predictions taking into consideration both the bounding box locations and the class scores. Each cluster represents a single object hypothesis whose location is a weighted combination of the clustered bounding boxes. ALFA was evaluated using combinations of a pair (SSD and DeNet) and a triplet (SSD, DeNet and Faster R-CNN) of recent object detectors that are close to the state-of-the-art. ALFA achieves state of the art results on PASCAL VOC 2007 and PASCAL VOC 2012, outperforming the individual detectors as well as baseline combination strategies, achieving up to 32% lower error than the best individual detectors and up to 6% lower error than the reference fusion algorithm DBF - Dynamic Belief Fusion.