 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseDreamer: Scalable and Photorealistic Human Data Generation Pipeline with Diffusion Models
Mar 30, 2026Acquiring labeled datasets for 3D human mesh estimation is challenging due to depth ambiguities and the inherent difficulty of annotating 3D geometry from monocular images. Existing datasets are either real, with manually annotated 3D geometry and limited scale, or synthetic, rendered from 3D engines that provide precise labels but suffer from limited photorealism, low diversity, and high production costs. In this work, we explore a third path: generated data. We introduce PoseDreamer, a novel pipeline that leverages diffusion models to generate large-scale synthetic datasets with 3D mesh annotations. Our approach combines controllable image generation with Direct Preference Optimization for control alignment, curriculum-based hard sample mining, and multi-stage quality filtering. Together, these components naturally maintain correspondence between 3D labels and generated images, while prioritizing challenging samples to maximize dataset utility. Using PoseDreamer, we generate more than 500,000 high-quality synthetic samples, achieving a 76% improvement in image-quality metrics compared to rendering-based datasets. Models trained on PoseDreamer achieve performance comparable to or superior to those trained on real-world and traditional synthetic datasets. In addition, combining PoseDreamer with synthetic datasets results in better performance than combining real-world and synthetic datasets, demonstrating the complementary nature of our dataset. We will release the full dataset and generation code.
VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
Mar 27, 2026Large-scale video diffusion models achieve impressive visual quality, yet often fail to preserve geometric consistency. Prior approaches improve consistency either by augmenting the generator with additional modules or applying geometry-aware alignment. However, architectural modifications can compromise the generalization of internet-scale pretrained models, while existing alignment methods are limited to static scenes and rely on RGB-space rewards that require repeated VAE decoding, incurring substantial compute overhead and failing to generalize to highly dynamic real-world scenes. To preserve the pretrained capacity while improving geometric consistency, we propose VGGRPO (Visual Geometry GRPO), a latent geometry-guided framework for geometry-aware video post-training. VGGRPO introduces a Latent Geometry Model (LGM) that stitches video diffusion latents to geometry foundation models, enabling direct decoding of scene geometry from the latent space. By constructing LGM from a geometry model with 4D reconstruction capability, VGGRPO naturally extends to dynamic scenes, overcoming the static-scene limitations of prior methods. Building on this, we perform latent-space Group Relative Policy Optimization with two complementary rewards: a camera motion smoothness reward that penalizes jittery trajectories, and a geometry reprojection consistency reward that enforces cross-view geometric coherence. Experiments on both static and dynamic benchmarks show that VGGRPO improves camera stability, geometry consistency, and overall quality while eliminating costly VAE decoding, making latent-space geometry-guided reinforcement an efficient and flexible approach to world-consistent video generation.
Epipolar Geometry Improves Video Generation Models
Oct 24, 2025Video generation models have progressed tremendously through large latent diffusion transformers trained with rectified flow techniques. Yet these models still struggle with geometric inconsistencies, unstable motion, and visual artifacts that break the illusion of realistic 3D scenes. 3D-consistent video generation could significantly impact numerous downstream applications in generation and reconstruction tasks. We explore how epipolar geometry constraints improve modern video diffusion models. Despite massive training data, these models fail to capture fundamental geometric principles underlying visual content. We align diffusion models using pairwise epipolar geometry constraints via preference-based optimization, directly addressing unstable camera trajectories and geometric artifacts through mathematically principled geometric enforcement. Our approach efficiently enforces geometric principles without requiring end-to-end differentiability. Evaluation demonstrates that classical geometric constraints provide more stable optimization signals than modern learned metrics, which produce noisy targets that compromise alignment quality. Training on static scenes with dynamic cameras ensures high-quality measurements while the model generalizes effectively to diverse dynamic content. By bridging data-driven deep learning with classical geometric computer vision, we present a practical method for generating spatially consistent videos without compromising visual quality.
S3OD: Towards Generalizable Salient Object Detection with Synthetic Data
Oct 24, 2025Salient object detection exemplifies data-bounded tasks where expensive pixel-precise annotations force separate model training for related subtasks like DIS and HR-SOD. We present a method that dramatically improves generalization through large-scale synthetic data generation and ambiguity-aware architecture. We introduce S3OD, a dataset of over 139,000 high-resolution images created through our multi-modal diffusion pipeline that extracts labels from diffusion and DINO-v3 features. The iterative generation framework prioritizes challenging categories based on model performance. We propose a streamlined multi-mask decoder that naturally handles the inherent ambiguity in salient object detection by predicting multiple valid interpretations. Models trained solely on synthetic data achieve 20-50% error reduction in cross-dataset generalization, while fine-tuned versions reach state-of-the-art performance across DIS and HR-SOD benchmarks.
VGGHeads: A Large-Scale Synthetic Dataset for 3D Human Heads
Jul 25, 2024



Human head detection, keypoint estimation, and 3D head model fitting are important tasks with many applications. However, traditional real-world datasets often suffer from bias, privacy, and ethical concerns, and they have been recorded in laboratory environments, which makes it difficult for trained models to generalize. Here, we introduce VGGHeads -- a large scale synthetic dataset generated with diffusion models for human head detection and 3D mesh estimation. Our dataset comprises over 1 million high-resolution images, each annotated with detailed 3D head meshes, facial landmarks, and bounding boxes. Using this dataset we introduce a new model architecture capable of simultaneous heads detection and head meshes reconstruction from a single image in a single step. Through extensive experimental evaluations, we demonstrate that models trained on our synthetic data achieve strong performance on real images. Furthermore, the versatility of our dataset makes it applicable across a broad spectrum of tasks, offering a general and comprehensive representation of human heads. Additionally, we provide detailed information about the synthetic data generation pipeline, enabling it to be re-used for other tasks and domains.
Dataset Enhancement with Instance-Level Augmentations
Jun 12, 2024



We present a method for expanding a dataset by incorporating knowledge from the wide distribution of pre-trained latent diffusion models. Data augmentations typically incorporate inductive biases about the image formation process into the training (e.g. translation, scaling, colour changes, etc.). Here, we go beyond simple pixel transformations and introduce the concept of instance-level data augmentation by repainting parts of the image at the level of object instances. The method combines a conditional diffusion model with depth and edge maps control conditioning to seamlessly repaint individual objects inside the scene, being applicable to any segmentation or detection dataset. Used as a data augmentation method, it improves the performance and generalization of the state-of-the-art salient object detection, semantic segmentation and object detection models. By redrawing all privacy-sensitive instances (people, license plates, etc.), the method is also applicable for data anonymization. We also release fully synthetic and anonymized expansions for popular datasets: COCO, Pascal VOC and DUTS.
DAD-3DHeads: A Large-scale Dense, Accurate and Diverse Dataset for 3D Head Alignment from a Single Image
Apr 11, 2022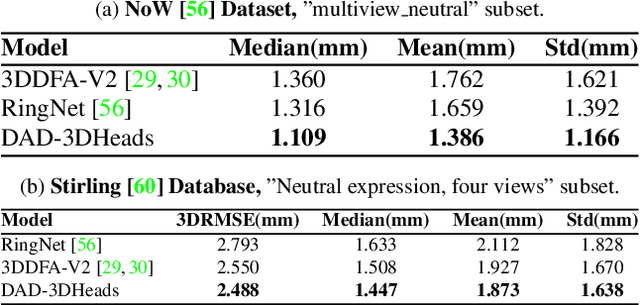
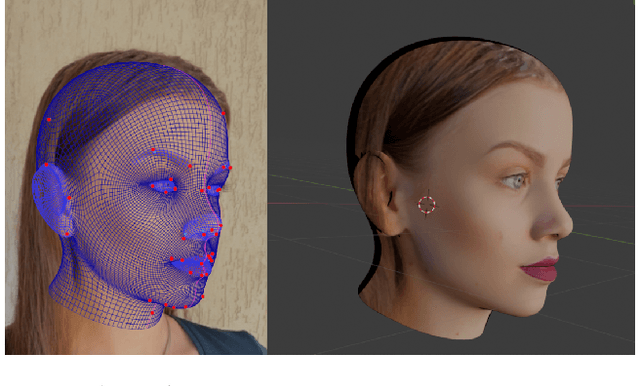
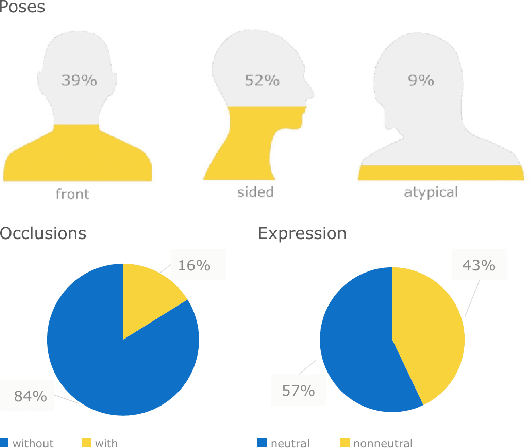
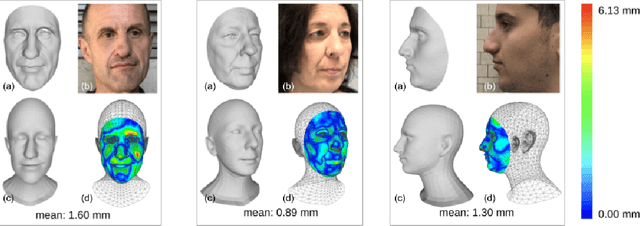
We present DAD-3DHeads, a dense and diverse large-scale dataset, and a robust model for 3D Dense Head Alignment in the wild. It contains annotations of over 3.5K landmarks that accurately represent 3D head shape compared to the ground-truth scans. The data-driven model, DAD-3DNet, trained on our dataset, learns shape, expression, and pose parameters, and performs 3D reconstruction of a FLAME mesh. The model also incorporates a landmark prediction branch to take advantage of rich supervision and co-training of multiple related tasks. Experimentally, DAD-3DNet outperforms or is comparable to the state-of-the-art models in (i) 3D Head Pose Estimation on AFLW2000-3D and BIWI, (ii) 3D Face Shape Reconstruction on NoW and Feng, and (iii) 3D Dense Head Alignment and 3D Landmarks Estimation on DAD-3DHeads dataset. Finally, the diversity of DAD-3DHeads in camera angles, facial expressions, and occlusions enables a benchmark to study in-the-wild generalization and robustness to distribution shifts. The dataset webpage is https://p.farm/research/dad-3dheads.
FEAR: Fast, Efficient, Accurate and Robust Visual Tracker
Dec 15, 2021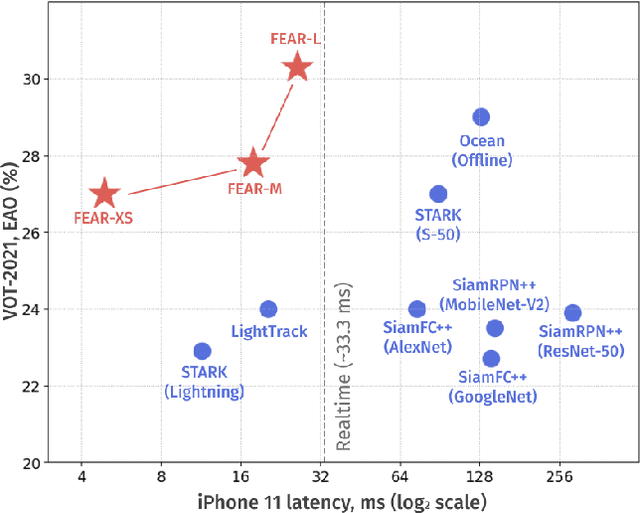

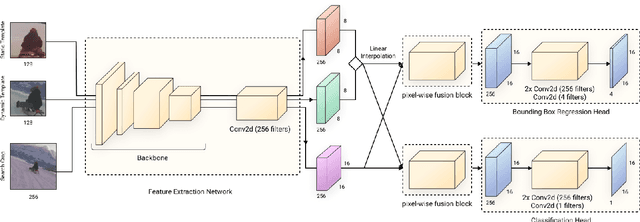

We present FEAR, a novel, fast, efficient, accurate, and robust Siamese visual tracker. We introduce an architecture block for object model adaption, called dual-template representation, and a pixel-wise fusion block to achieve extra flexibility and efficiency of the model. The dual-template module incorporates temporal information with only a single learnable parameter, while the pixel-wise fusion block encodes more discriminative features with fewer parameters compared to standard correlation modules. By plugging-in sophisticated backbones with the novel modules, FEAR-M and FEAR-L trackers surpass most Siamesetrackers on several academic benchmarks in both accuracy and efficiencies. Employed with the lightweight backbone, the optimized version FEAR-XS offers more than 10 times faster tracking than current Siamese trackers while maintaining near state-of-the-art results. FEAR-XS tracker is 2.4x smaller and 4.3x faster than LightTrack [62] with superior accuracy. In addition, we expand the definition of the model efficiency by introducing a benchmark on energy consumption and execution speed. Source code, pre-trained models, and evaluation protocol will be made available upon request
ActGAN: Flexible and Efficient One-shot Face Reenactment
Mar 30, 2020
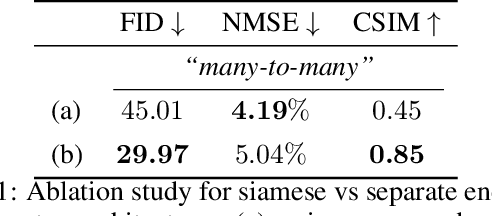
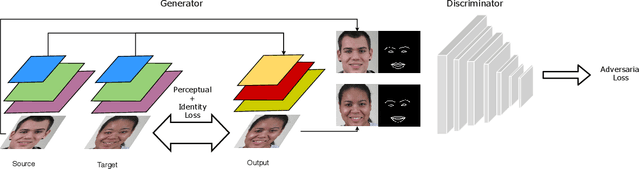

This paper introduces ActGAN - a novel end-to-end generative adversarial network (GAN) for one-shot face reenactment. Given two images, the goal is to transfer the facial expression of the source actor onto a target person in a photo-realistic fashion. While existing methods require target identity to be predefined, we address this problem by introducing a "many-to-many" approach, which allows arbitrary persons both for source and target without additional retraining. To this end, we employ the Feature Pyramid Network (FPN) as a core generator building block - the first application of FPN in face reenactment, producing finer results. We also introduce a solution to preserve a person's identity between synthesized and target person by adopting the state-of-the-art approach in deep face recognition domain. The architecture readily supports reenactment in different scenarios: "many-to-many", "one-to-one", "one-to-another" in terms of expression accuracy, identity preservation, and overall image quality. We demonstrate that ActGAN achieves competitive performance against recent works concerning visual quality.
Fast and Efficient Model for Real-Time Tiger Detection In The Wild
Sep 03, 2019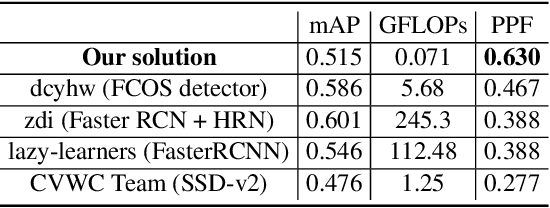
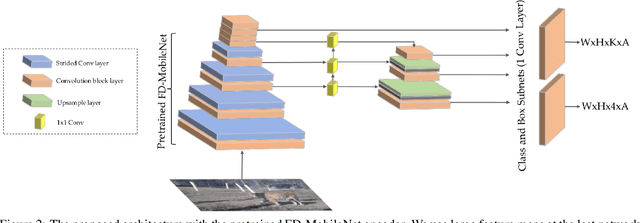


The highest accuracy object detectors to date are based either on a two-stage approach such as Fast R-CNN or one-stage detectors such as Retina-Net or SSD with deep and complex backbones. In this paper we present TigerNet - simple yet efficient FPN based network architecture for Amur Tiger Detection in the wild. The model has 600k parameters, requires 0.071 GFLOPs per image and can run on the edge devices (smart cameras) in near real time. In addition, we introduce a two-stage semi-supervised learning via pseudo-labelling learning approach to distill the knowledge from the larger networks. For ATRW-ICCV 2019 tiger detection sub-challenge, based on public leaderboard score, our approach shows superior performance in comparison to other methods.