 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Easy Boosts for Lidar Semantic Scene Completion
Jun 02, 2026This paper investigates "free lunch" strategies to boost the performance of lidar semantic scene completion (SSC) without requiring complex architectural redesigns. We first demonstrate that endowing input point clouds with semantic pseudo-labels from off-the-shelf segmentors significantly improves the performance of existing architectures. By evaluating these models against an oracle, we establish that high-quality semantic priors are a primary driver of mIoU gains. Furthermore, we equip the input lidar scan with visibility information that distinguishes between empty and unknown spaces, which provides a secondary performance boost across the tested architectures. Using these simple enhancements, we observe that older models remain competitive with state-of-the-art systems, and can even outperform them. Our code is available at https://github.com/astra-vision/SSC-Priors.
LiDPM: Rethinking Point Diffusion for Lidar Scene Completion
Apr 24, 2025Training diffusion models that work directly on lidar points at the scale of outdoor scenes is challenging due to the difficulty of generating fine-grained details from white noise over a broad field of view. The latest works addressing scene completion with diffusion models tackle this problem by reformulating the original DDPM as a local diffusion process. It contrasts with the common practice of operating at the level of objects, where vanilla DDPMs are currently used. In this work, we close the gap between these two lines of work. We identify approximations in the local diffusion formulation, show that they are not required to operate at the scene level, and that a vanilla DDPM with a well-chosen starting point is enough for completion. Finally, we demonstrate that our method, LiDPM, leads to better results in scene completion on SemanticKITTI. The project page is https://astra-vision.github.io/LiDPM .
DAD-3DHeads: A Large-scale Dense, Accurate and Diverse Dataset for 3D Head Alignment from a Single Image
Apr 11, 2022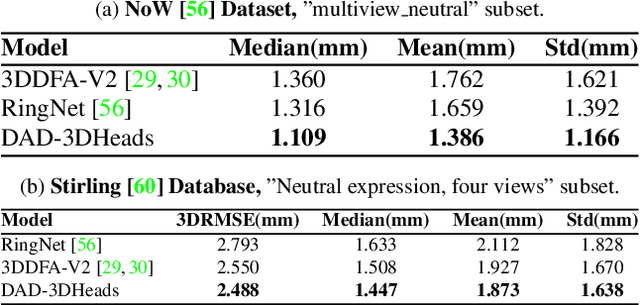
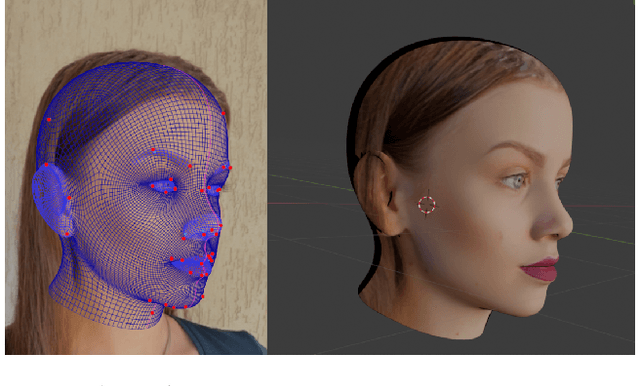
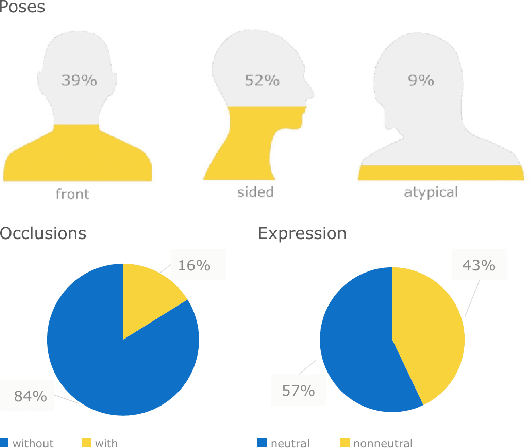
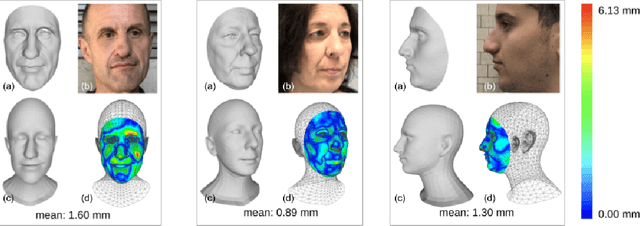
We present DAD-3DHeads, a dense and diverse large-scale dataset, and a robust model for 3D Dense Head Alignment in the wild. It contains annotations of over 3.5K landmarks that accurately represent 3D head shape compared to the ground-truth scans. The data-driven model, DAD-3DNet, trained on our dataset, learns shape, expression, and pose parameters, and performs 3D reconstruction of a FLAME mesh. The model also incorporates a landmark prediction branch to take advantage of rich supervision and co-training of multiple related tasks. Experimentally, DAD-3DNet outperforms or is comparable to the state-of-the-art models in (i) 3D Head Pose Estimation on AFLW2000-3D and BIWI, (ii) 3D Face Shape Reconstruction on NoW and Feng, and (iii) 3D Dense Head Alignment and 3D Landmarks Estimation on DAD-3DHeads dataset. Finally, the diversity of DAD-3DHeads in camera angles, facial expressions, and occlusions enables a benchmark to study in-the-wild generalization and robustness to distribution shifts. The dataset webpage is https://p.farm/research/dad-3dheads.
FEAR: Fast, Efficient, Accurate and Robust Visual Tracker
Dec 15, 2021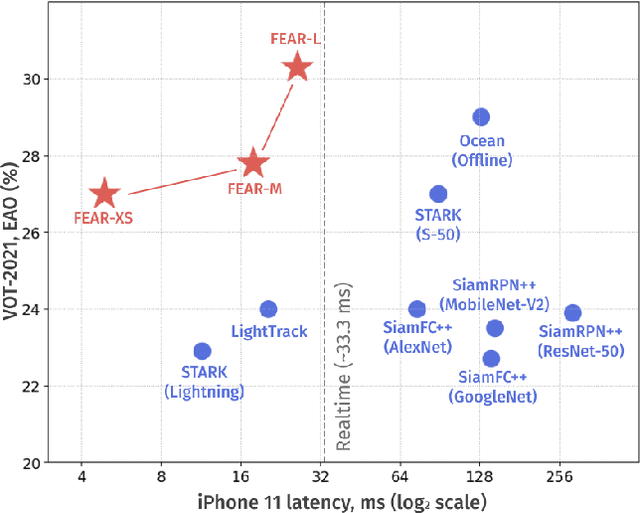

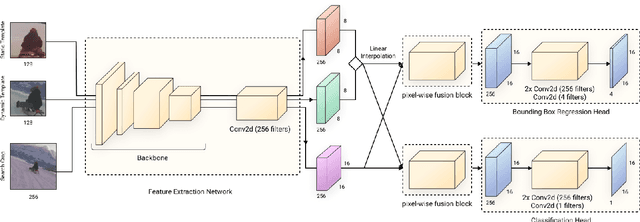

We present FEAR, a novel, fast, efficient, accurate, and robust Siamese visual tracker. We introduce an architecture block for object model adaption, called dual-template representation, and a pixel-wise fusion block to achieve extra flexibility and efficiency of the model. The dual-template module incorporates temporal information with only a single learnable parameter, while the pixel-wise fusion block encodes more discriminative features with fewer parameters compared to standard correlation modules. By plugging-in sophisticated backbones with the novel modules, FEAR-M and FEAR-L trackers surpass most Siamesetrackers on several academic benchmarks in both accuracy and efficiencies. Employed with the lightweight backbone, the optimized version FEAR-XS offers more than 10 times faster tracking than current Siamese trackers while maintaining near state-of-the-art results. FEAR-XS tracker is 2.4x smaller and 4.3x faster than LightTrack [62] with superior accuracy. In addition, we expand the definition of the model efficiency by introducing a benchmark on energy consumption and execution speed. Source code, pre-trained models, and evaluation protocol will be made available upon request
DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better
Aug 10, 2019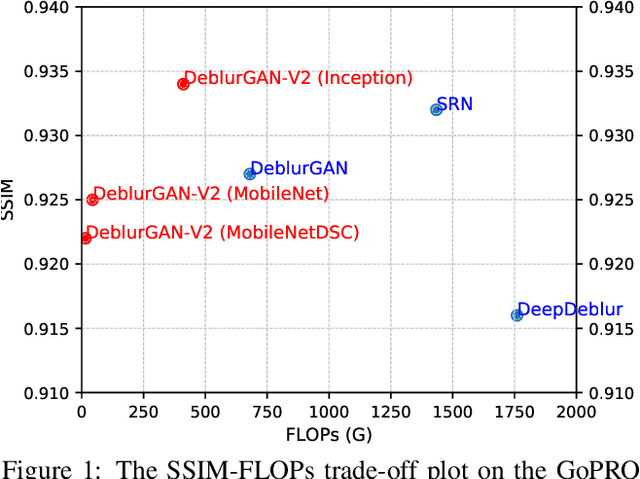

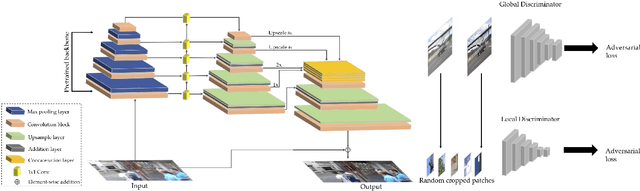

We present a new end-to-end generative adversarial network (GAN) for single image motion deblurring, named DeblurGAN-v2, which considerably boosts state-of-the-art deblurring efficiency, quality, and flexibility. DeblurGAN-v2 is based on a relativistic conditional GAN with a double-scale discriminator. For the first time, we introduce the Feature Pyramid Network into deblurring, as a core building block in the generator of DeblurGAN-v2. It can flexibly work with a wide range of backbones, to navigate the balance between performance and efficiency. The plug-in of sophisticated backbones (e.g., Inception-ResNet-v2) can lead to solid state-of-the-art deblurring. Meanwhile, with light-weight backbones (e.g., MobileNet and its variants), DeblurGAN-v2 reaches 10-100 times faster than the nearest competitors, while maintaining close to state-of-the-art results, implying the option of real-time video deblurring. We demonstrate that DeblurGAN-v2 obtains very competitive performance on several popular benchmarks, in terms of deblurring quality (both objective and subjective), as well as efficiency. Besides, we show the architecture to be effective for general image restoration tasks too. Our codes, models and data are available at: https://github.com/KupynOrest/DeblurGANv2