 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal system for skin cancer detection
Jan 21, 2026Melanoma detection is vital for early diagnosis and effective treatment. While deep learning models on dermoscopic images have shown promise, they require specialized equipment, limiting their use in broader clinical settings. This study introduces a multi-modal melanoma detection system using conventional photo images, making it more accessible and versatile. Our system integrates image data with tabular metadata, such as patient demographics and lesion characteristics, to improve detection accuracy. It employs a multi-modal neural network combining image and metadata processing and supports a two-step model for cases with or without metadata. A three-stage pipeline further refines predictions by boosting algorithms and enhancing performance. To address the challenges of a highly imbalanced dataset, specific techniques were implemented to ensure robust training. An ablation study evaluated recent vision architectures, boosting algorithms, and loss functions, achieving a peak Partial ROC AUC of 0.18068 (0.2 maximum) and top-15 retrieval sensitivity of 0.78371. Results demonstrate that integrating photo images with metadata in a structured, multi-stage pipeline yields significant performance improvements. This system advances melanoma detection by providing a scalable, equipment-independent solution suitable for diverse healthcare environments, bridging the gap between specialized and general clinical practices.
Semi-Supervised Segmentation of Functional Tissue Units at the Cellular Level
May 03, 2023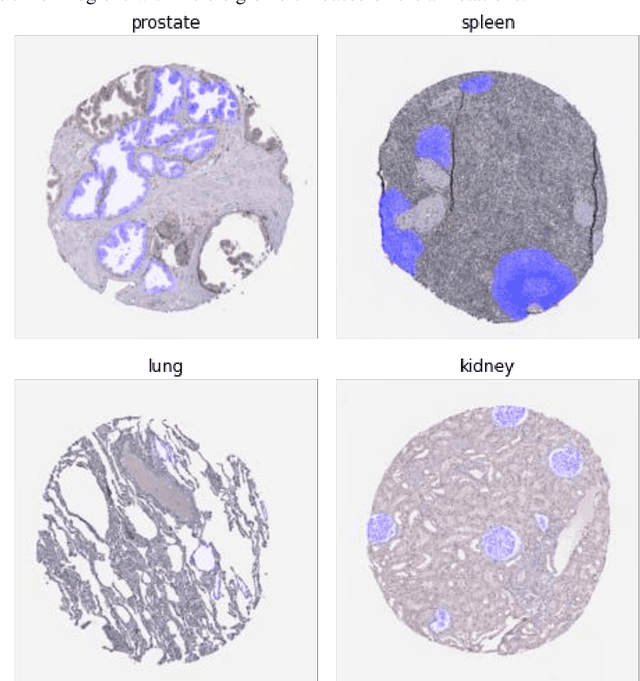


We present a new method for functional tissue unit segmentation at the cellular level, which utilizes the latest deep learning semantic segmentation approaches together with domain adaptation and semi-supervised learning techniques. This approach allows for minimizing the domain gap, class imbalance, and captures settings influence between HPA and HubMAP datasets. The presented approach achieves comparable with state-of-the-art-result in functional tissue unit segmentation at the cellular level. The source code is available at https://github.com/VSydorskyy/hubmap_2022_htt_solution
DAD-3DHeads: A Large-scale Dense, Accurate and Diverse Dataset for 3D Head Alignment from a Single Image
Apr 11, 2022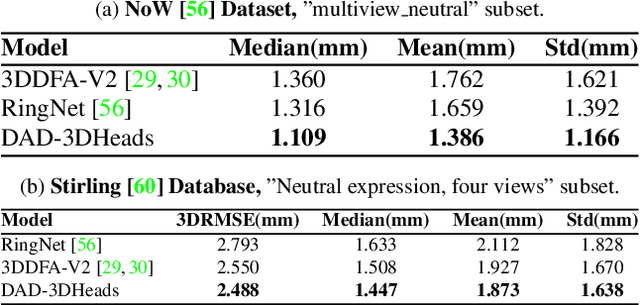
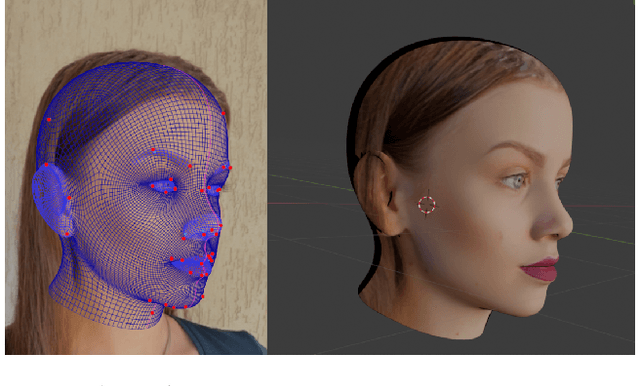
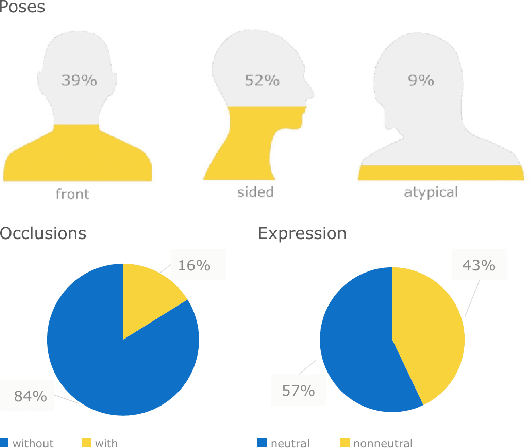
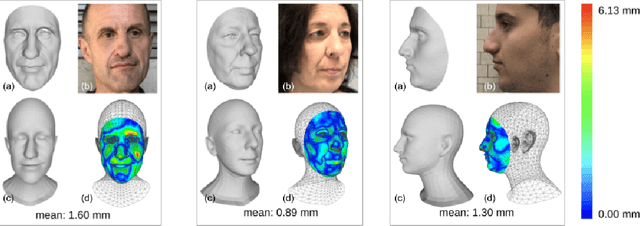
We present DAD-3DHeads, a dense and diverse large-scale dataset, and a robust model for 3D Dense Head Alignment in the wild. It contains annotations of over 3.5K landmarks that accurately represent 3D head shape compared to the ground-truth scans. The data-driven model, DAD-3DNet, trained on our dataset, learns shape, expression, and pose parameters, and performs 3D reconstruction of a FLAME mesh. The model also incorporates a landmark prediction branch to take advantage of rich supervision and co-training of multiple related tasks. Experimentally, DAD-3DNet outperforms or is comparable to the state-of-the-art models in (i) 3D Head Pose Estimation on AFLW2000-3D and BIWI, (ii) 3D Face Shape Reconstruction on NoW and Feng, and (iii) 3D Dense Head Alignment and 3D Landmarks Estimation on DAD-3DHeads dataset. Finally, the diversity of DAD-3DHeads in camera angles, facial expressions, and occlusions enables a benchmark to study in-the-wild generalization and robustness to distribution shifts. The dataset webpage is https://p.farm/research/dad-3dheads.
FEAR: Fast, Efficient, Accurate and Robust Visual Tracker
Dec 15, 2021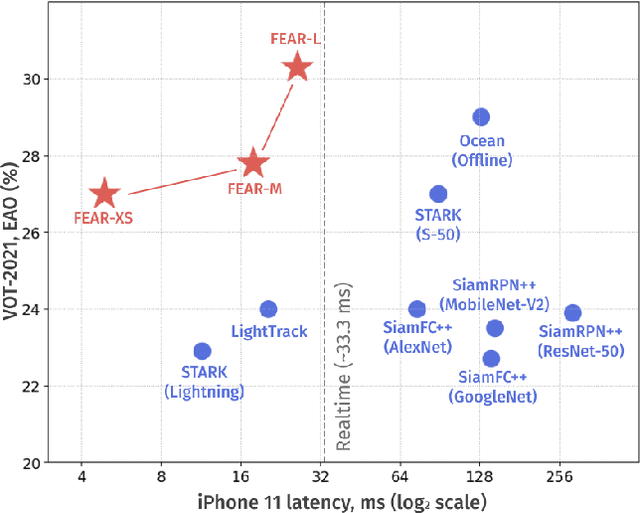

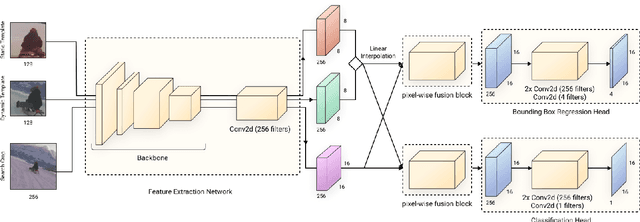

We present FEAR, a novel, fast, efficient, accurate, and robust Siamese visual tracker. We introduce an architecture block for object model adaption, called dual-template representation, and a pixel-wise fusion block to achieve extra flexibility and efficiency of the model. The dual-template module incorporates temporal information with only a single learnable parameter, while the pixel-wise fusion block encodes more discriminative features with fewer parameters compared to standard correlation modules. By plugging-in sophisticated backbones with the novel modules, FEAR-M and FEAR-L trackers surpass most Siamesetrackers on several academic benchmarks in both accuracy and efficiencies. Employed with the lightweight backbone, the optimized version FEAR-XS offers more than 10 times faster tracking than current Siamese trackers while maintaining near state-of-the-art results. FEAR-XS tracker is 2.4x smaller and 4.3x faster than LightTrack [62] with superior accuracy. In addition, we expand the definition of the model efficiency by introducing a benchmark on energy consumption and execution speed. Source code, pre-trained models, and evaluation protocol will be made available upon request