 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Decoder-Based Language Models for Diverse Encoder Downstream Tasks
Mar 04, 2025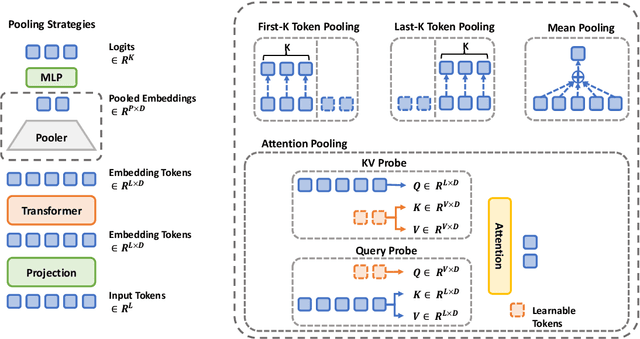
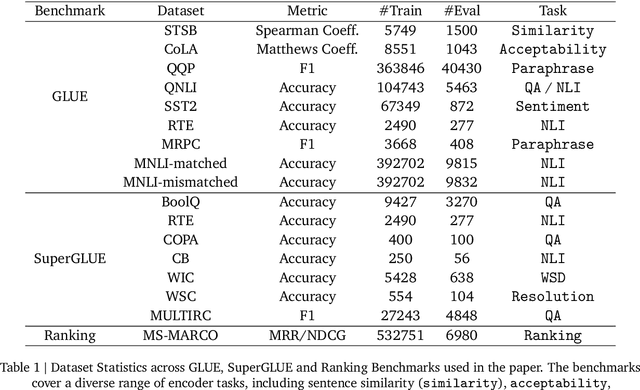
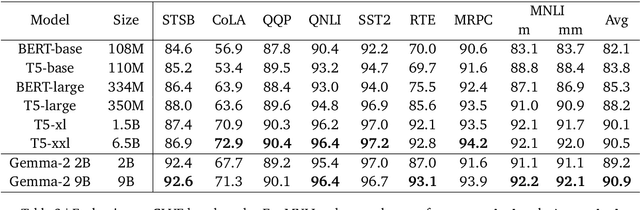
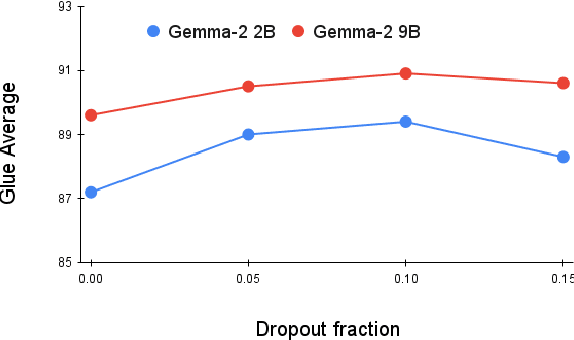
Decoder-based transformers, while revolutionizing language modeling and scaling to immense sizes, have not completely overtaken encoder-heavy architectures in natural language processing. Specifically, encoder-only models remain dominant in tasks like classification, regression, and ranking. This is primarily due to the inherent structure of decoder-based models, which limits their direct applicability to these tasks. In this paper, we introduce Gemma Encoder, adapting the powerful Gemma decoder model to an encoder architecture, thereby unlocking its potential for a wider range of non-generative applications. To optimize the adaptation from decoder to encoder, we systematically analyze various pooling strategies, attention mechanisms, and hyperparameters (e.g., dropout rate). Furthermore, we benchmark Gemma Encoder against established approaches on the GLUE benchmarks, and MS MARCO ranking benchmark, demonstrating its effectiveness and versatility.
LAMPO: Large Language Models as Preference Machines for Few-shot Ordinal Classification
Aug 06, 2024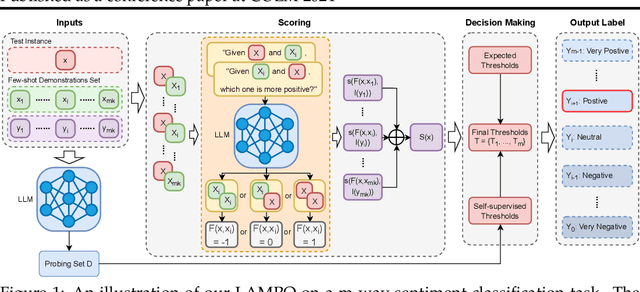
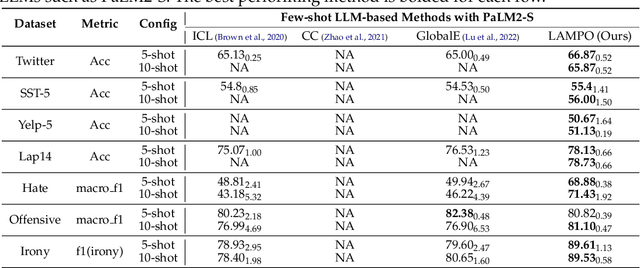
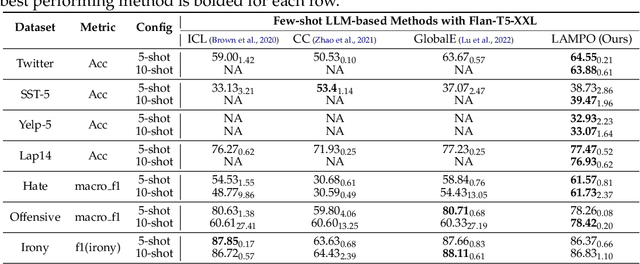
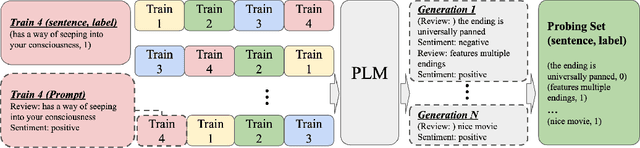
We introduce LAMPO, a novel paradigm that leverages Large Language Models (LLMs) for solving few-shot multi-class ordinal classification tasks. Unlike conventional methods, which concatenate all demonstration examples with the test instance and prompt LLMs to produce the pointwise prediction, our framework uses the LLM as a preference machine that makes a relative comparative decision between the test instance and each demonstration. A self-supervised method is then introduced to aggregate these binary comparisons into the final ordinal decision. LAMPO addresses several limitations inherent in previous methods, including context length constraints, ordering biases, and challenges associated with absolute point-wise estimation. Extensive experiments on seven public datasets demonstrate LAMPO's remarkably competitive performance across a diverse spectrum of applications (e.g., movie review analysis and hate speech detection). Notably, in certain applications, the improvement can be substantial, exceeding 20% in an absolute term. Moreover, we believe LAMPO represents an interesting addition to the non-parametric application layered on top of LLMs, as it supports black-box LLMs without necessitating the outputting of LLM's internal states (e.g., embeddings), as seen in previous approaches.
Principled Architecture-aware Scaling of Hyperparameters
Feb 27, 2024



Training a high-quality deep neural network requires choosing suitable hyperparameters, which is a non-trivial and expensive process. Current works try to automatically optimize or design principles of hyperparameters, such that they can generalize to diverse unseen scenarios. However, most designs or optimization methods are agnostic to the choice of network structures, and thus largely ignore the impact of neural architectures on hyperparameters. In this work, we precisely characterize the dependence of initializations and maximal learning rates on the network architecture, which includes the network depth, width, convolutional kernel size, and connectivity patterns. By pursuing every parameter to be maximally updated with the same mean squared change in pre-activations, we can generalize our initialization and learning rates across MLPs (multi-layer perception) and CNNs (convolutional neural network) with sophisticated graph topologies. We verify our principles with comprehensive experiments. More importantly, our strategy further sheds light on advancing current benchmarks for architecture design. A fair comparison of AutoML algorithms requires accurate network rankings. However, we demonstrate that network rankings can be easily changed by better training networks in benchmarks with our architecture-aware learning rates and initialization.
LiPO: Listwise Preference Optimization through Learning-to-Rank
Feb 02, 2024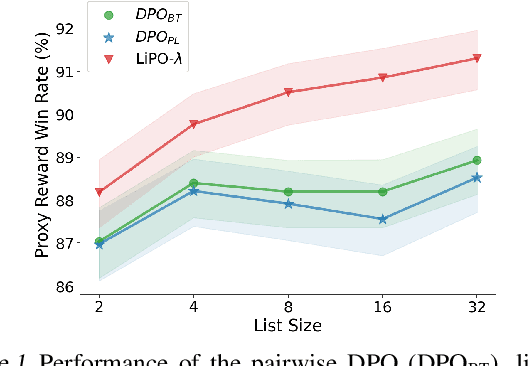



Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a listwise ranking problem and describe the Listwise Preference Optimization (LiPO) framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives, especially pairwise ones. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment withDPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-{\lambda}, which leverages a state-of-the-art listwise ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-{\lambda} can outperform DPO and SLiC by a clear margin on two preference alignment tasks.
Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels
Oct 21, 2023Zero-shot text rankers powered by recent LLMs achieve remarkable ranking performance by simply prompting. Existing prompts for pointwise LLM rankers mostly ask the model to choose from binary relevance labels like "Yes" and "No". However, the lack of intermediate relevance label options may cause the LLM to provide noisy or biased answers for documents that are partially relevant to the query. We propose to incorporate fine-grained relevance labels into the prompt for LLM rankers, enabling them to better differentiate among documents with different levels of relevance to the query and thus derive a more accurate ranking. We study two variants of the prompt template, coupled with different numbers of relevance levels. Our experiments on 8 BEIR data sets show that adding fine-grained relevance labels significantly improves the performance of LLM rankers.
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
Jun 30, 2023



Ranking documents using Large Language Models (LLMs) by directly feeding the query and candidate documents into the prompt is an interesting and practical problem. However, there has been limited success so far, as researchers have found it difficult to outperform fine-tuned baseline rankers on benchmark datasets. We analyze pointwise and listwise ranking prompts used by existing methods and argue that off-the-shelf LLMs do not fully understand these ranking formulations, possibly due to the nature of how LLMs are trained. In this paper, we propose to significantly reduce the burden on LLMs by using a new technique called Pairwise Ranking Prompting (PRP). Our results are the first in the literature to achieve state-of-the-art ranking performance on standard benchmarks using moderate-sized open-sourced LLMs. On TREC-DL2020, PRP based on the Flan-UL2 model with 20B parameters outperforms the previous best approach in the literature, which is based on the blackbox commercial GPT-4 that has 50x (estimated) model size, by over 5% at NDCG@1. On TREC-DL2019, PRP is only inferior to the GPT-4 solution on the NDCG@5 and NDCG@10 metrics, while outperforming other existing solutions, such as InstructGPT which has 175B parameters, by over 10% for nearly all ranking metrics. Furthermore, we propose several variants of PRP to improve efficiency and show that it is possible to achieve competitive results even with linear complexity. We also discuss other benefits of PRP, such as supporting both generation and scoring LLM APIs, as well as being insensitive to input ordering.
Scaling Multimodal Pre-Training via Cross-Modality Gradient Harmonization
Nov 03, 2022



Self-supervised pre-training recently demonstrates success on large-scale multimodal data, and state-of-the-art contrastive learning methods often enforce the feature consistency from cross-modality inputs, such as video/audio or video/text pairs. Despite its convenience to formulate and leverage in practice, such cross-modality alignment (CMA) is only a weak and noisy supervision, since two modalities can be semantically misaligned even they are temporally aligned. For example, even in the commonly adopted instructional videos, a speaker can sometimes refer to something that is not visually present in the current frame; and the semantic misalignment would only be more unpredictable for the raw videos from the internet. We conjecture that might cause conflicts and biases among modalities, and may hence prohibit CMA from scaling up to training with larger and more heterogeneous data. This paper first verifies our conjecture by observing that, even in the latest VATT pre-training using only instructional videos, there exist strong gradient conflicts between different CMA losses within the same video, audio, text triplet, indicating them as the noisy source of supervision. We then propose to harmonize such gradients, via two techniques: (i) cross-modality gradient realignment: modifying different CMA loss gradients for each sample triplet, so that their gradient directions are more aligned; and (ii) gradient-based curriculum learning: leveraging the gradient conflict information on an indicator of sample noisiness, to develop a curriculum learning strategy to prioritize training on less noisy sample triplets. Applying those techniques to pre-training VATT on the HowTo100M dataset, we consistently improve its performance on different downstream tasks. Moreover, we are able to scale VATT pre-training to more complicated non-narrative Youtube8M dataset to further improve the state-of-the-arts.
Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
Apr 27, 2022
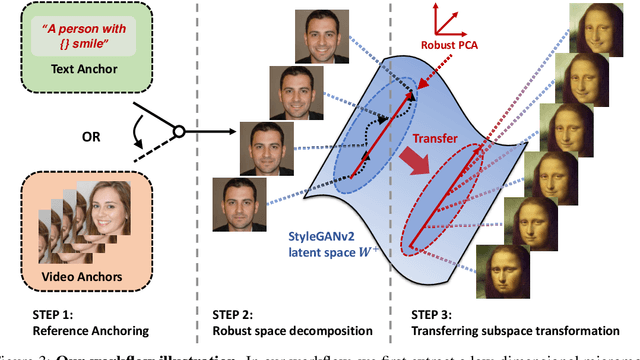


The disentanglement of StyleGAN latent space has paved the way for realistic and controllable image editing, but does StyleGAN know anything about temporal motion, as it was only trained on static images? To study the motion features in the latent space of StyleGAN, in this paper, we hypothesize and demonstrate that a series of meaningful, natural, and versatile small, local movements (referred to as "micromotion", such as expression, head movement, and aging effect) can be represented in low-rank spaces extracted from the latent space of a conventionally pre-trained StyleGAN-v2 model for face generation, with the guidance of proper "anchors" in the form of either short text or video clips. Starting from one target face image, with the editing direction decoded from the low-rank space, its micromotion features can be represented as simple as an affine transformation over its latent feature. Perhaps more surprisingly, such micromotion subspace, even learned from just single target face, can be painlessly transferred to other unseen face images, even those from vastly different domains (such as oil painting, cartoon, and sculpture faces). It demonstrates that the local feature geometry corresponding to one type of micromotion is aligned across different face subjects, and hence that StyleGAN-v2 is indeed "secretly" aware of the subject-disentangled feature variations caused by that micromotion. We present various successful examples of applying our low-dimensional micromotion subspace technique to directly and effortlessly manipulate faces, showing high robustness, low computational overhead, and impressive domain transferability. Our codes are available at https://github.com/wuqiuche/micromotion-StyleGAN.
Auto-X3D: Ultra-Efficient Video Understanding via Finer-Grained Neural Architecture Search
Dec 09, 2021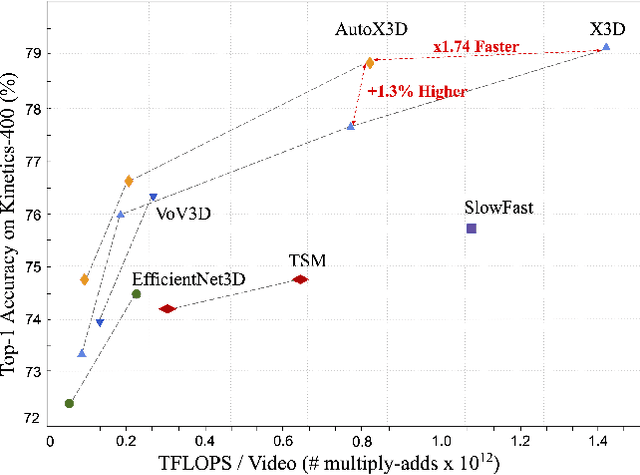

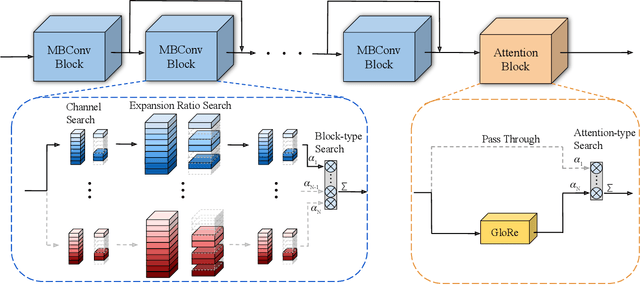
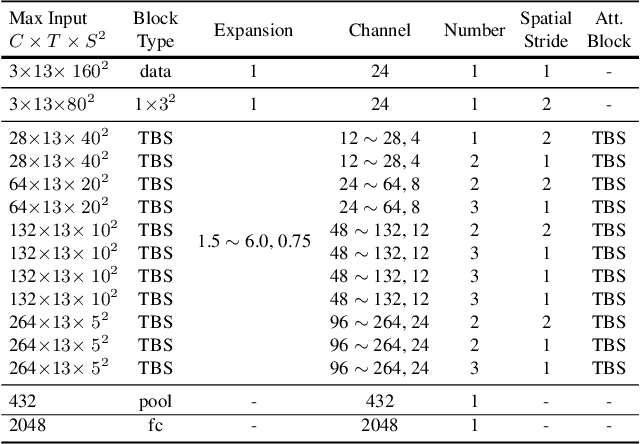
Efficient video architecture is the key to deploying video recognition systems on devices with limited computing resources. Unfortunately, existing video architectures are often computationally intensive and not suitable for such applications. The recent X3D work presents a new family of efficient video models by expanding a hand-crafted image architecture along multiple axes, such as space, time, width, and depth. Although operating in a conceptually large space, X3D searches one axis at a time, and merely explored a small set of 30 architectures in total, which does not sufficiently explore the space. This paper bypasses existing 2D architectures, and directly searched for 3D architectures in a fine-grained space, where block type, filter number, expansion ratio and attention block are jointly searched. A probabilistic neural architecture search method is adopted to efficiently search in such a large space. Evaluations on Kinetics and Something-Something-V2 benchmarks confirm our AutoX3D models outperform existing ones in accuracy up to 1.3% under similar FLOPs, and reduce the computational cost up to x1.74 when reaching similar performance.
Weak NAS Predictors Are All You Need
Feb 21, 2021
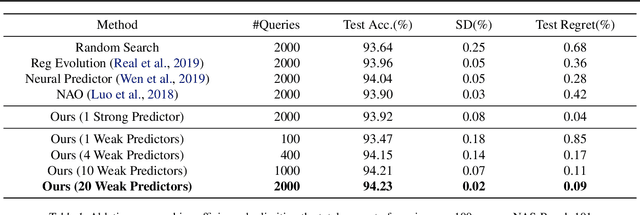
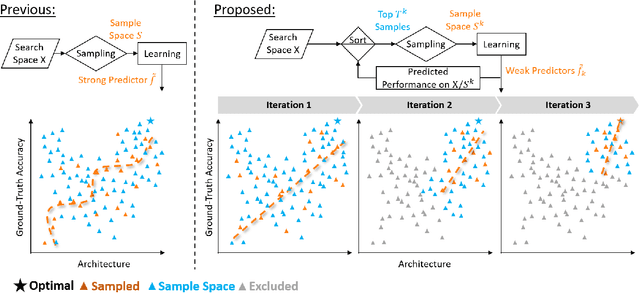

Neural Architecture Search (NAS) finds the best network architecture by exploring the architecture-to-performance manifold. It often trains and evaluates a large number of architectures, causing tremendous computation costs. Recent predictor-based NAS approaches attempt to solve this problem with two key steps: sampling some architecture-performance pairs and fitting a proxy accuracy predictor. Given limited samples, these predictors, however, are far from accurate to locate top architectures. In this paper, we shift the paradigm from finding a complicated predictor that covers the whole architecture space to a set of weaker predictors that progressively move towards the high-performance sub-space. It is based on the key property of the proposed weak predictors that their probabilities of sampling better architectures keep increasing. We thus only sample a few well-performed architectures guided by the previously learned predictor and estimate a new better weak predictor. By this coarse-to-fine iteration, the ranking of sampling space is refined gradually, which helps find the optimal architectures eventually. Experiments demonstrate that our method costs fewer samples to find the top-performance architectures on NAS-Bench-101 and NAS-Bench-201, and it achieves the state-of-the-art ImageNet performance on the NASNet search space. The code is available at https://github.com/VITA-Group/WeakNAS