 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-X3D: Ultra-Efficient Video Understanding via Finer-Grained Neural Architecture Search
Paper and Code
Dec 09, 2021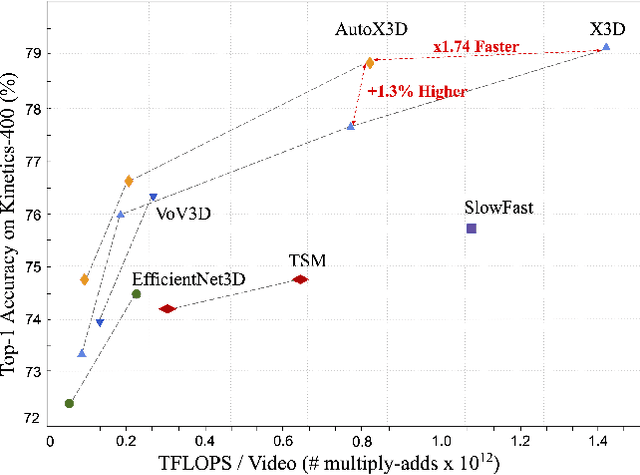

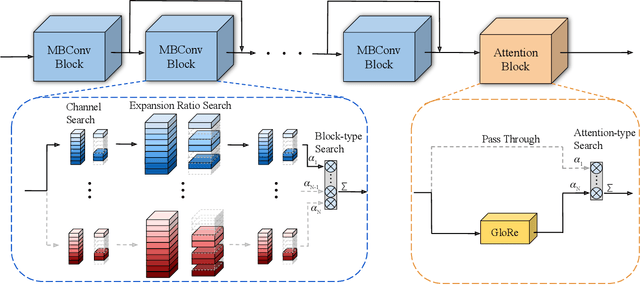
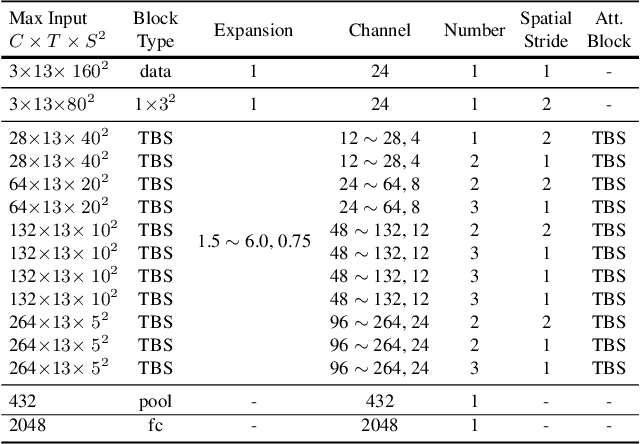
Efficient video architecture is the key to deploying video recognition systems on devices with limited computing resources. Unfortunately, existing video architectures are often computationally intensive and not suitable for such applications. The recent X3D work presents a new family of efficient video models by expanding a hand-crafted image architecture along multiple axes, such as space, time, width, and depth. Although operating in a conceptually large space, X3D searches one axis at a time, and merely explored a small set of 30 architectures in total, which does not sufficiently explore the space. This paper bypasses existing 2D architectures, and directly searched for 3D architectures in a fine-grained space, where block type, filter number, expansion ratio and attention block are jointly searched. A probabilistic neural architecture search method is adopted to efficiently search in such a large space. Evaluations on Kinetics and Something-Something-V2 benchmarks confirm our AutoX3D models outperform existing ones in accuracy up to 1.3% under similar FLOPs, and reduce the computational cost up to x1.74 when reaching similar performance.