 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-S2V: Multi-View Subject-Consistent Video Generation
Jan 27, 2026Existing Subject-to-Video Generation (S2V) methods have achieved high-fidelity and subject-consistent video generation, yet remain constrained to single-view subject references. This limitation renders the S2V task reducible to an S2I + I2V pipeline, failing to exploit the full potential of video subject control. In this work, we propose and address the challenging Multi-View S2V (MV-S2V) task, which synthesizes videos from multiple reference views to enforce 3D-level subject consistency. Regarding the scarcity of training data, we first develop a synthetic data curation pipeline to generate highly customized synthetic data, complemented by a small-scale real-world captured dataset to boost the training of MV-S2V. Another key issue lies in the potential confusion between cross-subject and cross-view references in conditional generation. To overcome this, we further introduce Temporally Shifted RoPE (TS-RoPE) to distinguish between different subjects and distinct views of the same subject in reference conditioning. Our framework achieves superior 3D subject consistency w.r.t. multi-view reference images and high-quality visual outputs, establishing a new meaningful direction for subject-driven video generation. Our project page is available at: https://szy-young.github.io/mv-s2v
ByteLoom: Weaving Geometry-Consistent Human-Object Interactions through Progressive Curriculum Learning
Dec 28, 2025Human-object interaction (HOI) video generation has garnered increasing attention due to its promising applications in digital humans, e-commerce, advertising, and robotics imitation learning. However, existing methods face two critical limitations: (1) a lack of effective mechanisms to inject multi-view information of the object into the model, leading to poor cross-view consistency, and (2) heavy reliance on fine-grained hand mesh annotations for modeling interaction occlusions. To address these challenges, we introduce ByteLoom, a Diffusion Transformer (DiT)-based framework that generates realistic HOI videos with geometrically consistent object illustration, using simplified human conditioning and 3D object inputs. We first propose an RCM-cache mechanism that leverages Relative Coordinate Maps (RCM) as a universal representation to maintain object's geometry consistency and precisely control 6-DoF object transformations in the meantime. To compensate HOI dataset scarcity and leverage existing datasets, we further design a training curriculum that enhances model capabilities in a progressive style and relaxes the demand of hand mesh. Extensive experiments demonstrate that our method faithfully preserves human identity and the object's multi-view geometry, while maintaining smooth motion and object manipulation.
CETCAM: Camera-Controllable Video Generation via Consistent and Extensible Tokenization
Dec 22, 2025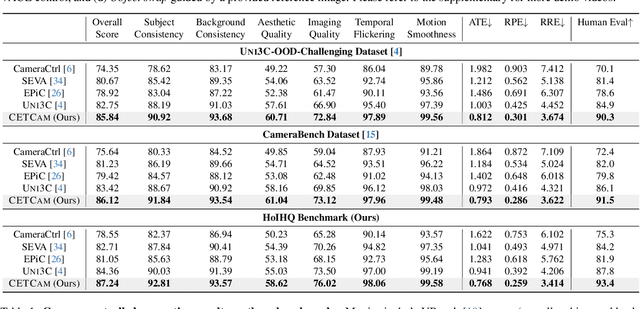
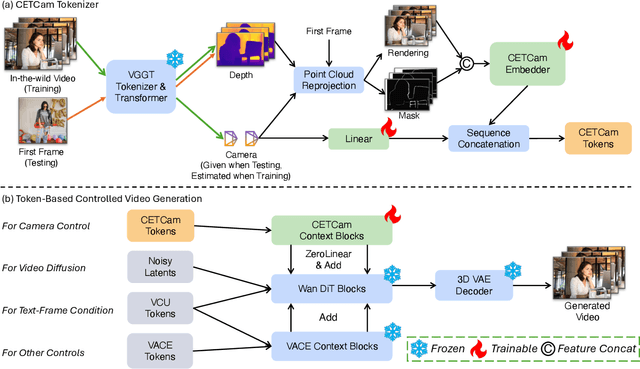
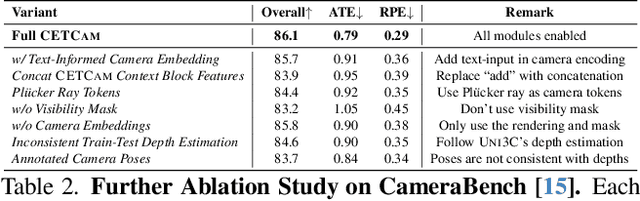

Achieving precise camera control in video generation remains challenging, as existing methods often rely on camera pose annotations that are difficult to scale to large and dynamic datasets and are frequently inconsistent with depth estimation, leading to train-test discrepancies. We introduce CETCAM, a camera-controllable video generation framework that eliminates the need for camera annotations through a consistent and extensible tokenization scheme. CETCAM leverages recent advances in geometry foundation models, such as VGGT, to estimate depth and camera parameters and converts them into unified, geometry-aware tokens. These tokens are seamlessly integrated into a pretrained video diffusion backbone via lightweight context blocks. Trained in two progressive stages, CETCAM first learns robust camera controllability from diverse raw video data and then refines fine-grained visual quality using curated high-fidelity datasets. Extensive experiments across multiple benchmarks demonstrate state-of-the-art geometric consistency, temporal stability, and visual realism. Moreover, CETCAM exhibits strong adaptability to additional control modalities, including inpainting and layout control, highlighting its flexibility beyond camera control. The project page is available at https://sjtuytc.github.io/CETCam_project_page.github.io/.
Large Language Models for Bioinformatics
Jan 10, 2025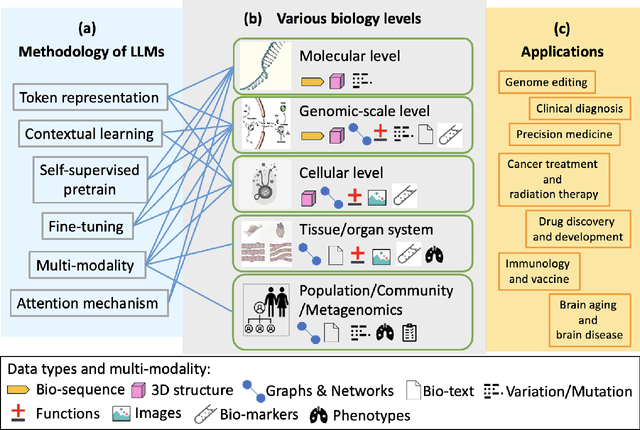
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
Evaluating the Potential of Leading Large Language Models in Reasoning Biology Questions
Nov 05, 2023Recent advances in Large Language Models (LLMs) have presented new opportunities for integrating Artificial General Intelligence (AGI) into biological research and education. This study evaluated the capabilities of leading LLMs, including GPT-4, GPT-3.5, PaLM2, Claude2, and SenseNova, in answering conceptual biology questions. The models were tested on a 108-question multiple-choice exam covering biology topics in molecular biology, biological techniques, metabolic engineering, and synthetic biology. Among the models, GPT-4 achieved the highest average score of 90 and demonstrated the greatest consistency across trials with different prompts. The results indicated GPT-4's proficiency in logical reasoning and its potential to aid biology research through capabilities like data analysis, hypothesis generation, and knowledge integration. However, further development and validation are still required before the promise of LLMs in accelerating biological discovery can be realized.
MMG-Ego4D: Multi-Modal Generalization in Egocentric Action Recognition
May 12, 2023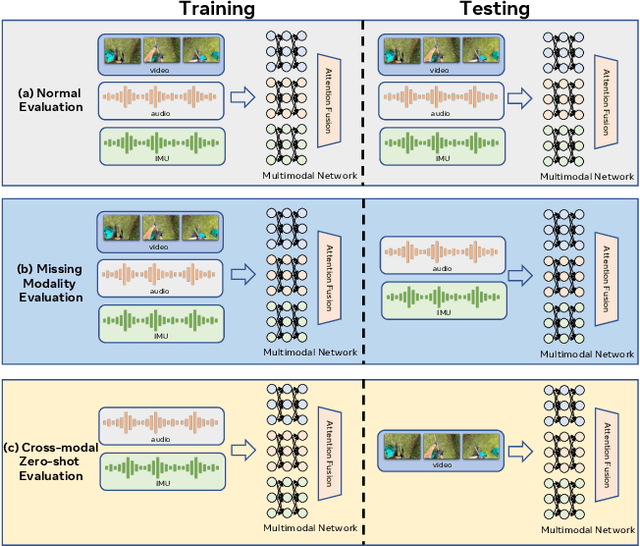

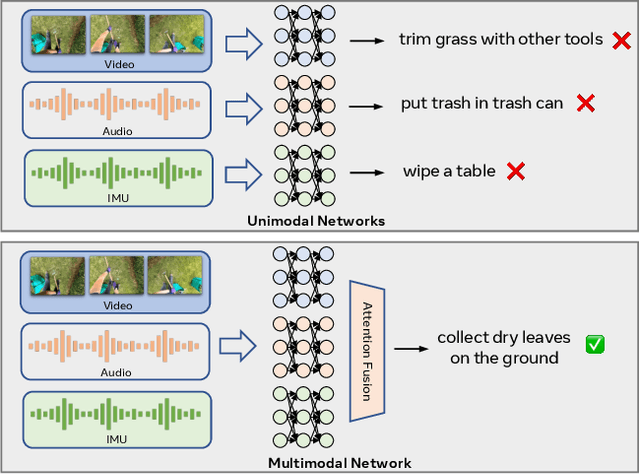
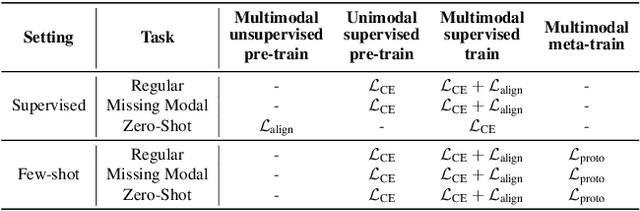
In this paper, we study a novel problem in egocentric action recognition, which we term as "Multimodal Generalization" (MMG). MMG aims to study how systems can generalize when data from certain modalities is limited or even completely missing. We thoroughly investigate MMG in the context of standard supervised action recognition and the more challenging few-shot setting for learning new action categories. MMG consists of two novel scenarios, designed to support security, and efficiency considerations in real-world applications: (1) missing modality generalization where some modalities that were present during the train time are missing during the inference time, and (2) cross-modal zero-shot generalization, where the modalities present during the inference time and the training time are disjoint. To enable this investigation, we construct a new dataset MMG-Ego4D containing data points with video, audio, and inertial motion sensor (IMU) modalities. Our dataset is derived from Ego4D dataset, but processed and thoroughly re-annotated by human experts to facilitate research in the MMG problem. We evaluate a diverse array of models on MMG-Ego4D and propose new methods with improved generalization ability. In particular, we introduce a new fusion module with modality dropout training, contrastive-based alignment training, and a novel cross-modal prototypical loss for better few-shot performance. We hope this study will serve as a benchmark and guide future research in multimodal generalization problems. The benchmark and code will be available at https://github.com/facebookresearch/MMG_Ego4D.
NeRF-SOS: Any-View Self-supervised Object Segmentation on Complex Scenes
Oct 12, 2022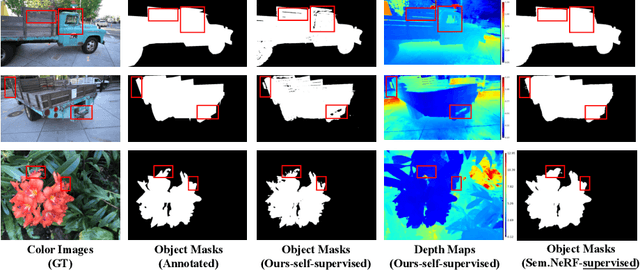
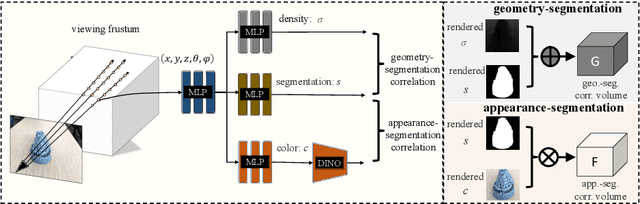
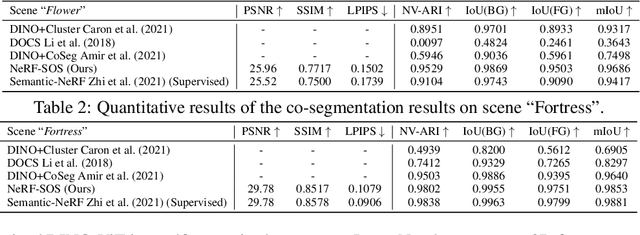

Neural volumetric representations have shown the potential that Multi-layer Perceptrons (MLPs) can be optimized with multi-view calibrated images to represent scene geometry and appearance, without explicit 3D supervision. Object segmentation can enrich many downstream applications based on the learned radiance field. However, introducing hand-crafted segmentation to define regions of interest in a complex real-world scene is non-trivial and expensive as it acquires per view annotation. This paper carries out the exploration of self-supervised learning for object segmentation using NeRF for complex real-world scenes. Our framework, called NeRF with Self-supervised Object Segmentation NeRF-SOS, couples object segmentation and neural radiance field to segment objects in any view within a scene. By proposing a novel collaborative contrastive loss in both appearance and geometry levels, NeRF-SOS encourages NeRF models to distill compact geometry-aware segmentation clusters from their density fields and the self-supervised pre-trained 2D visual features. The self-supervised object segmentation framework can be applied to various NeRF models that both lead to photo-realistic rendering results and convincing segmentation maps for both indoor and outdoor scenarios. Extensive results on the LLFF, Tank & Temple, and BlendedMVS datasets validate the effectiveness of NeRF-SOS. It consistently surpasses other 2D-based self-supervised baselines and predicts finer semantics masks than existing supervised counterparts. Please refer to the video on our project page for more details:https://zhiwenfan.github.io/NeRF-SOS.
Deep Architecture Connectivity Matters for Its Convergence: A Fine-Grained Analysis
May 11, 2022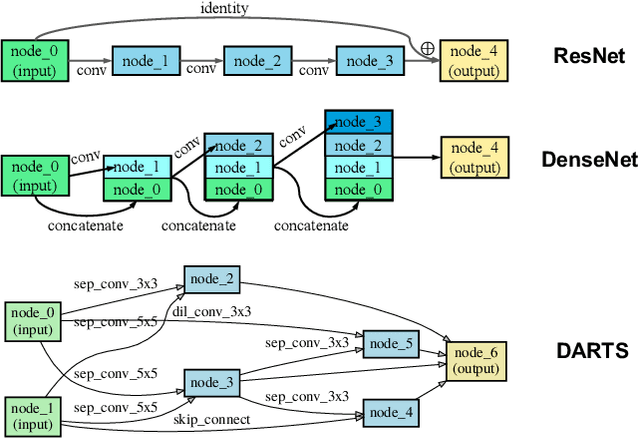
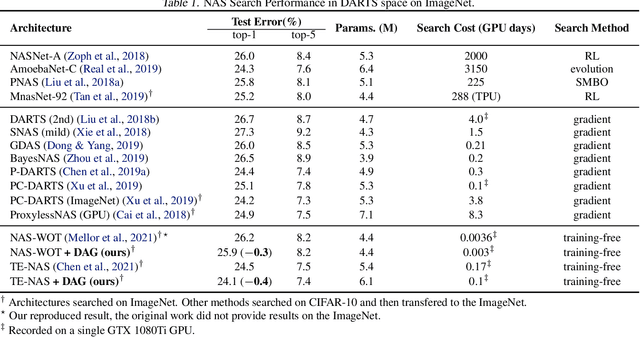
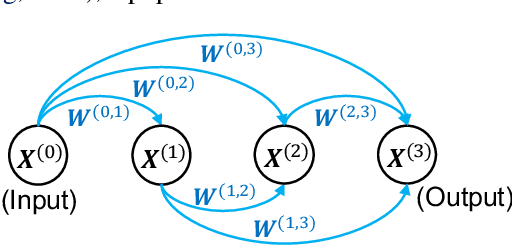

Advanced deep neural networks (DNNs), designed by either human or AutoML algorithms, are growing increasingly complex. Diverse operations are connected by complicated connectivity patterns, e.g., various types of skip connections. Those topological compositions are empirically effective and observed to smooth the loss landscape and facilitate the gradient flow in general. However, it remains elusive to derive any principled understanding of their effects on the DNN capacity or trainability, and to understand why or in which aspect one specific connectivity pattern is better than another. In this work, we theoretically characterize the impact of connectivity patterns on the convergence of DNNs under gradient descent training in fine granularity. By analyzing a wide network's Neural Network Gaussian Process (NNGP), we are able to depict how the spectrum of an NNGP kernel propagates through a particular connectivity pattern, and how that affects the bound of convergence rates. As one practical implication of our results, we show that by a simple filtration on "unpromising" connectivity patterns, we can trim down the number of models to evaluate, and significantly accelerate the large-scale neural architecture search without any overhead. Codes will be released at https://github.com/chenwydj/architecture_convergence.
Unified Implicit Neural Stylization
Apr 06, 2022

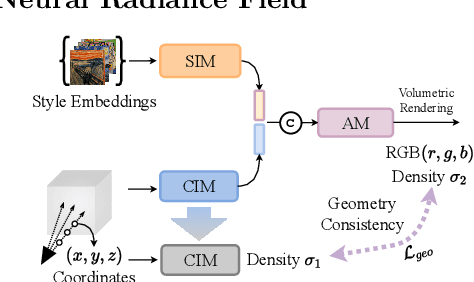

Representing visual signals by implicit representation (e.g., a coordinate based deep network) has prevailed among many vision tasks. This work explores a new intriguing direction: training a stylized implicit representation, using a generalized approach that can apply to various 2D and 3D scenarios. We conduct a pilot study on a variety of implicit functions, including 2D coordinate-based representation, neural radiance field, and signed distance function. Our solution is a Unified Implicit Neural Stylization framework, dubbed INS. In contrary to vanilla implicit representation, INS decouples the ordinary implicit function into a style implicit module and a content implicit module, in order to separately encode the representations from the style image and input scenes. An amalgamation module is then applied to aggregate these information and synthesize the stylized output. To regularize the geometry in 3D scenes, we propose a novel self-distillation geometry consistency loss which preserves the geometry fidelity of the stylized scenes. Comprehensive experiments are conducted on multiple task settings, including novel view synthesis of complex scenes, stylization for implicit surfaces, and fitting images using MLPs. We further demonstrate that the learned representation is continuous not only spatially but also style-wise, leading to effortlessly interpolating between different styles and generating images with new mixed styles. Please refer to the video on our project page for more view synthesis results: https://zhiwenfan.github.io/INS.
Auto-X3D: Ultra-Efficient Video Understanding via Finer-Grained Neural Architecture Search
Dec 09, 2021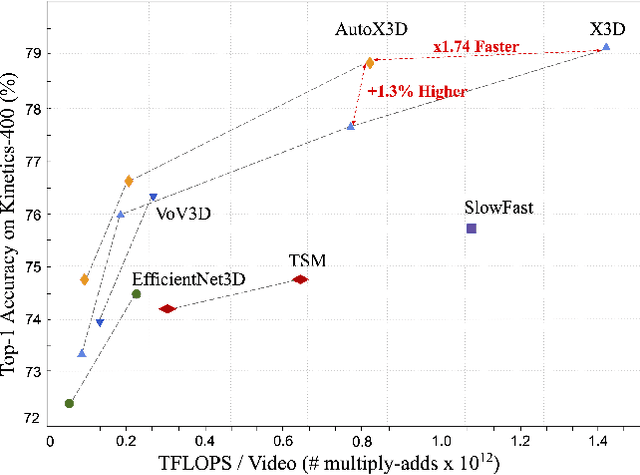

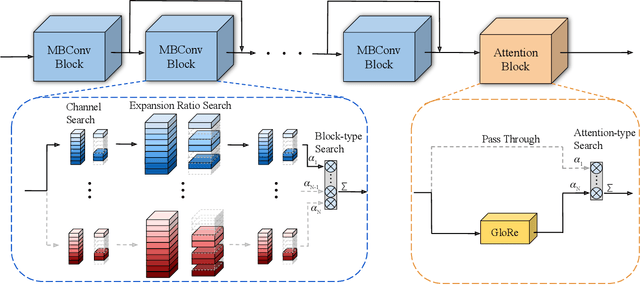
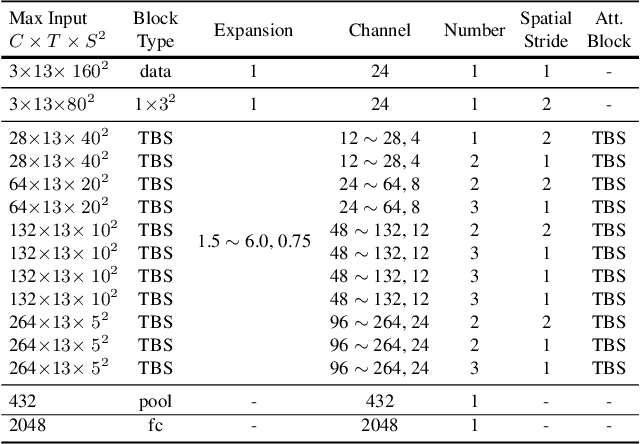
Efficient video architecture is the key to deploying video recognition systems on devices with limited computing resources. Unfortunately, existing video architectures are often computationally intensive and not suitable for such applications. The recent X3D work presents a new family of efficient video models by expanding a hand-crafted image architecture along multiple axes, such as space, time, width, and depth. Although operating in a conceptually large space, X3D searches one axis at a time, and merely explored a small set of 30 architectures in total, which does not sufficiently explore the space. This paper bypasses existing 2D architectures, and directly searched for 3D architectures in a fine-grained space, where block type, filter number, expansion ratio and attention block are jointly searched. A probabilistic neural architecture search method is adopted to efficiently search in such a large space. Evaluations on Kinetics and Something-Something-V2 benchmarks confirm our AutoX3D models outperform existing ones in accuracy up to 1.3% under similar FLOPs, and reduce the computational cost up to x1.74 when reaching similar performance.