 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe Medicine: Redefining Biomedical Research Through Human-AI Co-Work
Apr 26, 2026With the emergence of large language models (LLMs) and AI agent frameworks, the human-AI co-work paradigm known as Vibe Coding is changing how people code, making it more accessible and productive. In scientific research, where workflows are more complex and the burden of specialized labor limits independent researchers and those in low-resource areas, the potential impact is even greater, particularly in biomedicine, which involves heterogeneous data modalities and multi-step analytical pipelines. In this paper, we introduce Vibe Medicine, a co-work paradigm in which clinicians and researchers direct skill-augmented AI agents through natural language to execute complex, multi-step biomedical workflows, while retaining the role of research director who specifies objectives, reviews intermediate results, and makes domain-informed decisions. The enabling infrastructure consists of three layers: capable LLMs, agent frameworks such as OpenClaw and Hermes Agent, and the OpenClaw medical skills collection, which includes more than 1,000 curated skills from multiple open-source repositories. We analyze the architecture and skill categories of this collection across ten biomedical domains, and present case studies covering rare disease diagnosis, drug repurposing, and clinical trial design that demonstrate end-to-end workflows in practice. We also identify the principal risks, such as hallucination, data privacy, and over-reliance, and outline directions toward more reliable, trustworthy, and clinically integrated agent-assisted research that advances research and technological equity and reduces health care resource disparities.
AD-GPT: Large Language Models in Alzheimer's Disease
Apr 03, 2025Large language models (LLMs) have emerged as powerful tools for medical information retrieval, yet their accuracy and depth remain limited in specialized domains such as Alzheimer's disease (AD), a growing global health challenge. To address this gap, we introduce AD-GPT, a domain-specific generative pre-trained transformer designed to enhance the retrieval and analysis of AD-related genetic and neurobiological information. AD-GPT integrates diverse biomedical data sources, including potential AD-associated genes, molecular genetic information, and key gene variants linked to brain regions. We develop a stacked LLM architecture combining Llama3 and BERT, optimized for four critical tasks in AD research: (1) genetic information retrieval, (2) gene-brain region relationship assessment, (3) gene-AD relationship analysis, and (4) brain region-AD relationship mapping. Comparative evaluations against state-of-the-art LLMs demonstrate AD-GPT's superior precision and reliability across these tasks, underscoring its potential as a robust and specialized AI tool for advancing AD research and biomarker discovery.
GyralNet Subnetwork Partitioning via Differentiable Spectral Modularity Optimization
Mar 25, 2025



Understanding the structural and functional organization of the human brain requires a detailed examination of cortical folding patterns, among which the three-hinge gyrus (3HG) has been identified as a key structural landmark. GyralNet, a network representation of cortical folding, models 3HGs as nodes and gyral crests as edges, highlighting their role as critical hubs in cortico-cortical connectivity. However, existing methods for analyzing 3HGs face significant challenges, including the sub-voxel scale of 3HGs at typical neuroimaging resolutions, the computational complexity of establishing cross-subject correspondences, and the oversimplification of treating 3HGs as independent nodes without considering their community-level relationships. To address these limitations, we propose a fully differentiable subnetwork partitioning framework that employs a spectral modularity maximization optimization strategy to modularize the organization of 3HGs within GyralNet. By incorporating topological structural similarity and DTI-derived connectivity patterns as attribute features, our approach provides a biologically meaningful representation of cortical organization. Extensive experiments on the Human Connectome Project (HCP) dataset demonstrate that our method effectively partitions GyralNet at the individual level while preserving the community-level consistency of 3HGs across subjects, offering a robust foundation for understanding brain connectivity.
Core-Periphery Principle Guided State Space Model for Functional Connectome Classification
Mar 18, 2025Understanding the organization of human brain networks has become a central focus in neuroscience, particularly in the study of functional connectivity, which plays a crucial role in diagnosing neurological disorders. Advances in functional magnetic resonance imaging and machine learning techniques have significantly improved brain network analysis. However, traditional machine learning approaches struggle to capture the complex relationships between brain regions, while deep learning methods, particularly Transformer-based models, face computational challenges due to their quadratic complexity in long-sequence modeling. To address these limitations, we propose a Core-Periphery State-Space Model (CP-SSM), an innovative framework for functional connectome classification. Specifically, we introduce Mamba, a selective state-space model with linear complexity, to effectively capture long-range dependencies in functional brain networks. Furthermore, inspired by the core-periphery (CP) organization, a fundamental characteristic of brain networks that enhances efficient information transmission, we design CP-MoE, a CP-guided Mixture-of-Experts that improves the representation learning of brain connectivity patterns. We evaluate CP-SSM on two benchmark fMRI datasets: ABIDE and ADNI. Experimental results demonstrate that CP-SSM surpasses Transformer-based models in classification performance while significantly reducing computational complexity. These findings highlight the effectiveness and efficiency of CP-SSM in modeling brain functional connectivity, offering a promising direction for neuroimaging-based neurological disease diagnosis.
Brain-Adapter: Enhancing Neurological Disorder Analysis with Adapter-Tuning Multimodal Large Language Models
Jan 27, 2025


Understanding brain disorders is crucial for accurate clinical diagnosis and treatment. Recent advances in Multimodal Large Language Models (MLLMs) offer a promising approach to interpreting medical images with the support of text descriptions. However, previous research has primarily focused on 2D medical images, leaving richer spatial information of 3D images under-explored, and single-modality-based methods are limited by overlooking the critical clinical information contained in other modalities. To address this issue, this paper proposes Brain-Adapter, a novel approach that incorporates an extra bottleneck layer to learn new knowledge and instill it into the original pre-trained knowledge. The major idea is to incorporate a lightweight bottleneck layer to train fewer parameters while capturing essential information and utilize a Contrastive Language-Image Pre-training (CLIP) strategy to align multimodal data within a unified representation space. Extensive experiments demonstrated the effectiveness of our approach in integrating multimodal data to significantly improve the diagnosis accuracy without high computational costs, highlighting the potential to enhance real-world diagnostic workflows.
Classification of Mild Cognitive Impairment Based on Dynamic Functional Connectivity Using Spatio-Temporal Transformer
Jan 27, 2025Dynamic functional connectivity (dFC) using resting-state functional magnetic resonance imaging (rs-fMRI) is an advanced technique for capturing the dynamic changes of neural activities, and can be very useful in the studies of brain diseases such as Alzheimer's disease (AD). Yet, existing studies have not fully leveraged the sequential information embedded within dFC that can potentially provide valuable information when identifying brain conditions. In this paper, we propose a novel framework that jointly learns the embedding of both spatial and temporal information within dFC based on the transformer architecture. Specifically, we first construct dFC networks from rs-fMRI data through a sliding window strategy. Then, we simultaneously employ a temporal block and a spatial block to capture higher-order representations of dynamic spatio-temporal dependencies, via mapping them into an efficient fused feature representation. To further enhance the robustness of these feature representations by reducing the dependency on labeled data, we also introduce a contrastive learning strategy to manipulate different brain states. Experimental results on 345 subjects with 570 scans from the Alzheimer's Disease Neuroimaging Initiative (ADNI) demonstrate the superiority of our proposed method for MCI (Mild Cognitive Impairment, the prodromal stage of AD) prediction, highlighting its potential for early identification of AD.
Large Language Models for Bioinformatics
Jan 10, 2025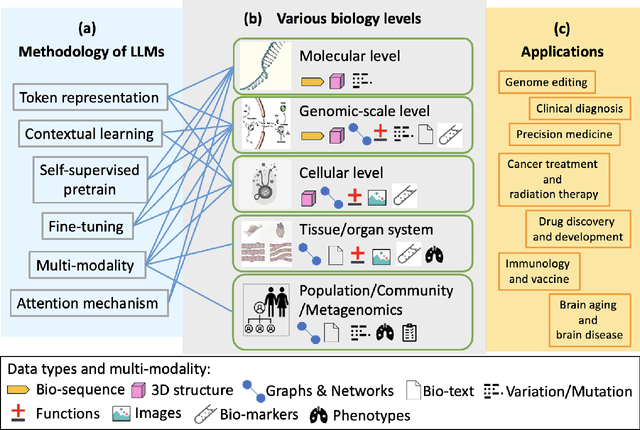
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
Using Structural Similarity and Kolmogorov-Arnold Networks for Anatomical Embedding of 3-hinge Gyrus
Oct 31, 2024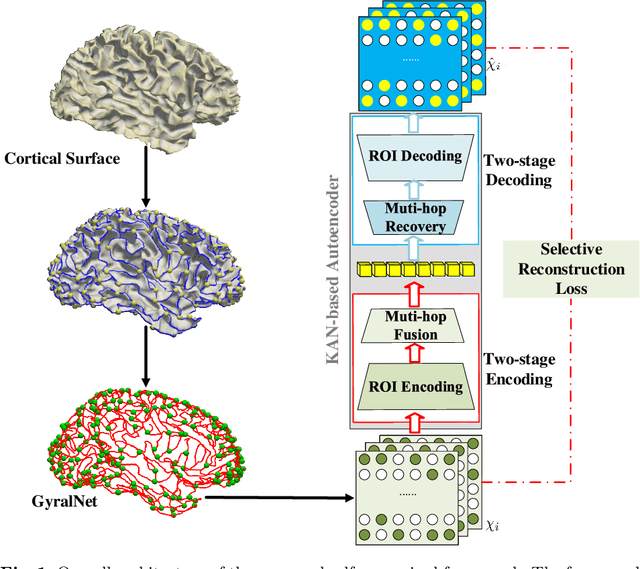
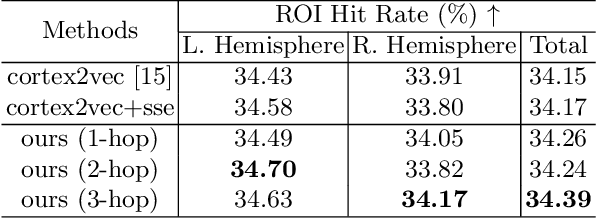
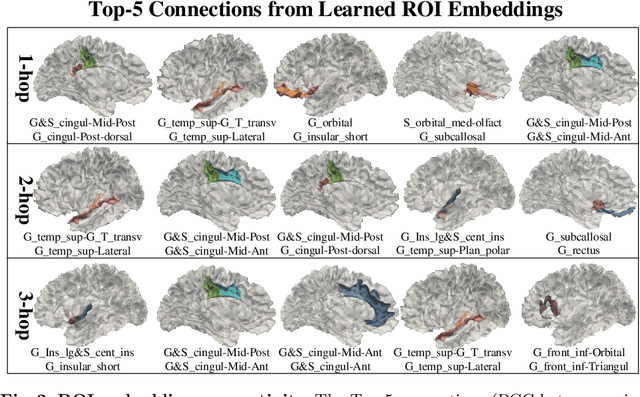

The 3-hinge gyrus (3HG) is a newly defined folding pattern, which is the conjunction of gyri coming from three directions in cortical folding. Many studies demonstrated that 3HGs can be reliable nodes when constructing brain networks or connectome since they simultaneously possess commonality and individuality across different individual brains and populations. However, 3HGs are identified and validated within individual spaces, making it difficult to directly serve as the brain network nodes due to the absence of cross-subject correspondence. The 3HG correspondences represent the intrinsic regulation of brain organizational architecture, traditional image-based registration methods tend to fail because individual anatomical properties need to be fully respected. To address this challenge, we propose a novel self-supervised framework for anatomical feature embedding of the 3HGs to build the correspondences among different brains. The core component of this framework is to construct a structural similarity-enhanced multi-hop feature encoding strategy based on the recently developed Kolmogorov-Arnold network (KAN) for anatomical feature embedding. Extensive experiments suggest that our approach can effectively establish robust cross-subject correspondences when no one-to-one mapping exists.
Large Language Models for Manufacturing
Oct 28, 2024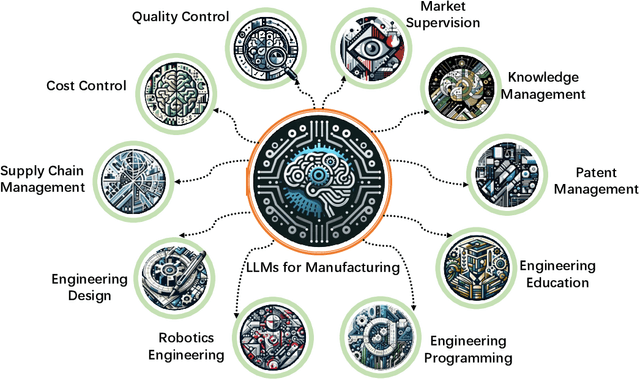


The rapid advances in Large Language Models (LLMs) have the potential to transform manufacturing industry, offering new opportunities to optimize processes, improve efficiency, and drive innovation. This paper provides a comprehensive exploration of the integration of LLMs into the manufacturing domain, focusing on their potential to automate and enhance various aspects of manufacturing, from product design and development to quality control, supply chain optimization, and talent management. Through extensive evaluations across multiple manufacturing tasks, we demonstrate the remarkable capabilities of state-of-the-art LLMs, such as GPT-4V, in understanding and executing complex instructions, extracting valuable insights from vast amounts of data, and facilitating knowledge sharing. We also delve into the transformative potential of LLMs in reshaping manufacturing education, automating coding processes, enhancing robot control systems, and enabling the creation of immersive, data-rich virtual environments through the industrial metaverse. By highlighting the practical applications and emerging use cases of LLMs in manufacturing, this paper aims to provide a valuable resource for professionals, researchers, and decision-makers seeking to harness the power of these technologies to address real-world challenges, drive operational excellence, and unlock sustainable growth in an increasingly competitive landscape.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024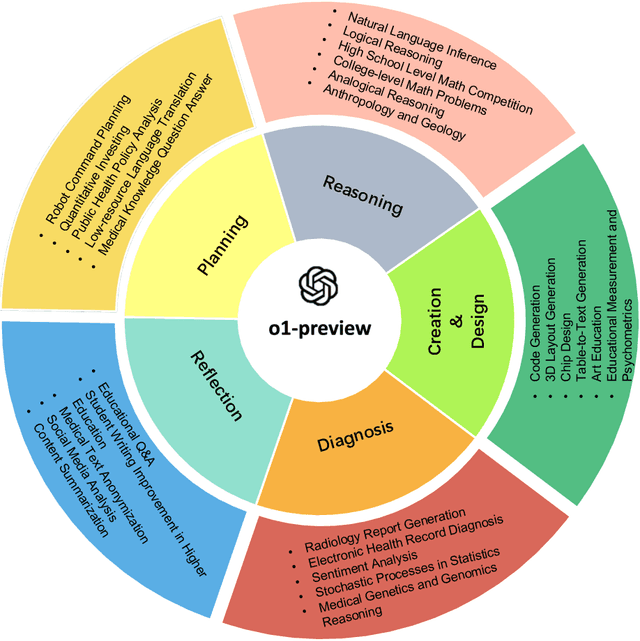


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.