 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViThinker: Active Vision-Language Reasoning via Dynamic Perceptual Querying
Feb 02, 2026Chain-of-Thought (CoT) reasoning excels in language models but struggles in vision-language models due to premature visual-to-text conversion that discards continuous information such as geometry and spatial layout. While recent methods enhance CoT through static enumeration or attention-based selection, they remain passive, i.e., processing pre-computed inputs rather than actively seeking task-relevant details. Inspired by human active perception, we introduce ViThinker, a framework that enables vision-language models to autonomously generate decision (query) tokens triggering the synthesis of expert-aligned visual features on demand. ViThinker internalizes vision-expert capabilities during training, performing generative mental simulation during inference without external tool calls. Through a two-stage curriculum: first distilling frozen experts into model parameters, then learning task-driven querying via sparsity penalties, i.e., ViThinker discovers minimal sufficient perception for each reasoning step. Evaluations across vision-centric benchmarks demonstrate consistent improvements, validating that active query generation outperforms passive approaches in both perceptual grounding and reasoning accuracy.
SYNAPSE: Empowering LLM Agents with Episodic-Semantic Memory via Spreading Activation
Jan 06, 2026While Large Language Models (LLMs) excel at generalized reasoning, standard retrieval-augmented approaches fail to address the disconnected nature of long-term agentic memory. To bridge this gap, we introduce Synapse (Synergistic Associative Processing Semantic Encoding), a unified memory architecture that transcends static vector similarity. Drawing from cognitive science, Synapse models memory as a dynamic graph where relevance emerges from spreading activation rather than pre-computed links. By integrating lateral inhibition and temporal decay, the system dynamically highlights relevant sub-graphs while filtering interference. We implement a Triple Hybrid Retrieval strategy that fuses geometric embeddings with activation-based graph traversal. Comprehensive evaluations on the LoCoMo benchmark show that Synapse significantly outperforms state-of-the-art methods in complex temporal and multi-hop reasoning tasks, offering a robust solution to the "Contextual Tunneling" problem. Our code and data will be made publicly available upon acceptance.
Achieving Fine-grained Cross-modal Understanding through Brain-inspired Hierarchical Representation Learning
Jan 04, 2026Understanding neural responses to visual stimuli remains challenging due to the inherent complexity of brain representations and the modality gap between neural data and visual inputs. Existing methods, mainly based on reducing neural decoding to generation tasks or simple correlations, fail to reflect the hierarchical and temporal processes of visual processing in the brain. To address these limitations, we present NeuroAlign, a novel framework for fine-grained fMRI-video alignment inspired by the hierarchical organization of the human visual system. Our framework implements a two-stage mechanism that mirrors biological visual pathways: global semantic understanding through Neural-Temporal Contrastive Learning (NTCL) and fine-grained pattern matching through enhanced vector quantization. NTCL explicitly models temporal dynamics through bidirectional prediction between modalities, while our DynaSyncMM-EMA approach enables dynamic multi-modal fusion with adaptive weighting. Experiments demonstrate that NeuroAlign significantly outperforms existing methods in cross-modal retrieval tasks, establishing a new paradigm for understanding visual cognitive mechanisms.
ADLGen: Synthesizing Symbolic, Event-Triggered Sensor Sequences for Human Activity Modeling
May 23, 2025Real world collection of Activities of Daily Living data is challenging due to privacy concerns, costly deployment and labeling, and the inherent sparsity and imbalance of human behavior. We present ADLGen, a generative framework specifically designed to synthesize realistic, event triggered, and symbolic sensor sequences for ambient assistive environments. ADLGen integrates a decoder only Transformer with sign based symbolic temporal encoding, and a context and layout aware sampling mechanism to guide generation toward semantically rich and physically plausible sensor event sequences. To enhance semantic fidelity and correct structural inconsistencies, we further incorporate a large language model into an automatic generate evaluate refine loop, which verifies logical, behavioral, and temporal coherence and generates correction rules without manual intervention or environment specific tuning. Through comprehensive experiments with novel evaluation metrics, ADLGen is shown to outperform baseline generators in statistical fidelity, semantic richness, and downstream activity recognition, offering a scalable and privacy-preserving solution for ADL data synthesis.
AdCare-VLM: Leveraging Large Vision Language Model (LVLM) to Monitor Long-Term Medication Adherence and Care
May 01, 2025Chronic diseases, including diabetes, hypertension, asthma, HIV-AIDS, epilepsy, and tuberculosis, necessitate rigorous adherence to medication to avert disease progression, manage symptoms, and decrease mortality rates. Adherence is frequently undermined by factors including patient behavior, caregiver support, elevated medical costs, and insufficient healthcare infrastructure. We propose AdCare-VLM, a specialized Video-LLaVA-based multimodal large vision language model (LVLM) aimed at visual question answering (VQA) concerning medication adherence through patient videos. We employ a private dataset comprising 806 custom-annotated tuberculosis (TB) medication monitoring videos, which have been labeled by clinical experts, to fine-tune the model for adherence pattern detection. We present LLM-TB-VQA, a detailed medical adherence VQA dataset that encompasses positive, negative, and ambiguous adherence cases. Our method identifies correlations between visual features, such as the clear visibility of the patient's face, medication, water intake, and the act of ingestion, and their associated medical concepts in captions. This facilitates the integration of aligned visual-linguistic representations and improves multimodal interactions. Experimental results indicate that our method surpasses parameter-efficient fine-tuning (PEFT) enabled VLM models, such as LLaVA-V1.5 and Chat-UniVi, with absolute improvements ranging from 3.1% to 3.54% across pre-trained, regular, and low-rank adaptation (LoRA) configurations. Comprehensive ablation studies and attention map visualizations substantiate our approach, enhancing interpretability.
MMGDreamer: Mixed-Modality Graph for Geometry-Controllable 3D Indoor Scene Generation
Feb 09, 2025Controllable 3D scene generation has extensive applications in virtual reality and interior design, where the generated scenes should exhibit high levels of realism and controllability in terms of geometry. Scene graphs provide a suitable data representation that facilitates these applications. However, current graph-based methods for scene generation are constrained to text-based inputs and exhibit insufficient adaptability to flexible user inputs, hindering the ability to precisely control object geometry. To address this issue, we propose MMGDreamer, a dual-branch diffusion model for scene generation that incorporates a novel Mixed-Modality Graph, visual enhancement module, and relation predictor. The mixed-modality graph allows object nodes to integrate textual and visual modalities, with optional relationships between nodes. It enhances adaptability to flexible user inputs and enables meticulous control over the geometry of objects in the generated scenes. The visual enhancement module enriches the visual fidelity of text-only nodes by constructing visual representations using text embeddings. Furthermore, our relation predictor leverages node representations to infer absent relationships between nodes, resulting in more coherent scene layouts. Extensive experimental results demonstrate that MMGDreamer exhibits superior control of object geometry, achieving state-of-the-art scene generation performance. Project page: https://yangzhifeio.github.io/project/MMGDreamer.
Large Language Models for Bioinformatics
Jan 10, 2025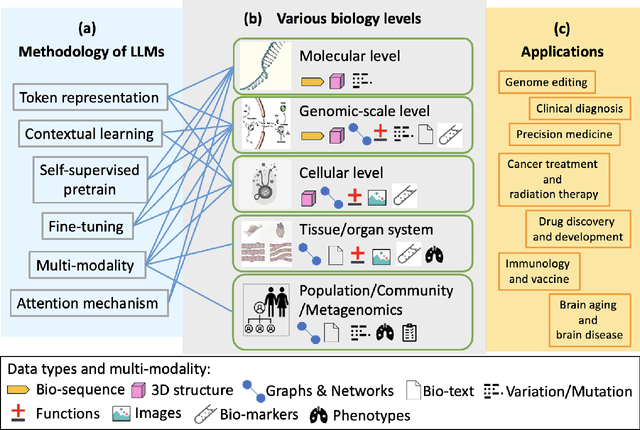
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
Opportunities and Challenges of Large Language Models for Low-Resource Languages in Humanities Research
Dec 09, 2024Low-resource languages serve as invaluable repositories of human history, embodying cultural evolution and intellectual diversity. Despite their significance, these languages face critical challenges, including data scarcity and technological limitations, which hinder their comprehensive study and preservation. Recent advancements in large language models (LLMs) offer transformative opportunities for addressing these challenges, enabling innovative methodologies in linguistic, historical, and cultural research. This study systematically evaluates the applications of LLMs in low-resource language research, encompassing linguistic variation, historical documentation, cultural expressions, and literary analysis. By analyzing technical frameworks, current methodologies, and ethical considerations, this paper identifies key challenges such as data accessibility, model adaptability, and cultural sensitivity. Given the cultural, historical, and linguistic richness inherent in low-resource languages, this work emphasizes interdisciplinary collaboration and the development of customized models as promising avenues for advancing research in this domain. By underscoring the potential of integrating artificial intelligence with the humanities to preserve and study humanity's linguistic and cultural heritage, this study fosters global efforts towards safeguarding intellectual diversity.
Foundation Models for Low-Resource Language Education (Vision Paper)
Dec 06, 2024Recent studies show that large language models (LLMs) are powerful tools for working with natural language, bringing advances in many areas of computational linguistics. However, these models face challenges when applied to low-resource languages due to limited training data and difficulty in understanding cultural nuances. Research is now focusing on multilingual models to improve LLM performance for these languages. Education in these languages also struggles with a lack of resources and qualified teachers, particularly in underdeveloped regions. Here, LLMs can be transformative, supporting innovative methods like community-driven learning and digital platforms. This paper discusses how LLMs could enhance education for low-resource languages, emphasizing practical applications and benefits.
QueEn: A Large Language Model for Quechua-English Translation
Dec 06, 2024

Recent studies show that large language models (LLMs) are powerful tools for working with natural language, bringing advances in many areas of computational linguistics. However, these models face challenges when applied to low-resource languages due to limited training data and difficulty in understanding cultural nuances. In this paper, we propose QueEn, a novel approach for Quechua-English translation that combines Retrieval-Augmented Generation (RAG) with parameter-efficient fine-tuning techniques. Our method leverages external linguistic resources through RAG and uses Low-Rank Adaptation (LoRA) for efficient model adaptation. Experimental results show that our approach substantially exceeds baseline models, with a BLEU score of 17.6 compared to 1.5 for standard GPT models. The integration of RAG with fine-tuning allows our system to address the challenges of low-resource language translation while maintaining computational efficiency. This work contributes to the broader goal of preserving endangered languages through advanced language technologies.