 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Reasoning Abilities Under Non-Ideal Conditions After RL-Fine-Tuning
Aug 06, 2025Reinforcement learning (RL) has become a key technique for enhancing the reasoning abilities of large language models (LLMs), with policy-gradient algorithms dominating the post-training stage because of their efficiency and effectiveness. However, most existing benchmarks evaluate large-language-model reasoning under idealized settings, overlooking performance in realistic, non-ideal scenarios. We identify three representative non-ideal scenarios with practical relevance: summary inference, fine-grained noise suppression, and contextual filtering. We introduce a new research direction guided by brain-science findings that human reasoning remains reliable under imperfect inputs. We formally define and evaluate these challenging scenarios. We fine-tune three LLMs and a state-of-the-art large vision-language model (LVLM) using RL with a representative policy-gradient algorithm and then test their performance on eight public datasets. Our results reveal that while RL fine-tuning improves baseline reasoning under idealized settings, performance declines significantly across all three non-ideal scenarios, exposing critical limitations in advanced reasoning capabilities. Although we propose a scenario-specific remediation method, our results suggest current methods leave these reasoning deficits largely unresolved. This work highlights that the reasoning abilities of large models are often overstated and underscores the importance of evaluating models under non-ideal scenarios. The code and data will be released at XXXX.
NGENT: Next-Generation AI Agents Must Integrate Multi-Domain Abilities to Achieve Artificial General Intelligence
Apr 30, 2025This paper argues that the next generation of AI agent (NGENT) should integrate across-domain abilities to advance toward Artificial General Intelligence (AGI). Although current AI agents are effective in specialized tasks such as robotics, role-playing, and tool-using, they remain confined to narrow domains. We propose that future AI agents should synthesize the strengths of these specialized systems into a unified framework capable of operating across text, vision, robotics, reinforcement learning, emotional intelligence, and beyond. This integration is not only feasible but also essential for achieving the versatility and adaptability that characterize human intelligence. The convergence of technologies across AI domains, coupled with increasing user demand for cross-domain capabilities, suggests that such integration is within reach. Ultimately, the development of these versatile agents is a critical step toward realizing AGI. This paper explores the rationale for this shift, potential pathways for achieving it.
MMGDreamer: Mixed-Modality Graph for Geometry-Controllable 3D Indoor Scene Generation
Feb 09, 2025Controllable 3D scene generation has extensive applications in virtual reality and interior design, where the generated scenes should exhibit high levels of realism and controllability in terms of geometry. Scene graphs provide a suitable data representation that facilitates these applications. However, current graph-based methods for scene generation are constrained to text-based inputs and exhibit insufficient adaptability to flexible user inputs, hindering the ability to precisely control object geometry. To address this issue, we propose MMGDreamer, a dual-branch diffusion model for scene generation that incorporates a novel Mixed-Modality Graph, visual enhancement module, and relation predictor. The mixed-modality graph allows object nodes to integrate textual and visual modalities, with optional relationships between nodes. It enhances adaptability to flexible user inputs and enables meticulous control over the geometry of objects in the generated scenes. The visual enhancement module enriches the visual fidelity of text-only nodes by constructing visual representations using text embeddings. Furthermore, our relation predictor leverages node representations to infer absent relationships between nodes, resulting in more coherent scene layouts. Extensive experimental results demonstrate that MMGDreamer exhibits superior control of object geometry, achieving state-of-the-art scene generation performance. Project page: https://yangzhifeio.github.io/project/MMGDreamer.
A Generic Method for Fine-grained Category Discovery in Natural Language Texts
Jun 18, 2024


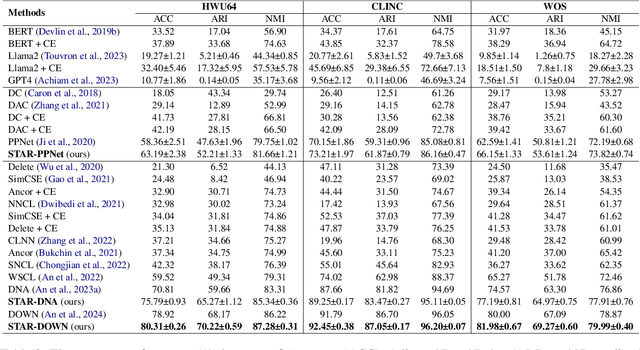
Fine-grained category discovery using only coarse-grained supervision is a cost-effective yet challenging task. Previous training methods focus on aligning query samples with positive samples and distancing them from negatives. They often neglect intra-category and inter-category semantic similarities of fine-grained categories when navigating sample distributions in the embedding space. Furthermore, some evaluation techniques that rely on pre-collected test samples are inadequate for real-time applications. To address these shortcomings, we introduce a method that successfully detects fine-grained clusters of semantically similar texts guided by a novel objective function. The method uses semantic similarities in a logarithmic space to guide sample distributions in the Euclidean space and to form distinct clusters that represent fine-grained categories. We also propose a centroid inference mechanism to support real-time applications. The efficacy of the method is both theoretically justified and empirically confirmed on three benchmark tasks. The proposed objective function is integrated in multiple contrastive learning based neural models. Its results surpass existing state-of-the-art approaches in terms of Accuracy, Adjusted Rand Index and Normalized Mutual Information of the detected fine-grained categories. Code and data will be available at https://github.com/XX upon publication.
Understanding the Weakness of Large Language Model Agents within a Complex Android Environment
Feb 09, 2024



Large language models (LLMs) have empowered intelligent agents to execute intricate tasks within domain-specific software such as browsers and games. However, when applied to general-purpose software systems like operating systems, LLM agents face three primary challenges. Firstly, the action space is vast and dynamic, posing difficulties for LLM agents to maintain an up-to-date understanding and deliver accurate responses. Secondly, real-world tasks often require inter-application cooperation}, demanding farsighted planning from LLM agents. Thirdly, agents need to identify optimal solutions aligning with user constraints, such as security concerns and preferences. These challenges motivate AndroidArena, an environment and benchmark designed to evaluate LLM agents on a modern operating system. To address high-cost of manpower, we design a scalable and semi-automated method to construct the benchmark. In the task evaluation, AndroidArena incorporates accurate and adaptive metrics to address the issue of non-unique solutions. Our findings reveal that even state-of-the-art LLM agents struggle in cross-APP scenarios and adhering to specific constraints. Additionally, we identify a lack of four key capabilities, i.e., understanding, reasoning, exploration, and reflection, as primary reasons for the failure of LLM agents. Furthermore, we provide empirical analysis on the failure of reflection, and improve the success rate by 27% with our proposed exploration strategy. This work is the first to present valuable insights in understanding fine-grained weakness of LLM agents, and offers a path forward for future research in this area. Environment, benchmark, and evaluation code for AndroidArena are released at https://github.com/AndroidArenaAgent/AndroidArena.