 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCleanCodec: Efficient and Robust Speech Tokenization via Perceptually Guided Encoding
Jun 03, 2026Neural audio codecs are a key component of speech processing pipelines, compressing audio into discrete tokens for downstream modeling. However, existing codecs struggle to balance reconstruction quality with token efficiency, often encoding perceptually irrelevant information such as background noise and recording artifacts at the expense of linguistically and acoustically meaningful content. We reframe audio tokenization as a selective information bottleneck problem and propose CleanCodec, a denoising audio codec which learns to encode only perceptually important features and discard imperceptible information. At just 12.5 tokens per second, CleanCodec achieves state-of-the-art tokenization efficiency, substantially outperforming existing codecs in speaker similarity and speech intelligibility. Evaluations on downstream text-to-speech and voice conversion tasks further demonstrate improved performance and up to 17x faster inference, highlighting significant efficiency gains.
The Tool Illusion: Rethinking Tool Use in Web Agents
Apr 03, 2026As web agents rapidly evolve, an increasing body of work has moved beyond conventional atomic browser interactions and explored tool use as a higher-level action paradigm. Although prior studies have shown the promise of tools, their conclusions are often drawn from limited experimental scales and sometimes non-comparable settings. As a result, several fundamental questions remain unclear: i) whether tools provide consistent gains for web agents, ii) what practical design principles characterize effective tools, and iii) what side effects tool use may introduce. To establish a stronger empirical foundation for future research, we revisit tool use in web agents through an extensive and carefully controlled study across diverse tool sources, backbone models, tool-use frameworks, and evaluation benchmarks. Our findings both revise some prior conclusions and complement others with broader evidence. We hope this study provides a more reliable empirical basis and inspires future research on tool-use web agents.
M2-Verify: A Large-Scale Multidomain Benchmark for Checking Multimodal Claim Consistency
Apr 01, 2026Evaluating scientific arguments requires assessing the strict consistency between a claim and its underlying multimodal evidence. However, existing benchmarks lack the scale, domain diversity, and visual complexity needed to evaluate this alignment realistically. To address this gap, we introduce M2-Verify, a large-scale multimodal dataset for checking scientific claim consistency. Sourced from PubMed and arXiv, M2-Verify provides over 469K instances across 16 domains, rigorously validated through expert audits. Extensive baseline experiments show that state-of-the-art models struggle to maintain robust consistency. While top models achieve up to 85.8\% Micro-F1 on low-complexity medical perturbations, performance drops to 61.6\% on high-complexity challenges like anatomical shifts. Furthermore, expert evaluations expose hallucinations when models generate scientific explanations for their alignment decisions. Finally, we demonstrate our dataset's utility and provide comprehensive usage guidelines.
Accurate and Scalable Matrix Mechanisms via Divide and Conquer
Apr 01, 2026Matrix mechanisms are often used to provide unbiased differentially private query answers when publishing statistics or creating synthetic data. Recent work has developed matrix mechanisms, such as ResidualPlanner and Weighted Fourier Factorizations, that scale to high dimensional datasets while providing optimality guarantees for workloads such as marginals and circular product queries. They operate by adding noise to a linearly independent set of queries that can compactly represent the desired workloads. In this paper, we present QuerySmasher, an alternative scalable approach based on a divide-and-conquer strategy. Given a workload that can be answered from various data marginals, QuerySmasher splits each query into sub-queries and re-assembles the pieces into mutually orthogonal sub-workloads. These sub-workloads represent small, low-dimensional problems that can be independently and optimally answered by existing low-dimensional matrix mechanisms. QuerySmasher then stitches these solutions together to answer queries in the original workload. We show that QuerySmasher subsumes prior work, like ResidualPlanner (RP), ResidualPlanner+ (RP+), and Weighted Fourier Factorizations (WFF). We prove that it can dominate those approaches, under sum squared error, for all workloads. We also experimentally demonstrate the scalability and accuracy of QuerySmasher.
Bridging the Know-Act Gap via Task-Level Autoregressive Reasoning
Mar 23, 2026LLMs often generate seemingly valid answers to flawed or ill-posed inputs. This is not due to missing knowledge: under discriminative prompting, the same models can mostly identify such issues, yet fail to reflect this in standard generative responses. This reveals a fundamental know-act gap between discriminative recognition and generative behavior. Prior work largely characterizes this issue in narrow settings, such as math word problems or question answering, with limited focus on how to integrate these two modes. In this work, we present a comprehensive analysis using FaultyScience, a newly constructed large-scale, cross-disciplinary benchmark of faulty scientific questions. We show that the gap is pervasive and stems from token-level autoregression, which entangles task selection (validate vs. answer) with content generation, preventing discriminative knowledge from being utilized. To address this, we propose DeIllusionLLM, a task-level autoregressive framework that explicitly models this decision. Through self-distillation, the model unifies discriminative judgment and generative reasoning within a single backbone. Empirically, DeIllusionLLM substantially reduces answer-despite-error failures under natural prompting while maintaining general reasoning performance, demonstrating that self-distillation is an effective and scalable solution for bridging the discriminative-generative know-act gap
Functionality-Oriented LLM Merging on the Fisher--Rao Manifold
Mar 05, 2026Weight-space merging aims to combine multiple fine-tuned LLMs into a single model without retraining, yet most existing approaches remain fundamentally parameter-space heuristics. This creates three practical limitations. First, linear averaging, task vectors, and related rules operate on Euclidean coordinates, even though the desired goal is to merge functionality, i.e., predictive behaviors across tasks. Second, when the source checkpoints are farther apart or more heterogeneous, Euclidean blends often trigger representation collapse, manifested as activation variance shrinkage and effective-rank degradation, which sharply degrades accuracy. Third, many geometry-inspired methods are most natural for two-model interpolation and do not extend cleanly to merging N>2 experts with a principled objective. We address these issues by formulating model merging as computing a weighted Karcher mean on the Fisher--Rao manifold, which is locally equivalent to minimizing a KL-based function distance between predictive distributions. We derive a practical fixed-point algorithm using a lightweight spherical proxy that preserves norms and generalizes directly to multi-expert merging. Across various benchmarks and collapse diagnostics, our method remains stable as the number and heterogeneity of merged models increase, consistently outperforming prior baselines.
Understanding Dynamic Compute Allocation in Recurrent Transformers
Feb 09, 2026Token-level adaptive computation seeks to reduce inference cost by allocating more computation to harder tokens and less to easier ones. However, prior work is primarily evaluated on natural-language benchmarks using task-level metrics, where token-level difficulty is unobservable and confounded with architectural factors, making it unclear whether compute allocation truly aligns with underlying complexity. We address this gap through three contributions. First, we introduce a complexity-controlled evaluation paradigm using algorithmic and synthetic language tasks with parameterized difficulty, enabling direct testing of token-level compute allocation. Second, we propose ANIRA, a unified recurrent Transformer framework that supports per-token variable-depth computation while isolating compute allocation decisions from other model factors. Third, we use this framework to conduct a systematic analysis of token-level adaptive computation across alignment with complexity, generalization, and decision timing. Our results show that compute allocation aligned with task complexity can emerge without explicit difficulty supervision, but such alignment does not imply algorithmic generalization: models fail to extrapolate to unseen input sizes despite allocating additional computation. We further find that early compute decisions rely on static structural cues, whereas online halting more closely tracks algorithmic execution state.
DIAGPaper: Diagnosing Valid and Specific Weaknesses in Scientific Papers via Multi-Agent Reasoning
Jan 12, 2026Paper weakness identification using single-agent or multi-agent LLMs has attracted increasing attention, yet existing approaches exhibit key limitations. Many multi-agent systems simulate human roles at a surface level, missing the underlying criteria that lead experts to assess complementary intellectual aspects of a paper. Moreover, prior methods implicitly assume identified weaknesses are valid, ignoring reviewer bias, misunderstanding, and the critical role of author rebuttals in validating review quality. Finally, most systems output unranked weakness lists, rather than prioritizing the most consequential issues for users. In this work, we propose DIAGPaper, a novel multi-agent framework that addresses these challenges through three tightly integrated modules. The customizer module simulates human-defined review criteria and instantiates multiple reviewer agents with criterion-specific expertise. The rebuttal module introduces author agents that engage in structured debate with reviewer agents to validate and refine proposed weaknesses. The prioritizer module learns from large-scale human review practices to assess the severity of validated weaknesses and surfaces the top-K severest ones to users. Experiments on two benchmarks, AAAR and ReviewCritique, demonstrate that DIAGPaper substantially outperforms existing methods by producing more valid and more paper-specific weaknesses, while presenting them in a user-oriented, prioritized manner.
ScaleFormer: Span Representation Cumulation for Long-Context Transformer
Nov 13, 2025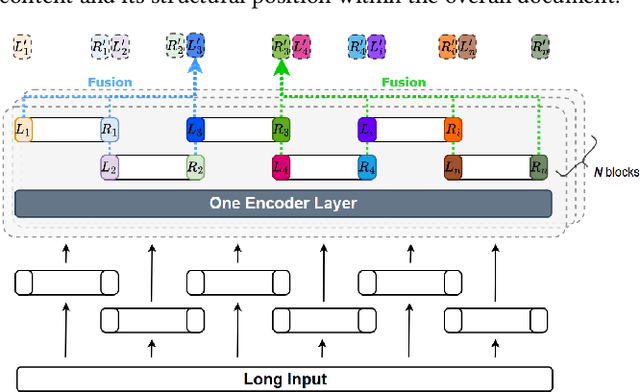


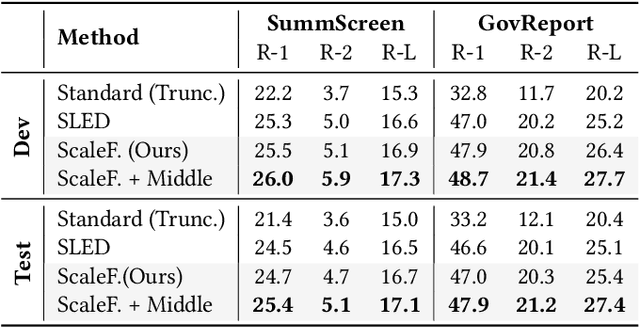
The quadratic complexity of standard self-attention severely limits the application of Transformer-based models to long-context tasks. While efficient Transformer variants exist, they often require architectural changes and costly pre-training from scratch. To circumvent this, we propose ScaleFormer(Span Representation Cumulation for Long-Context Transformer) - a simple and effective plug-and-play framework that adapts off-the-shelf pre-trained encoder-decoder models to process long sequences without requiring architectural modifications. Our approach segments long inputs into overlapping chunks and generates a compressed, context-aware representation for the decoder. The core of our method is a novel, parameter-free fusion mechanism that endows each chunk's representation with structural awareness of its position within the document. It achieves this by enriching each chunk's boundary representations with cumulative context vectors from all preceding and succeeding chunks. This strategy provides the model with a strong signal of the document's narrative flow, achieves linear complexity, and enables pre-trained models to reason effectively over long-form text. Experiments on long-document summarization show that our method is highly competitive with and often outperforms state-of-the-art approaches without requiring architectural modifications or external retrieval mechanisms.
SIM: A mapping framework for built environment auditing based on street view imagery
May 29, 2025Built environment auditing refers to the systematic documentation and assessment of urban and rural spaces' physical, social, and environmental characteristics, such as walkability, road conditions, and traffic lights. It is used to collect data for the evaluation of how built environments impact human behavior, health, mobility, and overall urban functionality. Traditionally, built environment audits were conducted using field surveys and manual observations, which were time-consuming and costly. The emerging street view imagery, e.g., Google Street View, has become a widely used data source for conducting built environment audits remotely. Deep learning and computer vision techniques can extract and classify objects from street images to enhance auditing productivity. Before meaningful analysis, the detected objects need to be geospatially mapped for accurate documentation. However, the mapping methods and tools based on street images are underexplored, and there are no universal frameworks or solutions yet, imposing difficulties in auditing the street objects. In this study, we introduced an open source street view mapping framework, providing three pipelines to map and measure: 1) width measurement for ground objects, such as roads; 2) 3D localization for objects with a known dimension (e.g., doors and stop signs); and 3) diameter measurements (e.g., street trees). These pipelines can help researchers, urban planners, and other professionals automatically measure and map target objects, promoting built environment auditing productivity and accuracy. Three case studies, including road width measurement, stop sign localization, and street tree diameter measurement, are provided in this paper to showcase pipeline usage.