 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioMol-MQA: A Multi-Modal Question Answering Dataset For LLM Reasoning Over Bio-Molecular Interactions
Jun 06, 2025



Retrieval augmented generation (RAG) has shown great power in improving Large Language Models (LLMs). However, most existing RAG-based LLMs are dedicated to retrieving single modality information, mainly text; while for many real-world problems, such as healthcare, information relevant to queries can manifest in various modalities such as knowledge graph, text (clinical notes), and complex molecular structure. Thus, being able to retrieve relevant multi-modality domain-specific information, and reason and synthesize diverse knowledge to generate an accurate response is important. To address the gap, we present BioMol-MQA, a new question-answering (QA) dataset on polypharmacy, which is composed of two parts (i) a multimodal knowledge graph (KG) with text and molecular structure for information retrieval; and (ii) challenging questions that designed to test LLM capabilities in retrieving and reasoning over multimodal KG to answer questions. Our benchmarks indicate that existing LLMs struggle to answer these questions and do well only when given the necessary background data, signaling the necessity for strong RAG frameworks.
MAG-V: A Multi-Agent Framework for Synthetic Data Generation and Verification
Nov 28, 2024Extending the capabilities of Large Language Models (LLMs) with functions or tools for environment interaction has led to the emergence of the agent paradigm. In industry, training an LLM is not always feasible because of the scarcity of domain data, legal holds on proprietary customer data, rapidly changing business requirements, and the need to prototype new assistants. Agents provide an elegant solution to the above by relying on the zero-shot reasoning abilities of the underlying LLM and utilizing tools to explore and reason over customer data and respond to user requests. However, there are two concerns here: (I) acquiring large scale customer queries for agent testing is time-consuming, and (II) high reliance on the tool call sequence (or trajectory) followed by the agent to respond to user queries may lead to unexpected or incorrect behavior. To address this, we propose MAG-V, a multi-agent framework to first generate a dataset of questions that mimic customer queries; and second, reverse-engineer alternate questions from the responses for trajectory verification. Initial results indicate that our synthetic data can improve agent performance on actual customer queries. Furthermore, our trajectory verification methodology, inspired by distant supervision and using traditional machine learning (ML) models, outperforms a GPT-4o judge baseline by 11% accuracy and matches the performance of a GPT-4 judge on our constructed dataset. Overall, our approach is a step towards unifying diverse task agents into a cohesive framework for achieving an aligned objective.
Exploring Language Model Generalization in Low-Resource Extractive QA
Sep 27, 2024In this paper, we investigate Extractive Question Answering (EQA) with Large Language Models (LLMs) under domain drift, i.e., can LLMs generalize well to closed-domains that require specific knowledge such as medicine and law in a zero-shot fashion without additional in-domain training? To this end, we devise a series of experiments to empirically explain the performance gap. Our findings suggest that: a) LLMs struggle with dataset demands of closed-domains such as retrieving long answer-spans; b) Certain LLMs, despite showing strong overall performance, display weaknesses in meeting basic requirements as discriminating between domain-specific senses of words which we link to pre-processing decisions; c) Scaling model parameters is not always effective for cross-domain generalization; and d) Closed-domain datasets are quantitatively much different than open-domain EQA datasets and current LLMs struggle to deal with them. Our findings point out important directions for improving existing LLMs.
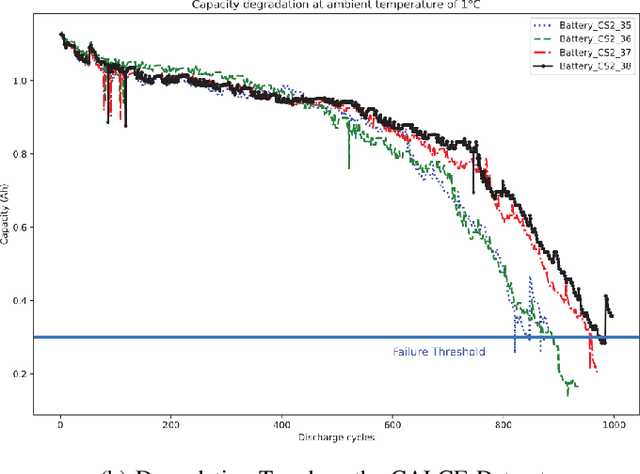
The State of Lithium-Ion Battery Health Prognostics in the CPS Era
Mar 28, 2024Lithium-ion batteries (Li-ion) have revolutionized energy storage technology, becoming integral to our daily lives by powering a diverse range of devices and applications. Their high energy density, fast power response, recyclability, and mobility advantages have made them the preferred choice for numerous sectors. This paper explores the seamless integration of Prognostics and Health Management within batteries, presenting a multidisciplinary approach that enhances the reliability, safety, and performance of these powerhouses. Remaining useful life (RUL), a critical concept in prognostics, is examined in depth, emphasizing its role in predicting component failure before it occurs. The paper reviews various RUL prediction methods, from traditional models to cutting-edge data-driven techniques. Furthermore, it highlights the paradigm shift toward deep learning architectures within the field of Li-ion battery health prognostics, elucidating the pivotal role of deep learning in addressing battery system complexities. Practical applications of PHM across industries are also explored, offering readers insights into real-world implementations.This paper serves as a comprehensive guide, catering to both researchers and practitioners in the field of Li-ion battery PHM.
Leveraging External Knowledge Resources to Enable Domain-Specific Comprehension
Jan 15, 2024



Machine Reading Comprehension (MRC) has been a long-standing problem in NLP and, with the recent introduction of the BERT family of transformer based language models, it has come a long way to getting solved. Unfortunately, however, when BERT variants trained on general text corpora are applied to domain-specific text, their performance inevitably degrades on account of the domain shift i.e. genre/subject matter discrepancy between the training and downstream application data. Knowledge graphs act as reservoirs for either open or closed domain information and prior studies have shown that they can be used to improve the performance of general-purpose transformers in domain-specific applications. Building on existing work, we introduce a method using Multi-Layer Perceptrons (MLPs) for aligning and integrating embeddings extracted from knowledge graphs with the embeddings spaces of pre-trained language models (LMs). We fuse the aligned embeddings with open-domain LMs BERT and RoBERTa, and fine-tune them for two MRC tasks namely span detection (COVID-QA) and multiple-choice questions (PubMedQA). On the COVID-QA dataset, we see that our approach allows these models to perform similar to their domain-specific counterparts, Bio/Sci-BERT, as evidenced by the Exact Match (EM) metric. With regards to PubMedQA, we observe an overall improvement in accuracy while the F1 stays relatively the same over the domain-specific models.
Milestones in Bengali Sentiment Analysis leveraging Transformer-models: Fundamentals, Challenges and Future Directions
Jan 15, 2024Sentiment Analysis (SA) refers to the task of associating a view polarity (usually, positive, negative, or neutral; or even fine-grained such as slightly angry, sad, etc.) to a given text, essentially breaking it down to a supervised (since we have the view labels apriori) classification task. Although heavily studied in resource-rich languages such as English thus pushing the SOTA by leaps and bounds, owing to the arrival of the Transformer architecture, the same cannot be said for resource-poor languages such as Bengali (BN). For a language spoken by roughly 300 million people, the technology enabling them to run trials on their favored tongue is severely lacking. In this paper, we analyze the SOTA for SA in Bengali, particularly, Transformer-based models. We discuss available datasets, their drawbacks, the nuances associated with Bengali i.e. what makes this a challenging language to apply SA on, and finally provide insights for future direction to mitigate the limitations in the field.
Quality > Quantity: Synthetic Corpora from Foundation Models for Closed-Domain Extractive Question Answering
Oct 25, 2023



Domain adaptation, the process of training a model in one domain and applying it to another, has been extensively explored in machine learning. While training a domain-specific foundation model (FM) from scratch is an option, recent methods have focused on adapting pre-trained FMs for domain-specific tasks. However, our experiments reveal that either approach does not consistently achieve state-of-the-art (SOTA) results in the target domain. In this work, we study extractive question answering within closed domains and introduce the concept of targeted pre-training. This involves determining and generating relevant data to further pre-train our models, as opposed to the conventional philosophy of utilizing domain-specific FMs trained on a wide range of data. Our proposed framework uses Galactica to generate synthetic, ``targeted'' corpora that align with specific writing styles and topics, such as research papers and radiology reports. This process can be viewed as a form of knowledge distillation. We apply our method to two biomedical extractive question answering datasets, COVID-QA and RadQA, achieving a new benchmark on the former and demonstrating overall improvements on the latter. Code available at https://github.com/saptarshi059/CDQA-v1-Targetted-PreTraining/tree/main.
De-SaTE: Denoising Self-attention Transformer Encoders for Li-ion Battery Health Prognostics
Sep 28, 2023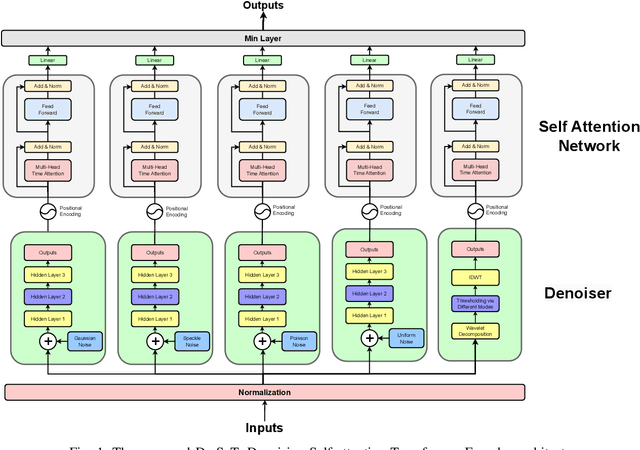


Lithium Ion (Li-ion) batteries have gained widespread popularity across various industries, from powering portable electronic devices to propelling electric vehicles and supporting energy storage systems. A central challenge in managing Li-ion batteries effectively is accurately predicting their Remaining Useful Life (RUL), which is a critical measure for proactive maintenance and predictive analytics. This study presents a novel approach that harnesses the power of multiple denoising modules, each trained to address specific types of noise commonly encountered in battery data. Specifically we use a denoising auto-encoder and a wavelet denoiser to generate encoded/decomposed representations, which are subsequently processed through dedicated self-attention transformer encoders. After extensive experimentation on the NASA and CALCE datasets, we are able to characterize a broad spectrum of health indicator estimations under a set of diverse noise patterns. We find that our reported error metrics on these datasets are on par or better with the best reported in recent literature.
TFBEST: Dual-Aspect Transformer with Learnable Positional Encoding for Failure Prediction
Sep 06, 2023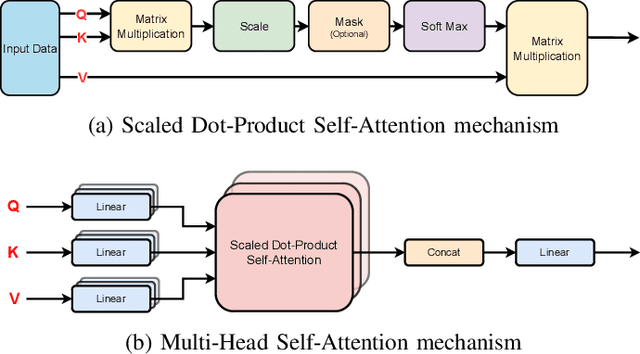
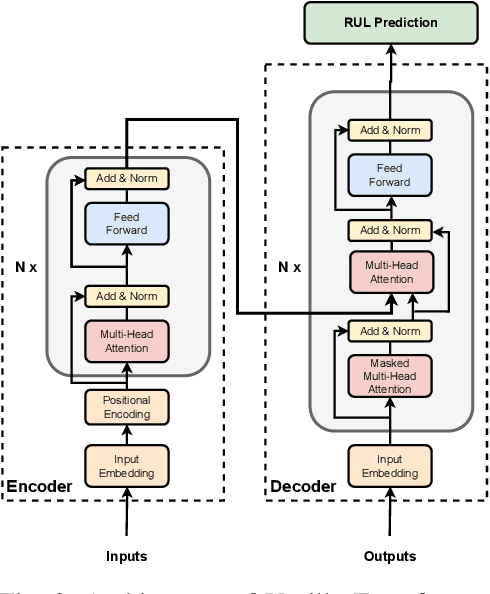
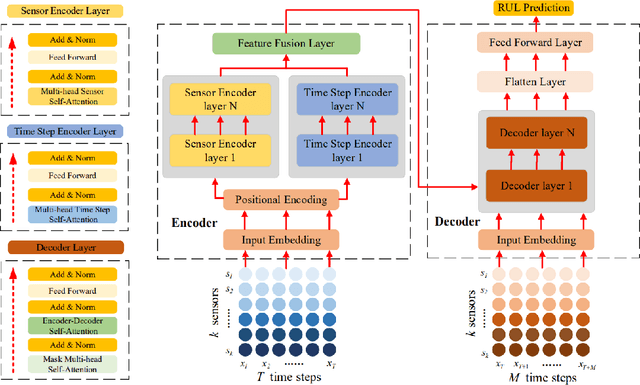
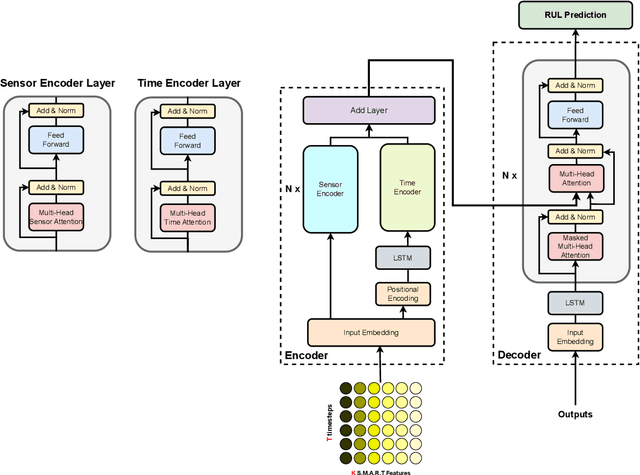
Hard Disk Drive (HDD) failures in datacenters are costly - from catastrophic data loss to a question of goodwill, stakeholders want to avoid it like the plague. An important tool in proactively monitoring against HDD failure is timely estimation of the Remaining Useful Life (RUL). To this end, the Self-Monitoring, Analysis and Reporting Technology employed within HDDs (S.M.A.R.T.) provide critical logs for long-term maintenance of the security and dependability of these essential data storage devices. Data-driven predictive models in the past have used these S.M.A.R.T. logs and CNN/RNN based architectures heavily. However, they have suffered significantly in providing a confidence interval around the predicted RUL values as well as in processing very long sequences of logs. In addition, some of these approaches, such as those based on LSTMs, are inherently slow to train and have tedious feature engineering overheads. To overcome these challenges, in this work we propose a novel transformer architecture - a Temporal-fusion Bi-encoder Self-attention Transformer (TFBEST) for predicting failures in hard-drives. It is an encoder-decoder based deep learning technique that enhances the context gained from understanding health statistics sequences and predicts a sequence of the number of days remaining before a disk potentially fails. In this paper, we also provide a novel confidence margin statistic that can help manufacturers replace a hard-drive within a time frame. Experiments on Seagate HDD data show that our method significantly outperforms the state-of-the-art RUL prediction methods during testing over the exhaustive 10-year data from Backblaze (2013-present). Although validated on HDD failure prediction, the TFBEST architecture is well-suited for other prognostics applications and may be adapted for allied regression problems.
Spatio-temporal Storytelling? Leveraging Generative Models for Semantic Trajectory Analysis
Jun 24, 2023
In this paper, we lay out a vision for analysing semantic trajectory traces and generating synthetic semantic trajectory data (SSTs) using generative language model. Leveraging the advancements in deep learning, as evident by progress in the field of natural language processing (NLP), computer vision, etc. we intend to create intelligent models that can study the semantic trajectories in various contexts, predicting future trends, increasing machine understanding of the movement of animals, humans, goods, etc. enhancing human-computer interactions, and contributing to an array of applications ranging from urban-planning to personalized recommendation engines and business strategy.