 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-intrusive Learning of Physics-Informed Spatio-temporal Surrogate for Accelerating Design
Apr 15, 2026Most practical engineering design problems involve nonlinear spatio-temporal dynamical systems. Multi-physics simulations are often performed to capture the fine spatio-temporal scales which govern the evolution of these systems. However, these simulations are often high-fidelity in nature, and can be computationally very expensive. Hence, generating data from these expensive simulations becomes a bottleneck in an end-to-end engineering design process. Spatio-temporal surrogate modeling of these dynamical systems has been a popular data-driven solution to tackle this computational bottleneck. This is because accurate machine learning models emulating the dynamical systems can be orders of magnitude faster than the actual simulations. However, one key limitation of purely data-driven approaches is their lack of generalizability to inputs outside the training distribution. In this paper, we propose a physics-informed spatio-temporal surrogate modeling (PISTM) framework constrained by the physics of the underlying dynamical system. The framework leverages state-of-the-art advancements in the field of Koopman autoencoders to learn the underlying spatio-temporal dynamics in a non-intrusive manner, coupled with a spatio-temporal surrogate model which predicts the behavior of the Koopman operator in a specified time window for unknown operating conditions. We evaluate our framework on a prototypical fluid flow problem of interest: two-dimensional incompressible flow around a cylinder.
FROST: Filtering Reasoning Outliers with Attention for Efficient Reasoning
Jan 26, 2026We propose FROST, an attention-aware method for efficient reasoning. Unlike traditional approaches, FROST leverages attention weights to prune uncritical reasoning paths, yielding shorter and more reliable reasoning trajectories. Methodologically, we introduce the concept of reasoning outliers and design an attention-based mechanism to remove them. Theoretically, FROST preserves and enhances the model's reasoning capacity while eliminating outliers at the sentence level. Empirically, we validate FROST on four benchmarks using two strong reasoning models (Phi-4-Reasoning and GPT-OSS-20B), outperforming state-of-the-art methods such as TALE and ThinkLess. Notably, FROST achieves an average 69.68% reduction in token usage and a 26.70% improvement in accuracy over the base model. Furthermore, in evaluations of attention outlier metrics, FROST reduces the maximum infinity norm by 15.97% and the average kurtosis by 91.09% compared to the base model. Code is available at https://github.com/robinzixuan/FROST
DKL-KAN: Scalable Deep Kernel Learning using Kolmogorov-Arnold Networks
Jul 30, 2024



The need for scalable and expressive models in machine learning is paramount, particularly in applications requiring both structural depth and flexibility. Traditional deep learning methods, such as multilayer perceptrons (MLP), offer depth but lack ability to integrate structural characteristics of deep learning architectures with non-parametric flexibility of kernel methods. To address this, deep kernel learning (DKL) was introduced, where inputs to a base kernel are transformed using a deep learning architecture. These kernels can replace standard kernels, allowing both expressive power and scalability. The advent of Kolmogorov-Arnold Networks (KAN) has generated considerable attention and discussion among researchers in scientific domain. In this paper, we introduce a scalable deep kernel using KAN (DKL-KAN) as an effective alternative to DKL using MLP (DKL-MLP). Our approach involves simultaneously optimizing these kernel attributes using marginal likelihood within a Gaussian process framework. We analyze two variants of DKL-KAN for a fair comparison with DKL-MLP: one with same number of neurons and layers as DKL-MLP, and another with approximately same number of trainable parameters. To handle large datasets, we use kernel interpolation for scalable structured Gaussian processes (KISS-GP) for low-dimensional inputs and KISS-GP with product kernels for high-dimensional inputs. The efficacy of DKL-KAN is evaluated in terms of computational training time and test prediction accuracy across a wide range of applications. Additionally, the effectiveness of DKL-KAN is also examined in modeling discontinuities and accurately estimating prediction uncertainty. The results indicate that DKL-KAN outperforms DKL-MLP on datasets with a low number of observations. Conversely, DKL-MLP exhibits better scalability and higher test prediction accuracy on datasets with large number of observations.
Leveraging External Knowledge Resources to Enable Domain-Specific Comprehension
Jan 15, 2024



Machine Reading Comprehension (MRC) has been a long-standing problem in NLP and, with the recent introduction of the BERT family of transformer based language models, it has come a long way to getting solved. Unfortunately, however, when BERT variants trained on general text corpora are applied to domain-specific text, their performance inevitably degrades on account of the domain shift i.e. genre/subject matter discrepancy between the training and downstream application data. Knowledge graphs act as reservoirs for either open or closed domain information and prior studies have shown that they can be used to improve the performance of general-purpose transformers in domain-specific applications. Building on existing work, we introduce a method using Multi-Layer Perceptrons (MLPs) for aligning and integrating embeddings extracted from knowledge graphs with the embeddings spaces of pre-trained language models (LMs). We fuse the aligned embeddings with open-domain LMs BERT and RoBERTa, and fine-tune them for two MRC tasks namely span detection (COVID-QA) and multiple-choice questions (PubMedQA). On the COVID-QA dataset, we see that our approach allows these models to perform similar to their domain-specific counterparts, Bio/Sci-BERT, as evidenced by the Exact Match (EM) metric. With regards to PubMedQA, we observe an overall improvement in accuracy while the F1 stays relatively the same over the domain-specific models.
LLMs for Multi-Modal Knowledge Extraction and Analysis in Intelligence/Safety-Critical Applications
Dec 05, 2023Large Language Models have seen rapid progress in capability in recent years; this progress has been accelerating and their capabilities, measured by various benchmarks, are beginning to approach those of humans. There is a strong demand to use such models in a wide variety of applications but, due to unresolved vulnerabilities and limitations, great care needs to be used before applying them to intelligence and safety-critical applications. This paper reviews recent literature related to LLM assessment and vulnerabilities to synthesize the current research landscape and to help understand what advances are most critical to enable use of of these technologies in intelligence and safety-critical applications. The vulnerabilities are broken down into ten high-level categories and overlaid onto a high-level life cycle of an LLM. Some general categories of mitigations are reviewed.
Scalable Bayesian optimization with high-dimensional outputs using randomized prior networks
Feb 14, 2023

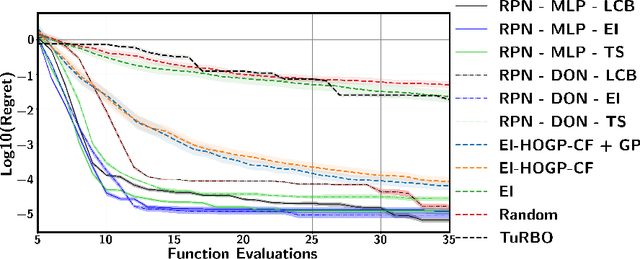
Several fundamental problems in science and engineering consist of global optimization tasks involving unknown high-dimensional (black-box) functions that map a set of controllable variables to the outcomes of an expensive experiment. Bayesian Optimization (BO) techniques are known to be effective in tackling global optimization problems using a relatively small number objective function evaluations, but their performance suffers when dealing with high-dimensional outputs. To overcome the major challenge of dimensionality, here we propose a deep learning framework for BO and sequential decision making based on bootstrapped ensembles of neural architectures with randomized priors. Using appropriate architecture choices, we show that the proposed framework can approximate functional relationships between design variables and quantities of interest, even in cases where the latter take values in high-dimensional vector spaces or even infinite-dimensional function spaces. In the context of BO, we augmented the proposed probabilistic surrogates with re-parameterized Monte Carlo approximations of multiple-point (parallel) acquisition functions, as well as methodological extensions for accommodating black-box constraints and multi-fidelity information sources. We test the proposed framework against state-of-the-art methods for BO and demonstrate superior performance across several challenging tasks with high-dimensional outputs, including a constrained optimization task involving shape optimization of rotor blades in turbo-machinery.
3D Convolutional Selective Autoencoder For Instability Detection in Combustion Systems
Jan 06, 2021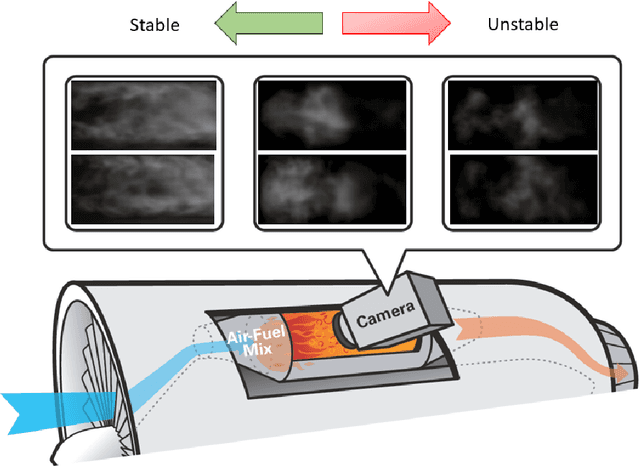
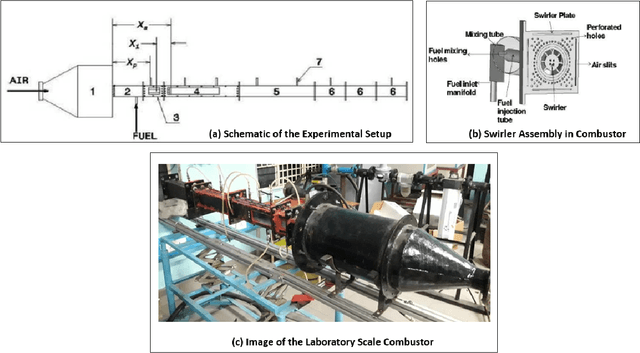
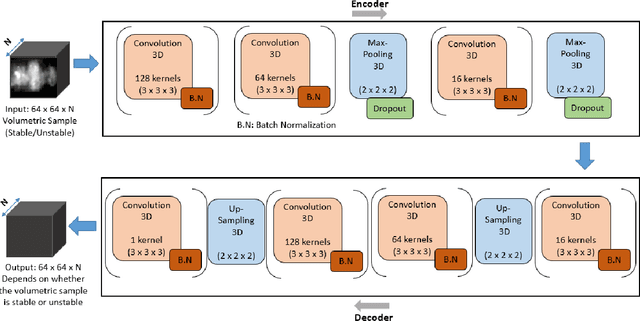
While analytical solutions of critical (phase) transitions in physical systems are abundant for simple nonlinear systems, such analysis remains intractable for real-life dynamical systems. A key example of such a physical system is thermoacoustic instability in combustion, where prediction or early detection of an onset of instability is a hard technical challenge, which needs to be addressed to build safer and more energy-efficient gas turbine engines powering aerospace and energy industries. The instabilities arising in combustion chambers of engines are mathematically too complex to model. To address this issue in a data-driven manner instead, we propose a novel deep learning architecture called 3D convolutional selective autoencoder (3D-CSAE) to detect the evolution of self-excited oscillations using spatiotemporal data, i.e., hi-speed videos taken from a swirl-stabilized combustor (laboratory surrogate of gas turbine engine combustor). 3D-CSAE consists of filters to learn, in a hierarchical fashion, the complex visual and dynamic features related to combustion instability. We train the 3D-CSAE on frames of videos obtained from a limited set of operating conditions. We select the 3D-CSAE hyper-parameters that are effective for characterizing hierarchical and multiscale instability structure evolution by utilizing the dynamic information available in the video. The proposed model clearly shows performance improvement in detecting the precursors of instability. The machine learning-driven results are verified with physics-based off-line measures. Advanced active control mechanisms can directly leverage the proposed online detection capability of 3D-CSAE to mitigate the adverse effects of combustion instabilities on the engine operating under various stringent requirements and conditions.
Early Detection of Combustion Instabilities using Deep Convolutional Selective Autoencoders on Hi-speed Flame Video
Mar 25, 2016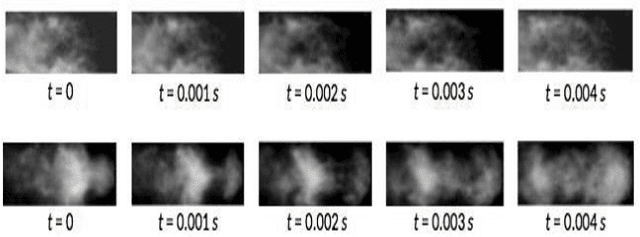
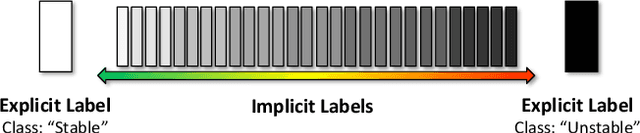
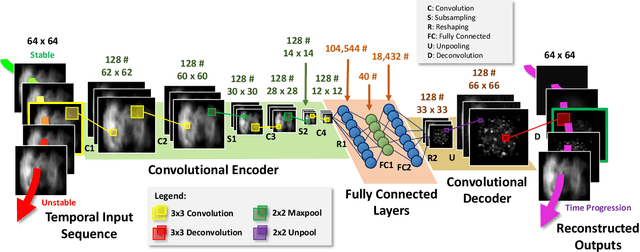
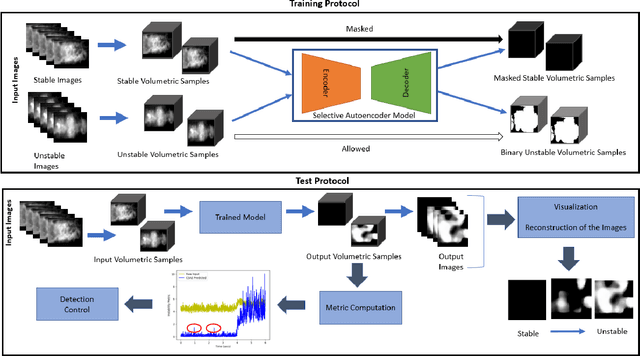
This paper proposes an end-to-end convolutional selective autoencoder approach for early detection of combustion instabilities using rapidly arriving flame image frames. The instabilities arising in combustion processes cause significant deterioration and safety issues in various human-engineered systems such as land and air based gas turbine engines. These properties are described as self-sustaining, large amplitude pressure oscillations and show varying spatial scales periodic coherent vortex structure shedding. However, such instability is extremely difficult to detect before a combustion process becomes completely unstable due to its sudden (bifurcation-type) nature. In this context, an autoencoder is trained to selectively mask stable flame and allow unstable flame image frames. In that process, the model learns to identify and extract rich descriptive and explanatory flame shape features. With such a training scheme, the selective autoencoder is shown to be able to detect subtle instability features as a combustion process makes transition from stable to unstable region. As a consequence, the deep learning tool-chain can perform as an early detection framework for combustion instabilities that will have a transformative impact on the safety and performance of modern engines.