 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"A Good Bot Always Knows Its Limitations": Assessing Autonomous System Decision-making Competencies through Factorized Machine Self-confidence
Jul 29, 2024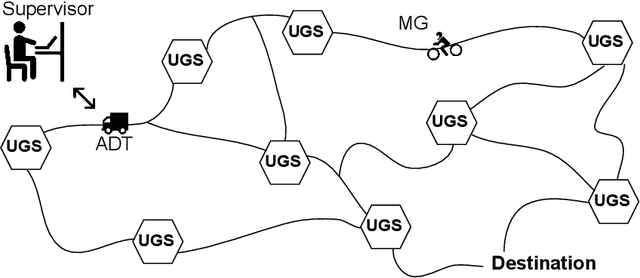

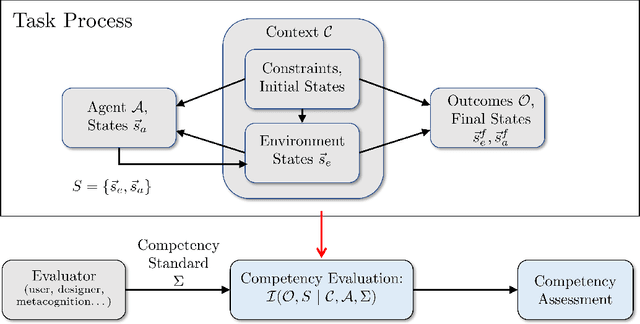
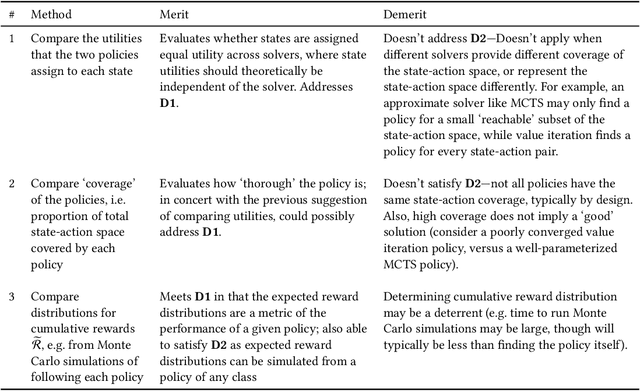
How can intelligent machines assess their competencies in completing tasks? This question has come into focus for autonomous systems that algorithmically reason and make decisions under uncertainty. It is argued here that machine self-confidence -- a form of meta-reasoning based on self-assessments of an agent's knowledge about the state of the world and itself, as well as its ability to reason about and execute tasks -- leads to many eminently computable and useful competency indicators for such agents. This paper presents a culmination of work on this concept in the form of a computational framework called Factorized Machine Self-confidence (FaMSeC), which provides an engineering-focused holistic description of factors driving an algorithmic decision-making process, including outcome assessment, solver quality, model quality, alignment quality, and past experience. In FaMSeC, self-confidence indicators are derived from hierarchical `problem-solving statistics' embedded within broad classes of probabilistic decision-making algorithms such as Markov decision processes. The problem-solving statistics are obtained by evaluating and grading probabilistic exceedance margins with respect to given competency standards, which are specified for each decision-making competency factor by the informee (e.g. a non-expert user or an expert system designer). This approach allows `algorithmic goodness of fit' evaluations to be easily incorporated into the design of many kinds of autonomous agents via human-interpretable competency self-assessment reports. Detailed descriptions and running application examples for a Markov decision process agent show how two FaMSeC factors (outcome assessment and solver quality) can be practically computed and reported for a range of possible tasking contexts through novel use of meta-utility functions, behavior simulations, and surrogate prediction models.
LLMs for Multi-Modal Knowledge Extraction and Analysis in Intelligence/Safety-Critical Applications
Dec 05, 2023Large Language Models have seen rapid progress in capability in recent years; this progress has been accelerating and their capabilities, measured by various benchmarks, are beginning to approach those of humans. There is a strong demand to use such models in a wide variety of applications but, due to unresolved vulnerabilities and limitations, great care needs to be used before applying them to intelligence and safety-critical applications. This paper reviews recent literature related to LLM assessment and vulnerabilities to synthesize the current research landscape and to help understand what advances are most critical to enable use of of these technologies in intelligence and safety-critical applications. The vulnerabilities are broken down into ten high-level categories and overlaid onto a high-level life cycle of an LLM. Some general categories of mitigations are reviewed.
Hybrid Repeat/Multi-point Sampling for Highly Volatile Objective Functions
Dec 13, 2016



A key drawback of the current generation of artificial decision-makers is that they do not adapt well to changes in unexpected situations. This paper addresses the situation in which an AI for aerial dog fighting, with tunable parameters that govern its behavior, will optimize behavior with respect to an objective function that must be evaluated and learned through simulations. Once this objective function has been modeled, the agent can then choose its desired behavior in different situations. Bayesian optimization with a Gaussian Process surrogate is used as the method for investigating the objective function. One key benefit is that during optimization the Gaussian Process learns a global estimate of the true objective function, with predicted outcomes and a statistical measure of confidence in areas that haven't been investigated yet. However, standard Bayesian optimization does not perform consistently or provide an accurate Gaussian Process surrogate function for highly volatile objective functions. We treat these problems by introducing a novel sampling technique called Hybrid Repeat/Multi-point Sampling. This technique gives the AI ability to learn optimum behaviors in a highly uncertain environment. More importantly, it not only improves the reliability of the optimization, but also creates a better model of the entire objective surface. With this improved model the agent is equipped to better adapt behaviors.