 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Design of Safe Continual RL Methods for Control of Nonlinear Systems
Feb 21, 2025



Reinforcement learning (RL) algorithms have been successfully applied to control tasks associated with unmanned aerial vehicles and robotics. In recent years, safe RL has been proposed to allow the safe execution of RL algorithms in industrial and mission-critical systems that operate in closed loops. However, if the system operating conditions change, such as when an unknown fault occurs in the system, typical safe RL algorithms are unable to adapt while retaining past knowledge. Continual reinforcement learning algorithms have been proposed to address this issue. However, the impact of continual adaptation on the system's safety is an understudied problem. In this paper, we study the intersection of safe and continual RL. First, we empirically demonstrate that a popular continual RL algorithm, online elastic weight consolidation, is unable to satisfy safety constraints in non-linear systems subject to varying operating conditions. Specifically, we study the MuJoCo HalfCheetah and Ant environments with velocity constraints and sudden joint loss non-stationarity. Then, we show that an agent trained using constrained policy optimization, a safe RL algorithm, experiences catastrophic forgetting in continual learning settings. With this in mind, we explore a simple reward-shaping method to ensure that elastic weight consolidation prioritizes remembering both safety and task performance for safety-constrained, non-linear, and non-stationary dynamical systems.
FT-AED: Benchmark Dataset for Early Freeway Traffic Anomalous Event Detection
Jun 24, 2024



Early and accurate detection of anomalous events on the freeway, such as accidents, can improve emergency response and clearance. However, existing delays and errors in event identification and reporting make it a difficult problem to solve. Current large-scale freeway traffic datasets are not designed for anomaly detection and ignore these challenges. In this paper, we introduce the first large-scale lane-level freeway traffic dataset for anomaly detection. Our dataset consists of a month of weekday radar detection sensor data collected in 4 lanes along an 18-mile stretch of Interstate 24 heading toward Nashville, TN, comprising over 3.7 million sensor measurements. We also collect official crash reports from the Nashville Traffic Management Center and manually label all other potential anomalies in the dataset. To show the potential for our dataset to be used in future machine learning and traffic research, we benchmark numerous deep learning anomaly detection models on our dataset. We find that unsupervised graph neural network autoencoders are a promising solution for this problem and that ignoring spatial relationships leads to decreased performance. We demonstrate that our methods can reduce reporting delays by over 10 minutes on average while detecting 75% of crashes. Our dataset and all preprocessing code needed to get started are publicly released at https://vu.edu/ft-aed/ to facilitate future research.
Large-scale End-of-Life Prediction of Hard Disks in Distributed Datacenters
Mar 20, 2023On a daily basis, data centers process huge volumes of data backed by the proliferation of inexpensive hard disks. Data stored in these disks serve a range of critical functional needs from financial, and healthcare to aerospace. As such, premature disk failure and consequent loss of data can be catastrophic. To mitigate the risk of failures, cloud storage providers perform condition-based monitoring and replace hard disks before they fail. By estimating the remaining useful life of hard disk drives, one can predict the time-to-failure of a particular device and replace it at the right time, ensuring maximum utilization whilst reducing operational costs. In this work, large-scale predictive analyses are performed using severely skewed health statistics data by incorporating customized feature engineering and a suite of sequence learners. Past work suggests using LSTMs as an excellent approach to predicting remaining useful life. To this end, we present an encoder-decoder LSTM model where the context gained from understanding health statistics sequences aid in predicting an output sequence of the number of days remaining before a disk potentially fails. The models developed in this work are trained and tested across an exhaustive set of all of the 10 years of S.M.A.R.T. health data in circulation from Backblaze and on a wide variety of disk instances. It closes the knowledge gap on what full-scale training achieves on thousands of devices and advances the state-of-the-art by providing tangible metrics for evaluation and generalization for practitioners looking to extend their workflow to all years of health data in circulation across disk manufacturers. The encoder-decoder LSTM posted an RMSE of 0.83 during training and 0.86 during testing over the exhaustive 10 year data while being able to generalize competitively over other drives from the Seagate family.
Aspirations and Practice of Model Documentation: Moving the Needle with Nudging and Traceability
Apr 13, 2022
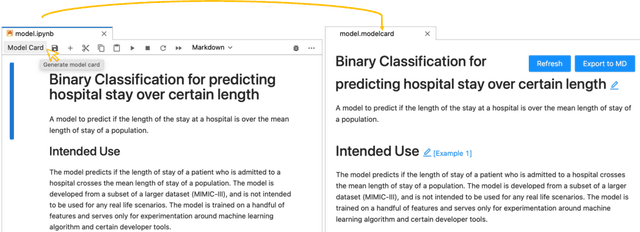


Machine learning models have been widely developed, released, and adopted in numerous applications. Meanwhile, the documentation practice for machine learning models often falls short of established practices for traditional software components, which impedes model accountability, inadvertently abets inappropriate or misuse of models, and may trigger negative social impact. Recently, model cards, a template for documenting machine learning models, have attracted notable attention, but their impact on the practice of model documentation is unclear. In this work, we examine publicly available model cards and other similar documentation. Our analysis reveals a substantial gap between the suggestions made in the original model card work and the content in actual documentation. Motivated by this observation and literature on fields such as software documentation, interaction design, and traceability, we further propose a set of design guidelines that aim to support the documentation practice for machine learning models including (1) the collocation of documentation environment with the coding environment, (2) nudging the consideration of model card sections during model development, and (3) documentation derived from and traced to the source. We designed a prototype tool named DocML following those guidelines to support model development in computational notebooks. A lab study reveals the benefit of our tool to shift the behavior of data scientists towards documentation quality and accountability.
Integration of a machine learning model into a decision support tool to predict absenteeism at work of prospective employees
Feb 02, 2022



Purpose - Inefficient hiring may result in lower productivity and higher training costs. Productivity losses caused by absenteeism at work cost U.S. employers billions of dollars each year. Also, employers typically spend a considerable amount of time managing employees who perform poorly. The purpose of this study is to develop a decision support tool to predict absenteeism among potential employees. Design/methodology/approach - We utilized a popular open-access dataset. In order to categorize absenteeism classes, the data have been preprocessed, and four methods of machine learning classification have been applied: Multinomial Logistic Regression (MLR), Support Vector Machines (SVM), Artificial Neural Networks (ANN), and Random Forests (RF). We selected the best model, based on several validation scores, and compared its performance against the existing model; we then integrated the best model into our proposed web-based for hiring managers. Findings - A web-based decision tool allows hiring managers to make more informed decisions before hiring a potential employee, thus reducing time, financial loss and reducing the probability of economic insolvency. Originality/value - In this paper, we propose a model that is trained based on attributes that can be collected during the hiring process. Furthermore, hiring managers may lack experience in machine learning or do not have the time to spend developing machine learning algorithms. Thus, we propose a web-based interactive tool that can be used without prior knowledge of machine learning algorithms.
Remaining Useful Life Estimation of Hard Disk Drives using Bidirectional LSTM Networks
Sep 11, 2021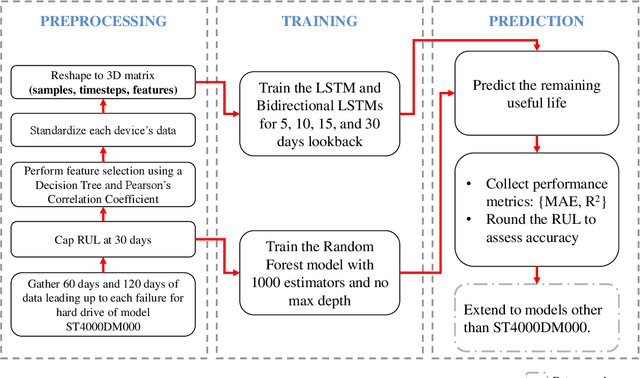
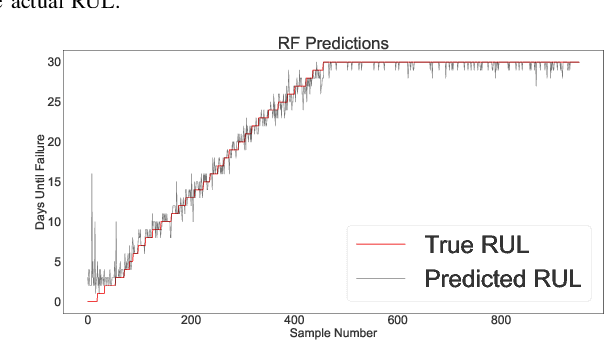
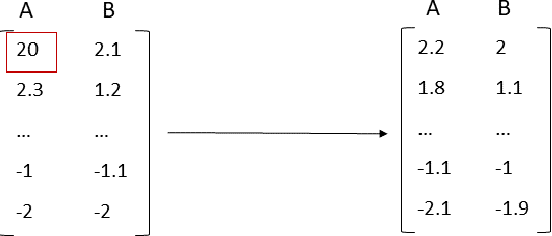
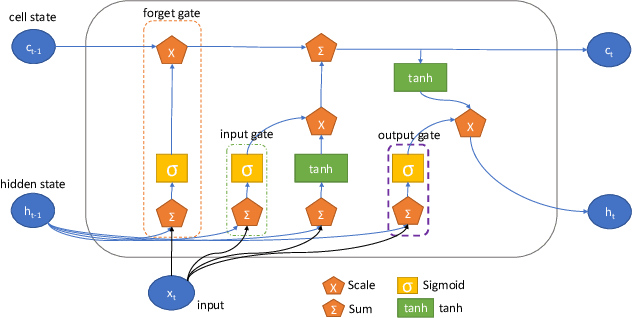
Physical and cloud storage services are well-served by functioning and reliable high-volume storage systems. Recent observations point to hard disk reliability as one of the most pressing reliability issues in data centers containing massive volumes of storage devices such as HDDs. In this regard, early detection of impending failure at the disk level aids in reducing system downtime and reduces operational loss making proactive health monitoring a priority for AIOps in such settings. In this work, we introduce methods of extracting meaningful attributes associated with operational failure and of pre-processing the highly imbalanced health statistics data for subsequent prediction tasks using data-driven approaches. We use a Bidirectional LSTM with a multi-day look back period to learn the temporal progression of health indicators and baseline them against vanilla LSTM and Random Forest models to come up with several key metrics that establish the usefulness of and superiority of our model under some tightly defined operational constraints. For example, using a 15 day look back period, our approach can predict the occurrence of disk failure with an accuracy of 96.4% considering test data 60 days before failure. This helps to alert operations maintenance well in-advance about potential mitigation needs. In addition, our model reports a mean absolute error of 0.12 for predicting failure up to 60 days in advance, placing it among the state-of-the-art in recent literature.