 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Comfort Zone: Emerging Solutions to Overcome Challenges in Integrating LLMs into Software Products
Oct 15, 2024
Large Language Models (LLMs) are increasingly embedded into software products across diverse industries, enhancing user experiences, but at the same time introducing numerous challenges for developers. Unique characteristics of LLMs force developers, who are accustomed to traditional software development and evaluation, out of their comfort zones as the LLM components shatter standard assumptions about software systems. This study explores the emerging solutions that software developers are adopting to navigate the encountered challenges. Leveraging a mixed-method research, including 26 interviews and a survey with 332 responses, the study identifies 19 emerging solutions regarding quality assurance that practitioners across several product teams at Microsoft are exploring. The findings provide valuable insights that can guide the development and evaluation of LLM-based products more broadly in the face of these challenges.
A Meta-Summary of Challenges in Building Products with ML Components -- Collecting Experiences from 4758+ Practitioners
Mar 31, 2023Incorporating machine learning (ML) components into software products raises new software-engineering challenges and exacerbates existing challenges. Many researchers have invested significant effort in understanding the challenges of industry practitioners working on building products with ML components, through interviews and surveys with practitioners. With the intention to aggregate and present their collective findings, we conduct a meta-summary study: We collect 50 relevant papers that together interacted with over 4758 practitioners using guidelines for systematic literature reviews. We then collected, grouped, and organized the over 500 mentions of challenges within those papers. We highlight the most commonly reported challenges and hope this meta-summary will be a useful resource for the research community to prioritize research and education in this field.
* 15 pages, 2 figures, 3 tables, published in CAIN 2023
Aspirations and Practice of Model Documentation: Moving the Needle with Nudging and Traceability
Apr 13, 2022
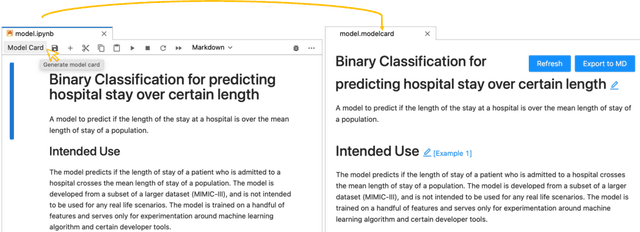


Machine learning models have been widely developed, released, and adopted in numerous applications. Meanwhile, the documentation practice for machine learning models often falls short of established practices for traditional software components, which impedes model accountability, inadvertently abets inappropriate or misuse of models, and may trigger negative social impact. Recently, model cards, a template for documenting machine learning models, have attracted notable attention, but their impact on the practice of model documentation is unclear. In this work, we examine publicly available model cards and other similar documentation. Our analysis reveals a substantial gap between the suggestions made in the original model card work and the content in actual documentation. Motivated by this observation and literature on fields such as software documentation, interaction design, and traceability, we further propose a set of design guidelines that aim to support the documentation practice for machine learning models including (1) the collocation of documentation environment with the coding environment, (2) nudging the consideration of model card sections during model development, and (3) documentation derived from and traced to the source. We designed a prototype tool named DocML following those guidelines to support model development in computational notebooks. A lab study reveals the benefit of our tool to shift the behavior of data scientists towards documentation quality and accountability.
More Engineering, No Silos: Rethinking Processes and Interfaces in Collaboration between Interdisciplinary Teams for Machine Learning Projects
Oct 19, 2021
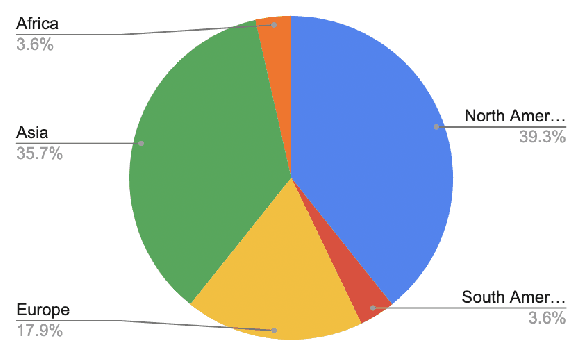
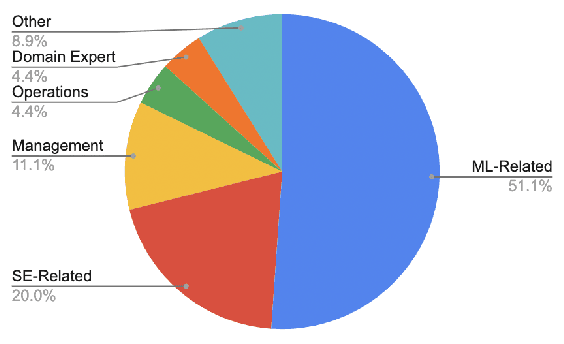
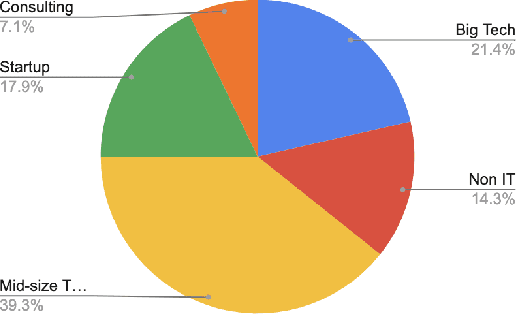
The introduction of machine learning (ML) components in software projects has created the need for software engineers to collaborate with data scientists and other specialists. While collaboration can always be challenging, ML introduces additional challenges with its exploratory model development process, additional skills and knowledge needed, difficulties testing ML systems, need for continuous evolution and monitoring, and non-traditional quality requirements such as fairness and explainability. Through interviews with 45 practitioners from 28 organizations, we identified key collaboration challenges that teams face when building and deploying ML systems into production. We report on common collaboration points in the development of production ML systems for requirements, data, and integration, as well as corresponding team patterns and challenges. We find that most of these challenges center around communication, documentation, engineering, and process and collect recommendations to address these challenges.
The Influences of Pre-birth Factors in Early Assessment of Child Mortality using Machine Learning Techniques
Nov 18, 2020
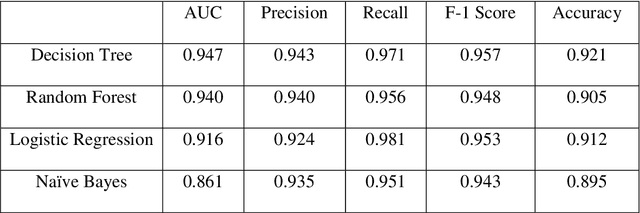
Analysis of child mortality is crucial as it pertains to the policy and programs of a country. The early assessment of patterns and trends in causes of child mortality help decision-makers assess needs, prioritize interventions, and monitor progress. Post-birth factors of the child, such as real-time clinical data, health data of the child, etc. are frequently used in child mortality studies. However, in the early assessment of child mortality, pre-birth factors would be more practical and beneficial than the post-birth factors. This study aims at incorporating pre-birth factors, such as birth history, maternal history, reproduction history, socioeconomic condition, etc. for classifying child mortality. To assess the relative importance of the features, Information Gain (IG) attribute evaluator is employed. For classifying child mortality, four machine learning algorithms are evaluated. Results show that the proposed approach achieved an AUC score of 0.947 in classifying child mortality which outperformed the clinical standards. In terms of accuracy, precision, recall, and f-1 score, the results are also notable and uniform. In developing countries like Bangladesh, the early assessment of child mortality using pre-birth factors would be effective and feasible as it avoids the uncertainty of the post-birth factors.