 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Comfort Zone: Emerging Solutions to Overcome Challenges in Integrating LLMs into Software Products
Oct 15, 2024
Large Language Models (LLMs) are increasingly embedded into software products across diverse industries, enhancing user experiences, but at the same time introducing numerous challenges for developers. Unique characteristics of LLMs force developers, who are accustomed to traditional software development and evaluation, out of their comfort zones as the LLM components shatter standard assumptions about software systems. This study explores the emerging solutions that software developers are adopting to navigate the encountered challenges. Leveraging a mixed-method research, including 26 interviews and a survey with 332 responses, the study identifies 19 emerging solutions regarding quality assurance that practitioners across several product teams at Microsoft are exploring. The findings provide valuable insights that can guide the development and evaluation of LLM-based products more broadly in the face of these challenges.
GEMS: Generative Expert Metric System through Iterative Prompt Priming
Oct 01, 2024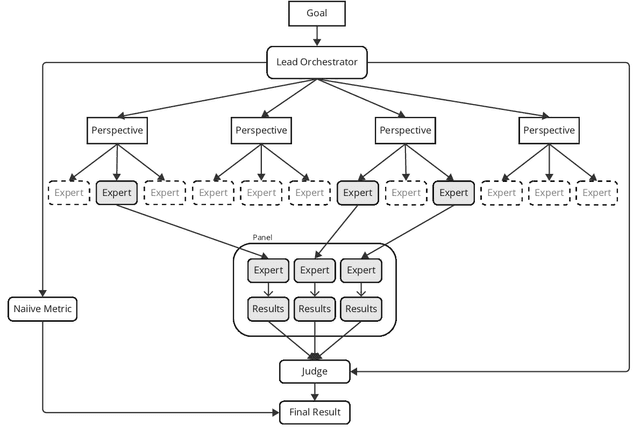

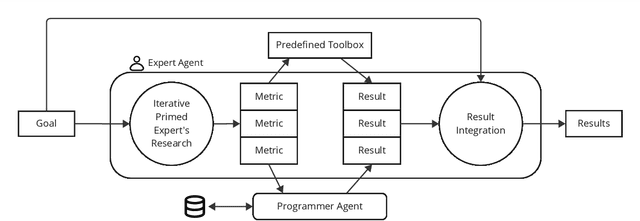
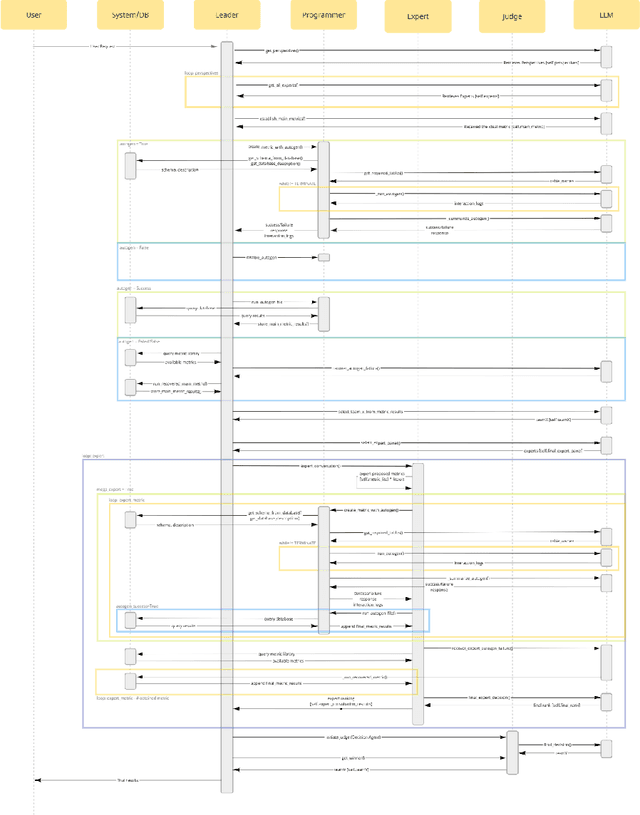
Across domains, metrics and measurements are fundamental to identifying challenges, informing decisions, and resolving conflicts. Despite the abundance of data available in this information age, not only can it be challenging for a single expert to work across multi-disciplinary data, but non-experts can also find it unintuitive to create effective measures or transform theories into context-specific metrics that are chosen appropriately. This technical report addresses this challenge by examining software communities within large software corporations, where different measures are used as proxies to locate counterparts within the organization to transfer tacit knowledge. We propose a prompt-engineering framework inspired by neural activities, demonstrating that generative models can extract and summarize theories and perform basic reasoning, thereby transforming concepts into context-aware metrics to support software communities given software repository data. While this research zoomed in on software communities, we believe the framework's applicability extends across various fields, showcasing expert-theory-inspired metrics that aid in triaging complex challenges.
Studying LLM Performance on Closed- and Open-source Data
Feb 23, 2024



Large Language models (LLMs) are finding wide use in software engineering practice. These models are extremely data-hungry, and are largely trained on open-source (OSS) code distributed with permissive licenses. In terms of actual use however, a great deal of software development still occurs in the for-profit/proprietary sphere, where the code under development is not, and never has been, in the public domain; thus, many developers, do their work, and use LLMs, in settings where the models may not be as familiar with the code under development. In such settings, do LLMs work as well as they do for OSS code? If not, what are the differences? When performance differs, what are the possible causes, and are there work-arounds? In this paper, we examine this issue using proprietary, closed-source software data from Microsoft, where most proprietary code is in C# and C++. We find that performance for C# changes little from OSS --> proprietary code, but does significantly reduce for C++; we find that this difference is attributable to differences in identifiers. We also find that some performance degradation, in some cases, can be ameliorated efficiently by in-context learning.
Can GPT-4 Replicate Empirical Software Engineering Research?
Oct 03, 2023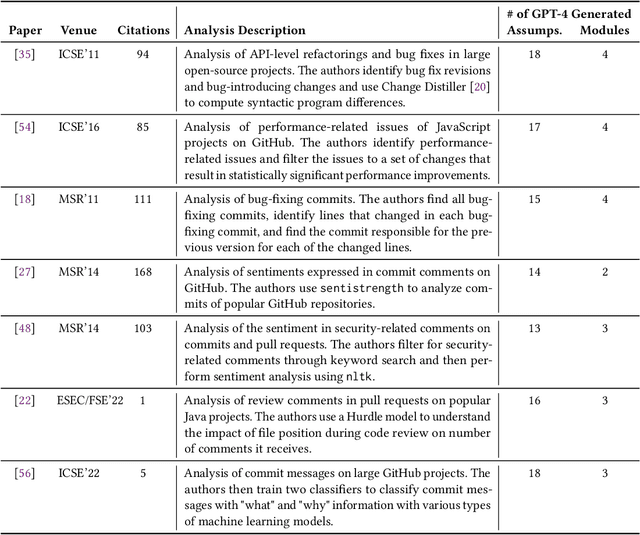
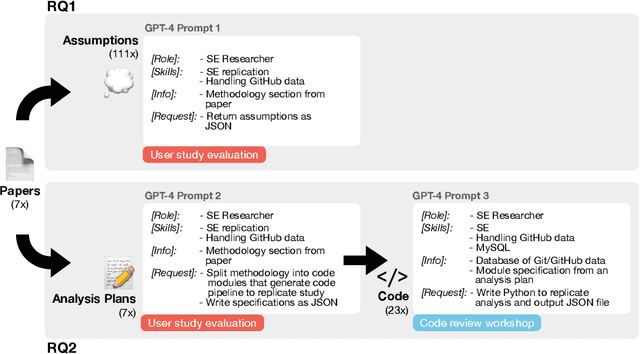

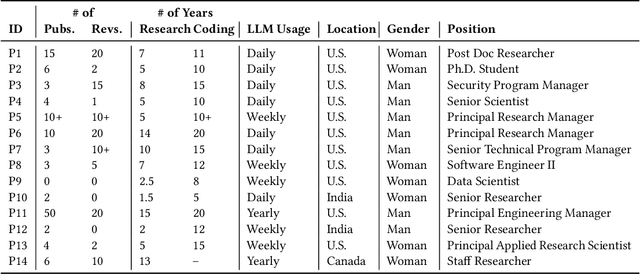
Empirical software engineering research on production systems has brought forth a better understanding of the software engineering process for practitioners and researchers alike. However, only a small subset of production systems is studied, limiting the impact of this research. While software engineering practitioners benefit from replicating research on their own data, this poses its own set of challenges, since performing replications requires a deep understanding of research methodologies and subtle nuances in software engineering data. Given that large language models (LLMs), such as GPT-4, show promise in tackling both software engineering- and science-related tasks, these models could help democratize empirical software engineering research. In this paper, we examine LLMs' abilities to perform replications of empirical software engineering research on new data. We specifically study their ability to surface assumptions made in empirical software engineering research methodologies, as well as their ability to plan and generate code for analysis pipelines on seven empirical software engineering papers. We perform a user study with 14 participants with software engineering research expertise, who evaluate GPT-4-generated assumptions and analysis plans (i.e., a list of module specifications) from the papers. We find that GPT-4 is able to surface correct assumptions, but struggle to generate ones that reflect common knowledge about software engineering data. In a manual analysis of the generated code, we find that the GPT-4-generated code contains the correct high-level logic, given a subset of the methodology. However, the code contains many small implementation-level errors, reflecting a lack of software engineering knowledge. Our findings have implications for leveraging LLMs for software engineering research as well as practitioner data scientists in software teams.
Using Large-scale Heterogeneous Graph Representation Learning for Code Review Recommendations
Feb 12, 2022



Code review is an integral part of any mature software development process, and identifying the best reviewer for a code change is a well accepted problem within the software engineering community. Selecting a reviewer who lacks expertise and understanding can slow development or result in more defects. To date, most reviewer recommendation systems rely primarily on historical file change and review information; those who changed or reviewed a file in the past are the best positioned to review in the future. We posit that while these approaches are able to identify and suggest qualified reviewers, they may be blind to reviewers who have the needed expertise and have simply never interacted with the changed files before. To address this, we present CORAL, a novel approach to reviewer recommendation that leverages a socio-technical graph built from the rich set of entities (developers, repositories, files, pull requests, work-items, etc.) and their relationships in modern source code management systems. We employ a graph convolutional neural network on this graph and train it on two and a half years of history on 332 repositories. We show that CORAL is able to model the manual history of reviewer selection remarkably well. Further, based on an extensive user study, we demonstrate that this approach identifies relevant and qualified reviewers who traditional reviewer recommenders miss, and that these developers desire to be included in the review process. Finally, we find that "classical" reviewer recommendation systems perform better on smaller (in terms of developers) software projects while CORAL excels on larger projects, suggesting that there is "no one model to rule them all."
MergeBERT: Program Merge Conflict Resolution via Neural Transformers
Sep 08, 2021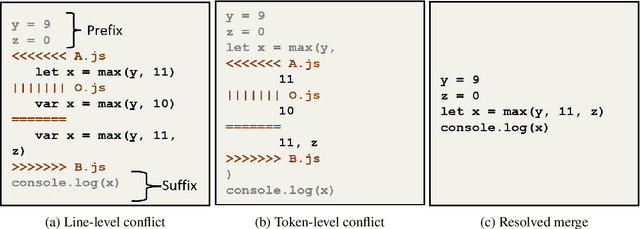
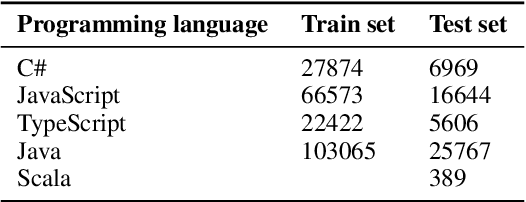

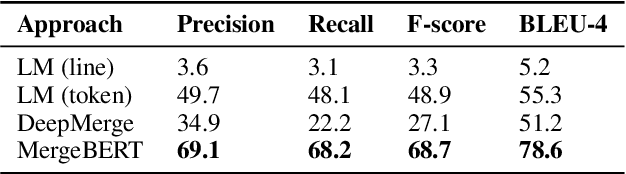
Collaborative software development is an integral part of the modern software development life cycle, essential to the success of large-scale software projects. When multiple developers make concurrent changes around the same lines of code, a merge conflict may occur. Such conflicts stall pull requests and continuous integration pipelines for hours to several days, seriously hurting developer productivity. In this paper, we introduce MergeBERT, a novel neural program merge framework based on the token-level three-way differencing and a transformer encoder model. Exploiting restricted nature of merge conflict resolutions, we reformulate the task of generating the resolution sequence as a classification task over a set of primitive merge patterns extracted from real-world merge commit data. Our model achieves 64--69% precision of merge resolution synthesis, yielding nearly a 2x performance improvement over existing structured and neural program merge tools. Finally, we demonstrate versatility of our model, which is able to perform program merge in a multilingual setting with Java, JavaScript, TypeScript, and C# programming languages, generalizing zero-shot to unseen languages.
ConE: A Concurrent Edit Detection Tool for Large ScaleSoftware Development
Jan 16, 2021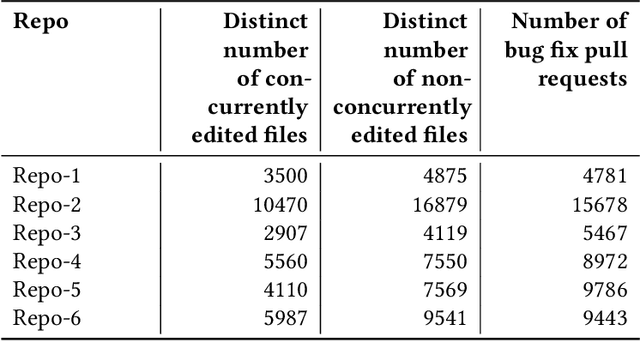
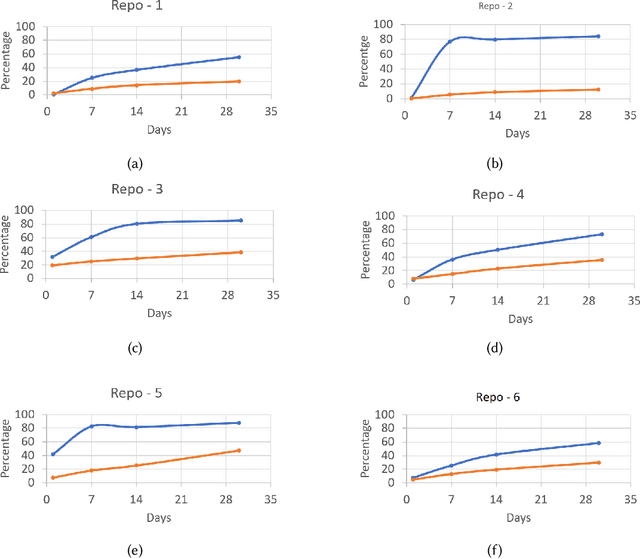

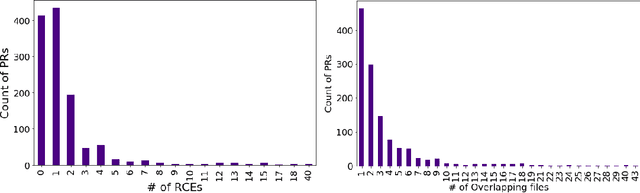
Developers from different teams or organizations, co-located or distributed, making changes to the same source code files or areas, through pull requests that are active in the same time period, is an essential part of developing complex software systems. With such a dynamically changing environment spanning several boundaries, geographic and organizational, there is little awareness about the changes that are flowing in through other active pull requests in the system leading to complex merge conflicts, hard-to-detect logical bugs or duplication of work and wasted developer productivity. In order to address this problem, we studied changes produced in eight very large repositories, in Microsoft to understand the extent of concurrent edits and their relation to subsequent bugs and bug fixes. Motivated by our findings, we developed a system called ConE (Concurrent Edit Detector) that proactively detects concurrent edits to help mitigate the problems caused by them. We present the results of ConE's deployment through early intervention techniques such as pull request notifications, by which ConE facilitates better communication among all the stakeholders participating in collaborative software development, helping avoid future problems.