 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tool for Generating Exceptional Behavior Tests With Large Language Models
May 28, 2025Exceptional behavior tests (EBTs) are crucial in software development for verifying that code correctly handles unwanted events and throws appropriate exceptions. However, prior research has shown that developers often prioritize testing "happy paths", e.g., paths without unwanted events over exceptional scenarios. We present exLong, a framework that automatically generates EBTs to address this gap. exLong leverages a large language model (LLM) fine-tuned from CodeLlama and incorporates reasoning about exception-throwing traces, conditional expressions that guard throw statements, and non-exceptional behavior tests that execute similar traces. Our demonstration video illustrates how exLong can effectively assist developers in creating comprehensive EBTs for their project (available at https://youtu.be/Jro8kMgplZk).
Few-shot fault diagnosis based on multi-scale graph convolution filtering for industry
May 30, 2024


Industrial equipment fault diagnosis often encounter challenges such as the scarcity of fault data, complex operating conditions, and varied types of failures. Signal analysis, data statistical learning, and conventional deep learning techniques face constraints under these conditions due to their substantial data requirements and the necessity for transfer learning to accommodate new failure modes. To effectively leverage information and extract the intrinsic characteristics of faults across different domains under limited sample conditions, this paper introduces a fault diagnosis approach employing Multi-Scale Graph Convolution Filtering (MSGCF). MSGCF enhances the traditional Graph Neural Network (GNN) framework by integrating both local and global information fusion modules within the graph convolution filter block. This advancement effectively mitigates the over-smoothing issue associated with excessive layering of graph convolutional layers while preserving a broad receptive field. It also reduces the risk of overfitting in few-shot diagnosis, thereby augmenting the model's representational capacity. Experiments on the University of Paderborn bearing dataset (PU) demonstrate that the MSGCF method proposed herein surpasses alternative approaches in accuracy, thereby offering valuable insights for industrial fault diagnosis in few-shot learning scenarios.
Multilingual Code Co-Evolution Using Large Language Models
Jul 27, 2023Many software projects implement APIs and algorithms in multiple programming languages. Maintaining such projects is tiresome, as developers have to ensure that any change (e.g., a bug fix or a new feature) is being propagated, timely and without errors, to implementations in other programming languages. In the world of ever-changing software, using rule-based translation tools (i.e., transpilers) or machine learning models for translating code from one language to another provides limited value. Translating each time the entire codebase from one language to another is not the way developers work. In this paper, we target a novel task: translating code changes from one programming language to another using large language models (LLMs). We design and implement the first LLM, dubbed Codeditor, to tackle this task. Codeditor explicitly models code changes as edit sequences and learns to correlate changes across programming languages. To evaluate Codeditor, we collect a corpus of 6,613 aligned code changes from 8 pairs of open-source software projects implementing similar functionalities in two programming languages (Java and C#). Results show that Codeditor outperforms the state-of-the-art approaches by a large margin on all commonly used automatic metrics. Our work also reveals that Codeditor is complementary to the existing generation-based models, and their combination ensures even greater performance.
CoditT5: Pretraining for Source Code and Natural Language Editing
Aug 10, 2022

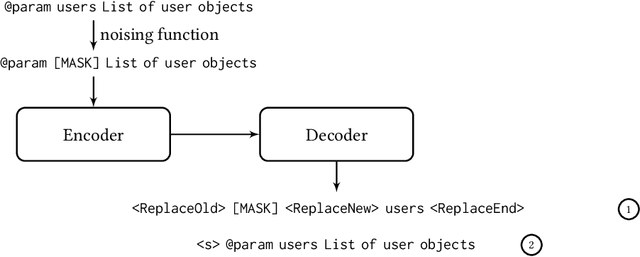
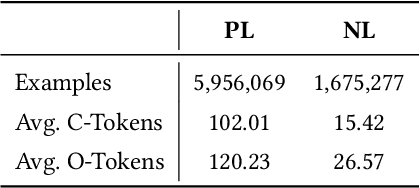
Pretrained language models have been shown to be effective in many software-related generation tasks; however, they are not well-suited for editing tasks as they are not designed to reason about edits. To address this, we propose a novel pretraining objective which explicitly models edits and use it to build CoditT5, a large language model for software-related editing tasks that is pretrained on large amounts of source code and natural language comments. We fine-tune it on various downstream editing tasks, including comment updating, bug fixing, and automated code review. By outperforming pure generation-based models, we demonstrate the generalizability of our approach and its suitability for editing tasks. We also show how a pure generation model and our edit-based model can complement one another through simple reranking strategies, with which we achieve state-of-the-art performance for the three downstream editing tasks.
Using Large-scale Heterogeneous Graph Representation Learning for Code Review Recommendations
Feb 12, 2022



Code review is an integral part of any mature software development process, and identifying the best reviewer for a code change is a well accepted problem within the software engineering community. Selecting a reviewer who lacks expertise and understanding can slow development or result in more defects. To date, most reviewer recommendation systems rely primarily on historical file change and review information; those who changed or reviewed a file in the past are the best positioned to review in the future. We posit that while these approaches are able to identify and suggest qualified reviewers, they may be blind to reviewers who have the needed expertise and have simply never interacted with the changed files before. To address this, we present CORAL, a novel approach to reviewer recommendation that leverages a socio-technical graph built from the rich set of entities (developers, repositories, files, pull requests, work-items, etc.) and their relationships in modern source code management systems. We employ a graph convolutional neural network on this graph and train it on two and a half years of history on 332 repositories. We show that CORAL is able to model the manual history of reviewer selection remarkably well. Further, based on an extensive user study, we demonstrate that this approach identifies relevant and qualified reviewers who traditional reviewer recommenders miss, and that these developers desire to be included in the review process. Finally, we find that "classical" reviewer recommendation systems perform better on smaller (in terms of developers) software projects while CORAL excels on larger projects, suggesting that there is "no one model to rule them all."
Evaluation Methodologies for Code Learning Tasks
Aug 22, 2021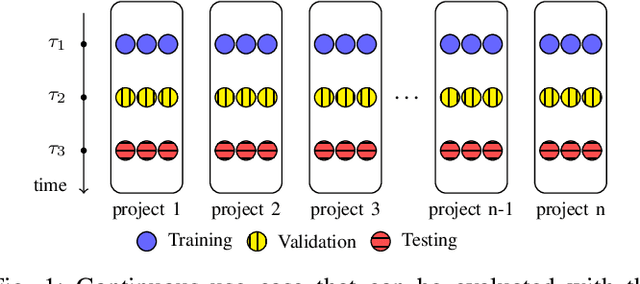
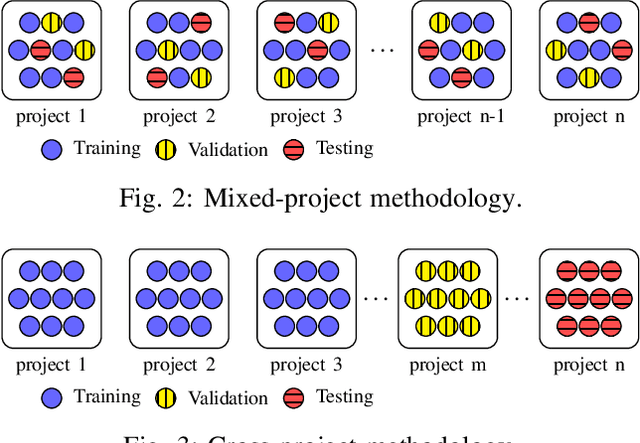
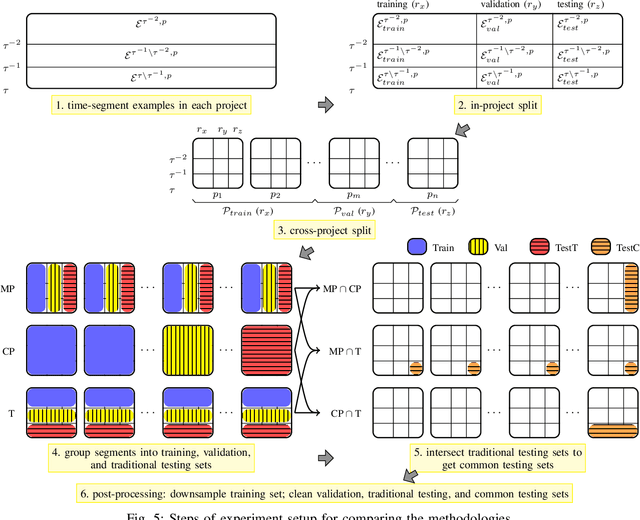
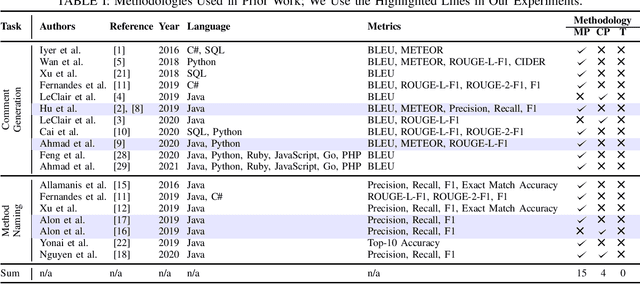
There has been a growing interest in developing machine learning (ML) models for code learning tasks, e.g., comment generation and method naming. Despite substantial increase in the effectiveness of ML models, the evaluation methodologies, i.e., the way people split datasets into training, validation, and testing sets, were not well designed. Specifically, no prior work on the aforementioned topics considered the timestamps of code and comments during evaluation (e.g., examples in the testing set might be from 2010 and examples from the training set might be from 2020). This may lead to evaluations that are inconsistent with the intended use cases of the ML models. In this paper, we formalize a novel time-segmented evaluation methodology, as well as the two methodologies commonly used in the literature: mixed-project and cross-project. We argue that time-segmented methodology is the most realistic. We also describe various use cases of ML models and provide a guideline for using methodologies to evaluate each use case. To assess the impact of methodologies, we collect a dataset of code-comment pairs with timestamps to train and evaluate several recent code learning ML models for the comment generation and method naming tasks. Our results show that different methodologies can lead to conflicting and inconsistent results. We invite the community to adopt the time-segmented evaluation methodology.
Deep Metric Learning Model for Imbalanced Fault Diagnosis
Jul 14, 2021
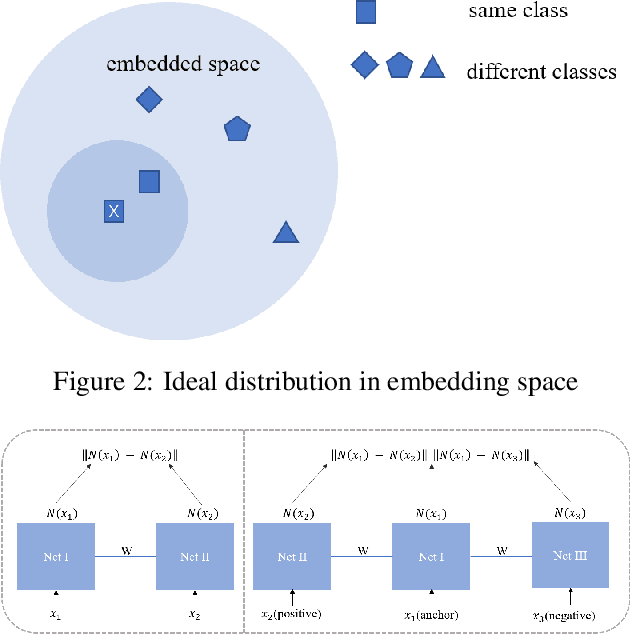

Intelligent diagnosis method based on data-driven and deep learning is an attractive and meaningful field in recent years. However, in practical application scenarios, the imbalance of time-series fault is an urgent problem to be solved. This paper proposes a novel deep metric learning model, where imbalanced fault data and a quadruplet data pair design manner are considered. Based on such data pair, a quadruplet loss function which takes into account the inter-class distance and the intra-class data distribution are proposed. This quadruplet loss pays special attention to imbalanced sample pair. The reasonable combination of quadruplet loss and softmax loss function can reduce the impact of imbalance. Experiment results on two open-source datasets show that the proposed method can effectively and robustly improve the performance of imbalanced fault diagnosis.
Learning to Generate Code Comments from Class Hierarchies
Apr 17, 2021


Descriptive code comments are essential for supporting code comprehension and maintenance. We propose the task of automatically generating comments for overriding methods. We formulate a novel framework which accommodates the unique contextual and linguistic reasoning that is required for performing this task. Our approach features: (1) incorporating context from the class hierarchy; (2) conditioning on learned, latent representations of specificity to generate comments that capture the more specialized behavior of the overriding method; and (3) unlikelihood training to discourage predictions which do not conform to invariant characteristics of the comment corresponding to the overridden method. Our experiments show that the proposed approach is able to generate comments for overriding methods of higher quality compared to prevailing comment generation techniques.