 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProdCodeBench: A Production-Derived Benchmark for Evaluating AI Coding Agents
Apr 02, 2026Benchmarks that reflect production workloads are better for evaluating AI coding agents in industrial settings, yet existing benchmarks differ from real usage in programming language distribution, prompt style and codebase structure. This paper presents a methodology for curating production-derived benchmarks, illustrated through ProdCodeBench - a benchmark built from real sessions with a production AI coding assistant. We detail our data collection and curation practices including LLM-based task classification, test relevance validation, and multi-run stability checks which address challenges in constructing reliable evaluation signals from monorepo environments. Each curated sample consists of a verbatim prompt, a committed code change and fail-to-pass tests spanning seven programming languages. Our systematic analysis of four foundation models yields solve rates from 53.2% to 72.2% revealing that models making greater use of work validation tools, such as executing tests and invoking static analysis, achieve higher solve rates. This suggests that iterative verification helps achieve effective agent behavior and that exposing codebase-specific verification mechanisms may significantly improve the performance of externally trained agents operating in unfamiliar environments. We share our methodology and lessons learned to enable other organizations to construct similar production-derived benchmarks.
Wink: Recovering from Misbehaviors in Coding Agents
Feb 19, 2026Autonomous coding agents, powered by large language models (LLMs), are increasingly being adopted in the software industry to automate complex engineering tasks. However, these agents are prone to a wide range of misbehaviors, such as deviating from the user's instructions, getting stuck in repetitive loops, or failing to use tools correctly. These failures disrupt the development workflow and often require resource-intensive manual intervention. In this paper, we present a system for automatically recovering from agentic misbehaviors at scale. We first introduce a taxonomy of misbehaviors grounded in an analysis of production traffic, identifying three primary categories: Specification Drift, Reasoning Problems, and Tool Call Failures, which we find occur in about 30% of all agent trajectories. To address these issues, we developed a lightweight, asynchronous self-intervention system named Wink. Wink observes agent trajectories and provides targeted course-correction guidance to nudge the agent back to a productive path. We evaluated our system on over 10,000 real world agent trajectories and found that it successfully resolves 90% of the misbehaviors that require a single intervention. Furthermore, a live A/B test in our production environment demonstrated that our system leads to a statistically significant reduction in Tool Call Failures, Tokens per Session and Engineer Interventions per Session. We present our experience designing and deploying this system, offering insights into the challenges of building resilient agentic systems at scale.
AI-Assisted Fixes to Code Review Comments at Scale
Jul 17, 2025Aim. There are 10s of thousands of code review comments each week at Meta. We developed Metamate for Code Review (MetaMateCR) that provides AI-assisted fixes for reviewer comments in production at scale. Method. We developed an internal benchmark of 64k <review comment, patch> data points to fine-tune Llama models. Once our models achieve reasonable offline results, we roll them into production. To ensure that our AI-assisted fixes do not negatively impact the time it takes to do code reviews, we conduct randomized controlled safety trials as well as full production experiments. Offline Results. As a baseline, we compare GPT-4o to our small and large Llama models. In offline results, our LargeLSFT model creates an exact match patch 68% of the time outperforming GPT-4o by 9 percentage points (pp). The internal models also use more modern Hack functions when compared to the PHP functions suggested by GPT-4o. Safety Trial. When we roll MetaMateCR into production in a safety trial that compares no AI patches with AI patch suggestions, we see a large regression with reviewers taking over 5% longer to conduct reviews. After investigation, we modify the UX to only show authors the AI patches, and see no regressions in the time for reviews. Production. When we roll LargeLSFT into production, we see an ActionableToApplied rate of 19.7%, which is a 9.2pp improvement over GPT-4o. Our results illustrate the importance of safety trials in ensuring that AI does not inadvertently slow down engineers, and a successful review comment to AI patch product running at scale.
Multi-line AI-assisted Code Authoring
Feb 06, 2024
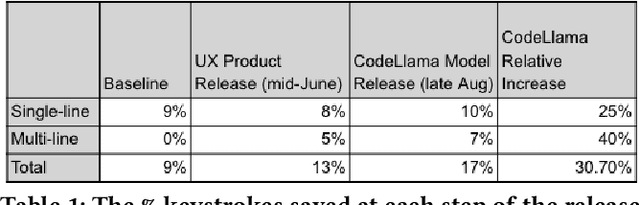

CodeCompose is an AI-assisted code authoring tool powered by large language models (LLMs) that provides inline suggestions to 10's of thousands of developers at Meta. In this paper, we present how we scaled the product from displaying single-line suggestions to multi-line suggestions. This evolution required us to overcome several unique challenges in improving the usability of these suggestions for developers. First, we discuss how multi-line suggestions can have a 'jarring' effect, as the LLM's suggestions constantly move around the developer's existing code, which would otherwise result in decreased productivity and satisfaction. Second, multi-line suggestions take significantly longer to generate; hence we present several innovative investments we made to reduce the perceived latency for users. These model-hosting optimizations sped up multi-line suggestion latency by 2.5x. Finally, we conduct experiments on 10's of thousands of engineers to understand how multi-line suggestions impact the user experience and contrast this with single-line suggestions. Our experiments reveal that (i) multi-line suggestions account for 42% of total characters accepted (despite only accounting for 16% for displayed suggestions) (ii) multi-line suggestions almost doubled the percentage of keystrokes saved for users from 9% to 17%. Multi-line CodeCompose has been rolled out to all engineers at Meta, and less than 1% of engineers have opted out of multi-line suggestions.
CodeCompose: A Large-Scale Industrial Deployment of AI-assisted Code Authoring
May 20, 2023



The rise of large language models (LLMs) has unlocked various applications of this technology in software development. In particular, generative LLMs have been shown to effectively power AI-based code authoring tools that can suggest entire statements or blocks of code during code authoring. In this paper we present CodeCompose, an AI-assisted code authoring tool developed and deployed at Meta internally. CodeCompose is based on the InCoder LLM that merges generative capabilities with bi-directionality. We have scaled up CodeCompose to serve tens of thousands of developers at Meta, across 10+ programming languages and several coding surfaces. We discuss unique challenges in terms of user experience and metrics that arise when deploying such tools in large-scale industrial settings. We present our experience in making design decisions about the model and system architecture for CodeCompose that addresses these challenges. Finally, we present metrics from our large-scale deployment of CodeCompose that shows its impact on Meta's internal code authoring experience over a 15-day time window, where 4.5 million suggestions were made by CodeCompose. Quantitative metrics reveal that (i) CodeCompose has an acceptance rate of 22% across several languages, and (ii) 8% of the code typed by users of CodeCompose is through accepting code suggestions from CodeCompose. Qualitative feedback indicates an overwhelming 91.5% positive reception for CodeCompose. In addition to assisting with code authoring, CodeCompose is also introducing other positive side effects such as encouraging developers to generate more in-code documentation, helping them with the discovery of new APIs, etc.
Using Large-scale Heterogeneous Graph Representation Learning for Code Review Recommendations
Feb 12, 2022



Code review is an integral part of any mature software development process, and identifying the best reviewer for a code change is a well accepted problem within the software engineering community. Selecting a reviewer who lacks expertise and understanding can slow development or result in more defects. To date, most reviewer recommendation systems rely primarily on historical file change and review information; those who changed or reviewed a file in the past are the best positioned to review in the future. We posit that while these approaches are able to identify and suggest qualified reviewers, they may be blind to reviewers who have the needed expertise and have simply never interacted with the changed files before. To address this, we present CORAL, a novel approach to reviewer recommendation that leverages a socio-technical graph built from the rich set of entities (developers, repositories, files, pull requests, work-items, etc.) and their relationships in modern source code management systems. We employ a graph convolutional neural network on this graph and train it on two and a half years of history on 332 repositories. We show that CORAL is able to model the manual history of reviewer selection remarkably well. Further, based on an extensive user study, we demonstrate that this approach identifies relevant and qualified reviewers who traditional reviewer recommenders miss, and that these developers desire to be included in the review process. Finally, we find that "classical" reviewer recommendation systems perform better on smaller (in terms of developers) software projects while CORAL excels on larger projects, suggesting that there is "no one model to rule them all."
ConE: A Concurrent Edit Detection Tool for Large ScaleSoftware Development
Jan 16, 2021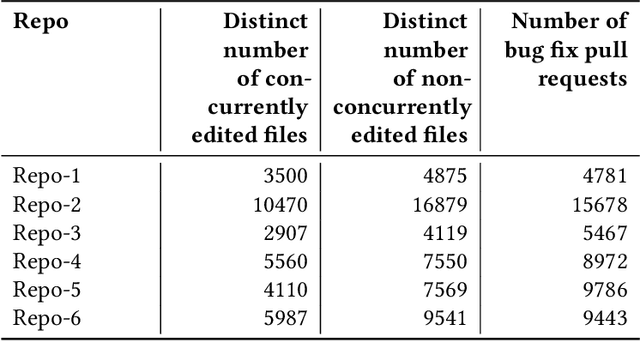
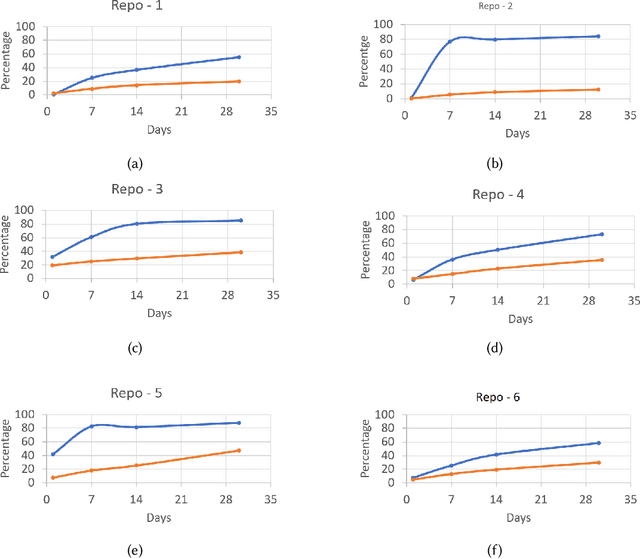

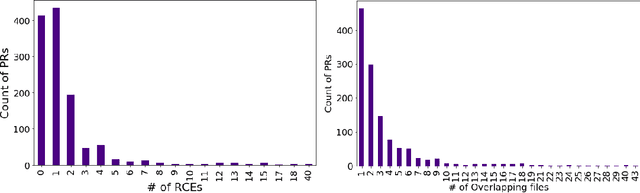
Developers from different teams or organizations, co-located or distributed, making changes to the same source code files or areas, through pull requests that are active in the same time period, is an essential part of developing complex software systems. With such a dynamically changing environment spanning several boundaries, geographic and organizational, there is little awareness about the changes that are flowing in through other active pull requests in the system leading to complex merge conflicts, hard-to-detect logical bugs or duplication of work and wasted developer productivity. In order to address this problem, we studied changes produced in eight very large repositories, in Microsoft to understand the extent of concurrent edits and their relation to subsequent bugs and bug fixes. Motivated by our findings, we developed a system called ConE (Concurrent Edit Detector) that proactively detects concurrent edits to help mitigate the problems caused by them. We present the results of ConE's deployment through early intervention techniques such as pull request notifications, by which ConE facilitates better communication among all the stakeholders participating in collaborative software development, helping avoid future problems.
Nudge: Accelerating Overdue Pull Requests Towards Completion
Nov 25, 2020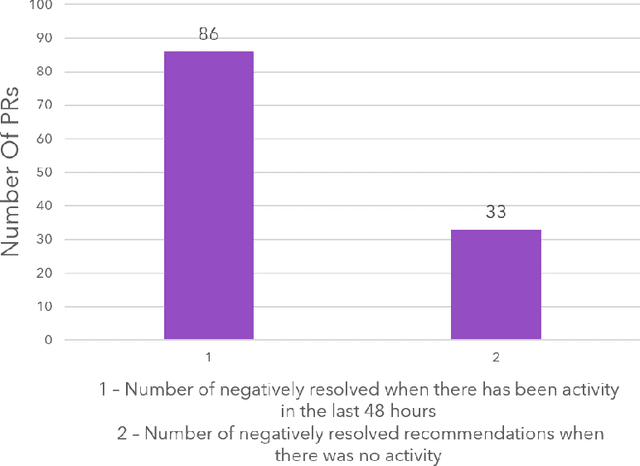
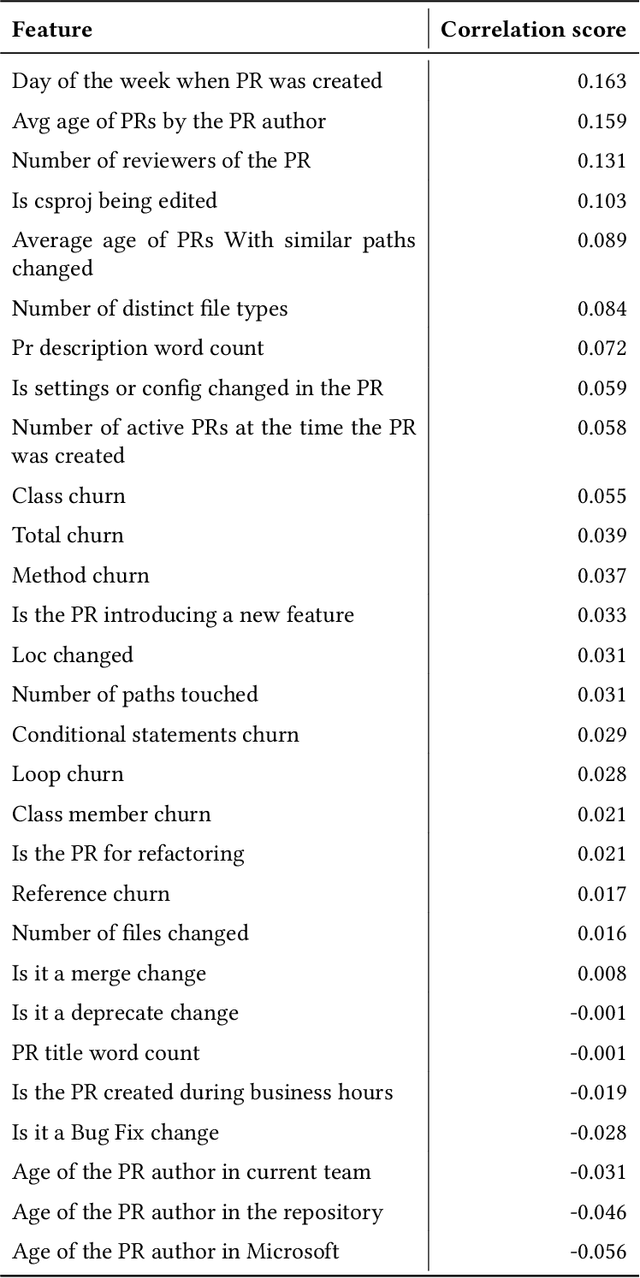
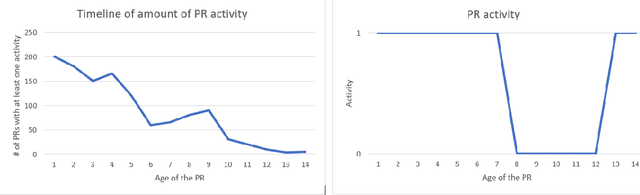
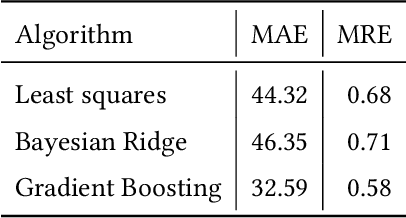
Pull requests are a key part of the collaborative software development and code review process today. However, pull requests can also slow down the software development process when the reviewer(s) or the author do not actively engage with the pull request. In this work, we design an end-to-end service, Nudge, for accelerating overdue pull requests towards completion by reminding the author or the reviewer(s) to engage with their overdue pull requests. First, we use models based on effort estimation and machine learning to predict the completion time for a given pull request. Second, we use activity detection to reduce false positives. Lastly, we use dependency determination to understand the blocker of the pull request and nudge the appropriate actor(author or reviewer(s)). We also do a correlation analysis to understand the statistical relationship between the pull request completion times and various pull request and developer related attributes. Nudge has been deployed on 147 repositories at Microsoft since 2019. We do a large scale evaluation based on the implicit and explicit feedback we received from sending the Nudge notifications on 8,500 pull requests. We observe significant reduction in completion time, by over 60%, for pull requests which were nudged thus increasing the efficiency of the code review process and accelerating the pull request progression.