 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large-scale Heterogeneous Graph Representation Learning for Code Review Recommendations
Feb 12, 2022



Code review is an integral part of any mature software development process, and identifying the best reviewer for a code change is a well accepted problem within the software engineering community. Selecting a reviewer who lacks expertise and understanding can slow development or result in more defects. To date, most reviewer recommendation systems rely primarily on historical file change and review information; those who changed or reviewed a file in the past are the best positioned to review in the future. We posit that while these approaches are able to identify and suggest qualified reviewers, they may be blind to reviewers who have the needed expertise and have simply never interacted with the changed files before. To address this, we present CORAL, a novel approach to reviewer recommendation that leverages a socio-technical graph built from the rich set of entities (developers, repositories, files, pull requests, work-items, etc.) and their relationships in modern source code management systems. We employ a graph convolutional neural network on this graph and train it on two and a half years of history on 332 repositories. We show that CORAL is able to model the manual history of reviewer selection remarkably well. Further, based on an extensive user study, we demonstrate that this approach identifies relevant and qualified reviewers who traditional reviewer recommenders miss, and that these developers desire to be included in the review process. Finally, we find that "classical" reviewer recommendation systems perform better on smaller (in terms of developers) software projects while CORAL excels on larger projects, suggesting that there is "no one model to rule them all."
HeteGCN: Heterogeneous Graph Convolutional Networks for Text Classification
Aug 19, 2020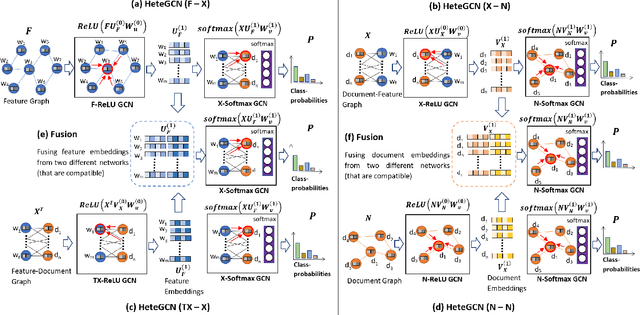
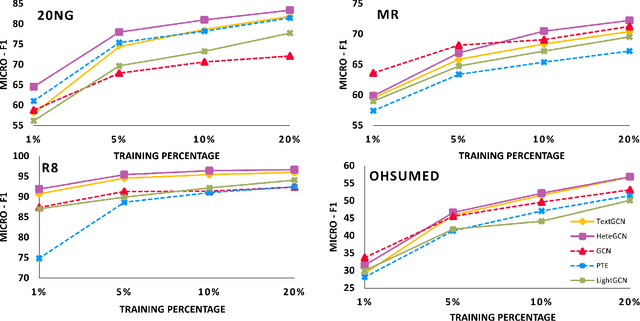
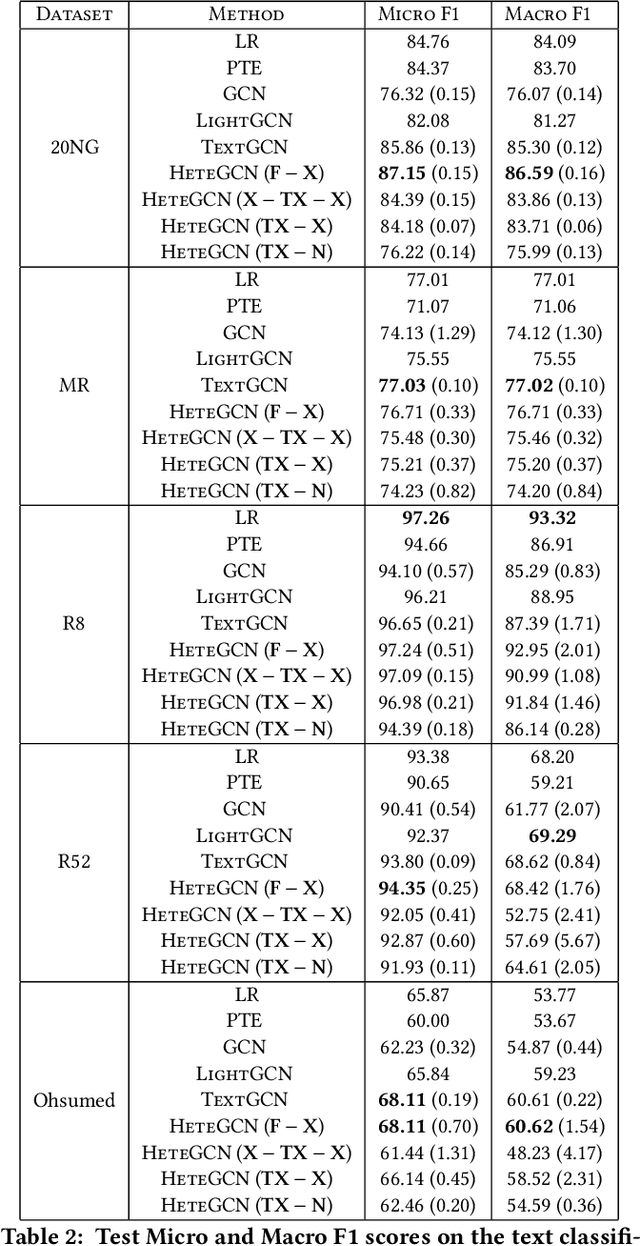
We consider the problem of learning efficient and inductive graph convolutional networks for text classification with a large number of examples and features. Existing state-of-the-art graph embedding based methods such as predictive text embedding (PTE) and TextGCN have shortcomings in terms of predictive performance, scalability and inductive capability. To address these limitations, we propose a heterogeneous graph convolutional network (HeteGCN) modeling approach that unites the best aspects of PTE and TextGCN together. The main idea is to learn feature embeddings and derive document embeddings using a HeteGCN architecture with different graphs used across layers. We simplify TextGCN by dissecting into several HeteGCN models which (a) helps to study the usefulness of individual models and (b) offers flexibility in fusing learned embeddings from different models. In effect, the number of model parameters is reduced significantly, enabling faster training and improving performance in small labeled training set scenario. Our detailed experimental studies demonstrate the efficacy of the proposed approach.