 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeteGCN: Heterogeneous Graph Convolutional Networks for Text Classification
Paper and Code
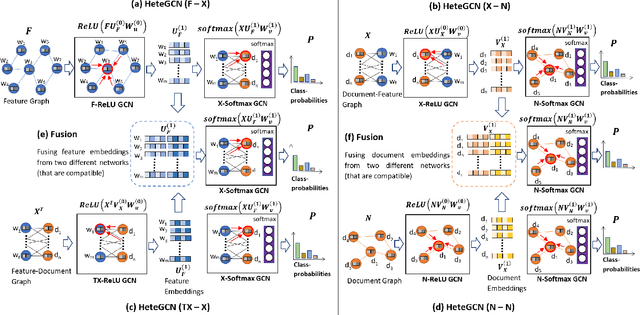
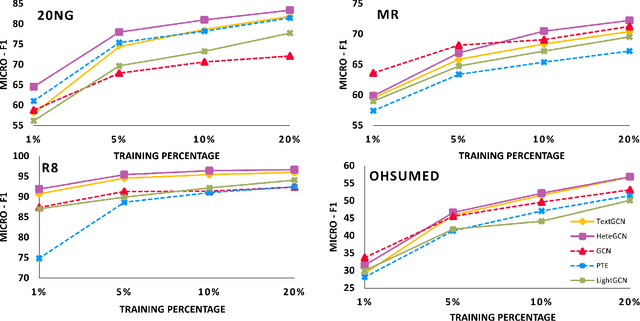
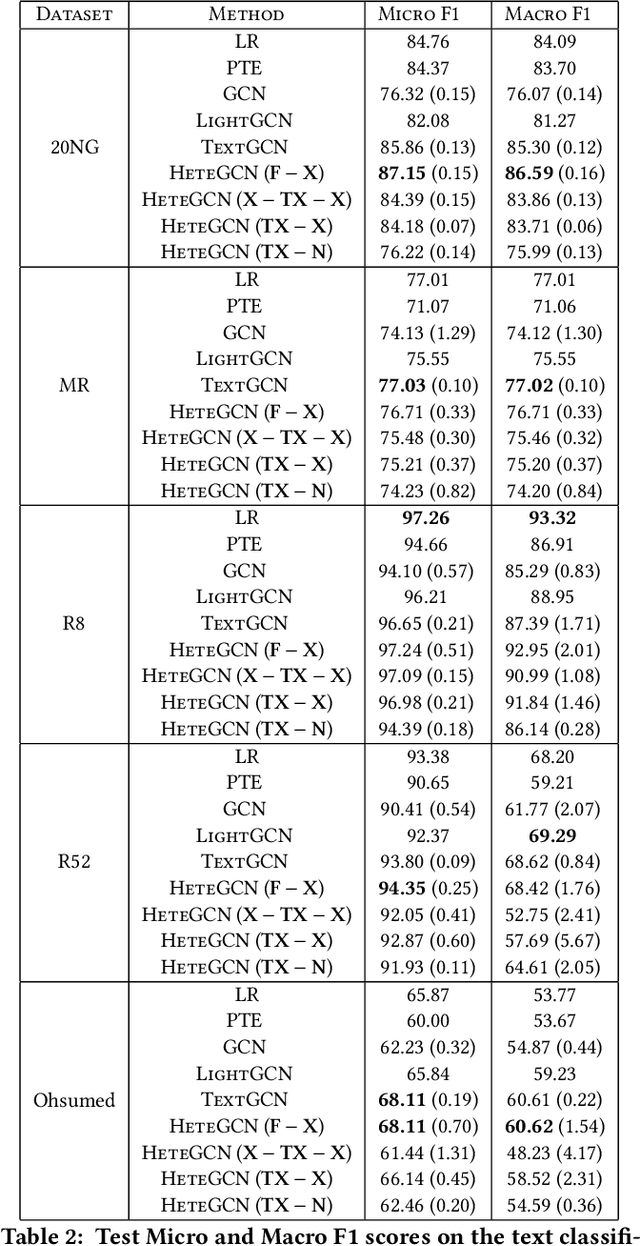
We consider the problem of learning efficient and inductive graph convolutional networks for text classification with a large number of examples and features. Existing state-of-the-art graph embedding based methods such as predictive text embedding (PTE) and TextGCN have shortcomings in terms of predictive performance, scalability and inductive capability. To address these limitations, we propose a heterogeneous graph convolutional network (HeteGCN) modeling approach that unites the best aspects of PTE and TextGCN together. The main idea is to learn feature embeddings and derive document embeddings using a HeteGCN architecture with different graphs used across layers. We simplify TextGCN by dissecting into several HeteGCN models which (a) helps to study the usefulness of individual models and (b) offers flexibility in fusing learned embeddings from different models. In effect, the number of model parameters is reduced significantly, enabling faster training and improving performance in small labeled training set scenario. Our detailed experimental studies demonstrate the efficacy of the proposed approach.