 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Interference (RI): Disentangling Models for Improved Model Merging
Mar 13, 2026Model merging has shown that multitask models can be created by directly combining the parameters of different models that are each specialized on tasks of interest. However, models trained independently on distinct tasks often exhibit interference that degrades the merged model's performance. To solve this problem, we formally define the notion of Cross-Task Interference as the drift in the representation of the merged model relative to its constituent models. Reducing cross-task interference is key to improving merging performance. To address this issue, we propose our method, Resolving Interference (RI), a light-weight adaptation framework which disentangles expert models to be functionally orthogonal to the space of other tasks, thereby reducing cross-task interference. RI does this whilst using only unlabeled auxiliary data as input (i.e., no task-data is needed), allowing it to be applied in data-scarce scenarios. RI consistently improves the performance of state-of-the-art merging methods by up to 3.8% and generalization to unseen domains by up to 2.3%. We also find RI to be robust to the source of auxiliary input while being significantly less sensitive to tuning of merging hyperparameters. Our codebase is available at: https://github.com/pramesh39/resolving_interference
Chow-Liu Ordering for Long-Context Reasoning in Chain-of-Agents
Mar 10, 2026Sequential multi-agent reasoning frameworks such as Chain-of-Agents (CoA) handle long-context queries by decomposing inputs into chunks and processing them sequentially using LLM-based worker agents that read from and update a bounded shared memory. From a probabilistic perspective, CoA aims to approximate the conditional distribution corresponding to a model capable of jointly reasoning over the entire long context. CoA achieves this through a latent-state factorization in which only bounded summaries of previously processed evidence are passed between agents. The resulting bounded-memory approximation introduces a lossy information bottleneck, making the final evidence state inherently dependent on the order in which chunks are processed. In this work, we study the problem of chunk ordering for long-context reasoning. We use the well-known Chow-Liu trees to learn a dependency structure that prioritizes strongly related chunks. Empirically, we show that a breadth-first traversal of the resulting tree yields chunk orderings that reduce information loss across agents and consistently outperform both default document-chunk ordering and semantic score-based ordering in answer relevance and exact-match accuracy across three long-context benchmarks.
COSMIR: Chain Orchestrated Structured Memory for Iterative Reasoning over Long Context
Oct 06, 2025


Reasoning over very long inputs remains difficult for large language models (LLMs). Common workarounds either shrink the input via retrieval (risking missed evidence), enlarge the context window (straining selectivity), or stage multiple agents to read in pieces. In staged pipelines (e.g., Chain of Agents, CoA), free-form summaries passed between agents can discard crucial details and amplify early mistakes. We introduce COSMIR (Chain Orchestrated Structured Memory for Iterative Reasoning), a chain-style framework that replaces ad hoc messages with a structured memory. A Planner agent first turns a user query into concrete, checkable sub-questions. worker agents process chunks via a fixed micro-cycle: Extract, Infer, Refine, writing all updates to the shared memory. A Manager agent then Synthesizes the final answer directly from the memory. This preserves step-wise read-then-reason benefits while changing both the communication medium (structured memory) and the worker procedure (fixed micro-cycle), yielding higher faithfulness, better long-range aggregation, and auditability. On long-context QA from the HELMET suite, COSMIR reduces propagation-stage information loss and improves accuracy over a CoA baseline.
STACKFEED: Structured Textual Actor-Critic Knowledge Base Editing with FeedBack
Oct 14, 2024Large Language Models (LLMs) often generate incorrect or outdated information, especially in low-resource settings or when dealing with private data. To address this, Retrieval-Augmented Generation (RAG) uses external knowledge bases (KBs), but these can also suffer from inaccuracies. We introduce STACKFEED, a novel Structured Textual Actor-Critic Knowledge base editing with FEEDback approach that iteratively refines the KB based on expert feedback using a multi-actor, centralized critic reinforcement learning framework. Each document is assigned to an actor, modeled as a ReACT agent, which performs structured edits based on document-specific targeted instructions from a centralized critic. Experimental results show that STACKFEED significantly improves KB quality and RAG system performance, enhancing accuracy by up to 8% over baselines.
Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository
Apr 22, 2024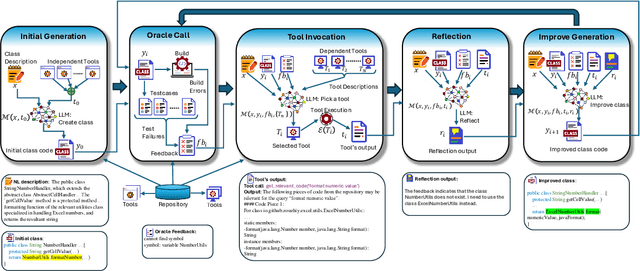
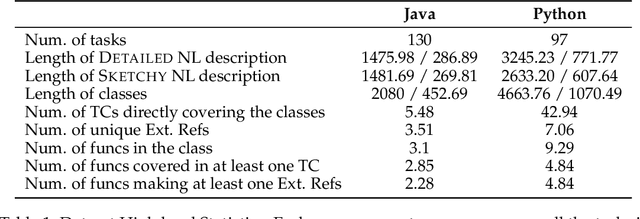
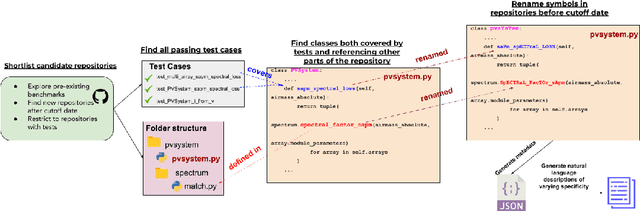

LLMs have demonstrated significant potential in code generation tasks, achieving promising results at the function or statement level in various benchmarks. However, the complexities associated with creating code artifacts like classes, particularly within the context of real-world software repositories, remain underexplored. Existing research often treats class-level generation as an isolated task, neglecting the intricate dependencies and interactions that characterize real-world software development environments. To address this gap, we introduce RepoClassBench, a benchmark designed to rigorously evaluate LLMs in generating complex, class-level code within real-world repositories. RepoClassBench includes natural language to class generation tasks across Java and Python, from a selection of public repositories. We ensure that each class in our dataset not only has cross-file dependencies within the repository but also includes corresponding test cases to verify its functionality. We find that current models struggle with the realistic challenges posed by our benchmark, primarily due to their limited exposure to relevant repository contexts. To address this shortcoming, we introduce Retrieve-Repotools-Reflect (RRR), a novel approach that equips LLMs with static analysis tools to iteratively navigate & reason about repository-level context in an agent-based framework. Our experiments demonstrate that RRR significantly outperforms existing baselines on RepoClassBench, showcasing its effectiveness across programming languages and in various settings. Our findings emphasize the need for benchmarks that incorporate repository-level dependencies to more accurately reflect the complexities of software development. Our work illustrates the benefits of leveraging specialized tools to enhance LLMs understanding of repository context. We plan to make our dataset and evaluation harness public.
FiGURe: Simple and Efficient Unsupervised Node Representations with Filter Augmentations
Oct 04, 2023



Unsupervised node representations learnt using contrastive learning-based methods have shown good performance on downstream tasks. However, these methods rely on augmentations that mimic low-pass filters, limiting their performance on tasks requiring different eigen-spectrum parts. This paper presents a simple filter-based augmentation method to capture different parts of the eigen-spectrum. We show significant improvements using these augmentations. Further, we show that sharing the same weights across these different filter augmentations is possible, reducing the computational load. In addition, previous works have shown that good performance on downstream tasks requires high dimensional representations. Working with high dimensions increases the computations, especially when multiple augmentations are involved. We mitigate this problem and recover good performance through lower dimensional embeddings using simple random Fourier feature projections. Our method, FiGURe achieves an average gain of up to 4.4%, compared to the state-of-the-art unsupervised models, across all datasets in consideration, both homophilic and heterophilic. Our code can be found at: https://github.com/microsoft/figure.
Landmarks and Regions: A Robust Approach to Data Extraction
Apr 11, 2022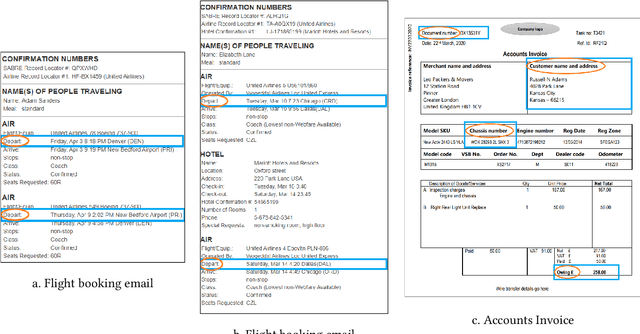
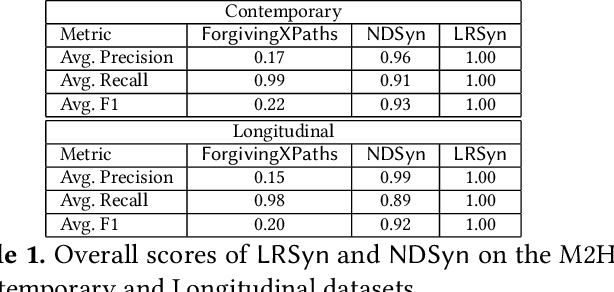
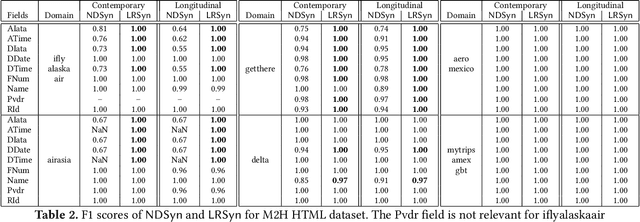
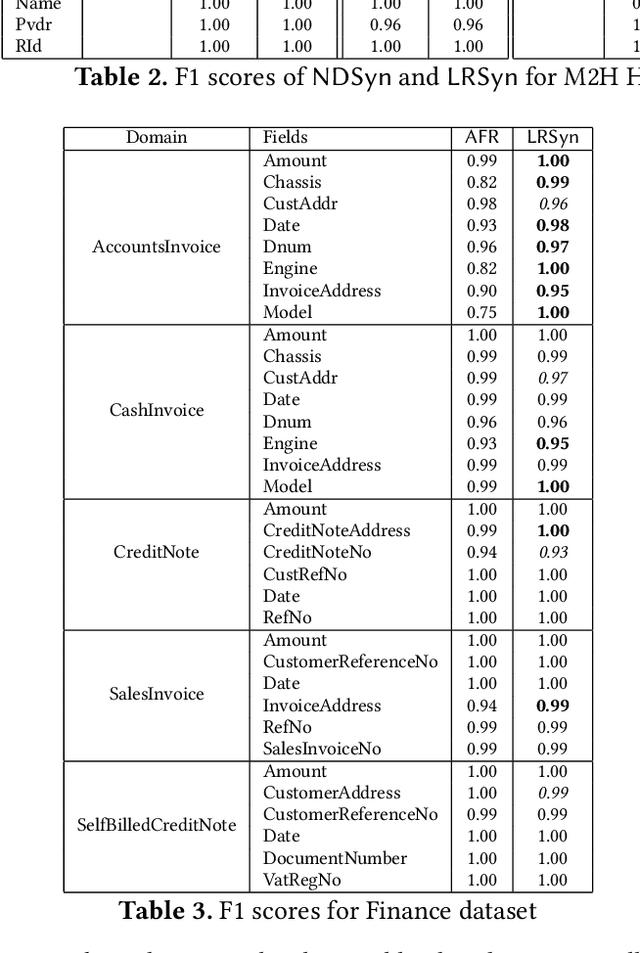
We propose a new approach to extracting data items or field values from semi-structured documents. Examples of such problems include extracting passenger name, departure time and departure airport from a travel itinerary, or extracting price of an item from a purchase receipt. Traditional approaches to data extraction use machine learning or program synthesis to process the whole document to extract the desired fields. Such approaches are not robust to format changes in the document, and the extraction process typically fails even if changes are made to parts of the document that are unrelated to the desired fields of interest. We propose a new approach to data extraction based on the concepts of landmarks and regions. Humans routinely use landmarks in manual processing of documents to zoom in and focus their attention on small regions of interest in the document. Inspired by this human intuition, we use the notion of landmarks in program synthesis to automatically synthesize extraction programs that first extract a small region of interest, and then automatically extract the desired value from the region in a subsequent step. We have implemented our landmark-based extraction approach in a tool LRSyn, and show extensive evaluation on documents in HTML as well as scanned images of invoices and receipts. Our results show that our approach is robust to various types of format changes that routinely happen in real-world settings.
A Piece-wise Polynomial Filtering Approach for Graph Neural Networks
Dec 07, 2021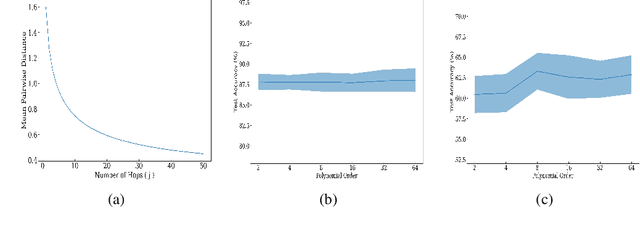
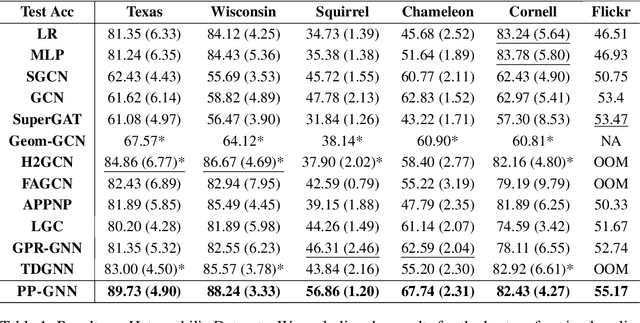
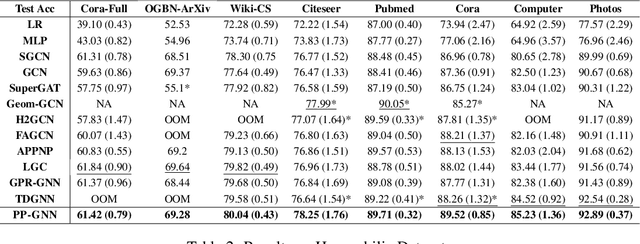
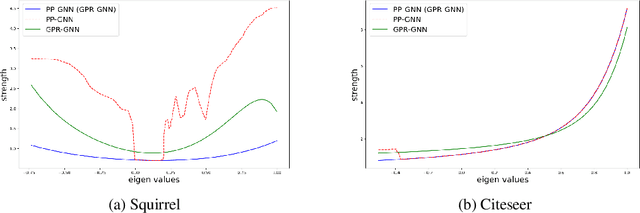
Graph Neural Networks (GNNs) exploit signals from node features and the input graph topology to improve node classification task performance. However, these models tend to perform poorly on heterophilic graphs, where connected nodes have different labels. Recently proposed GNNs work across graphs having varying levels of homophily. Among these, models relying on polynomial graph filters have shown promise. We observe that solutions to these polynomial graph filter models are also solutions to an overdetermined system of equations. It suggests that in some instances, the model needs to learn a reasonably high order polynomial. On investigation, we find the proposed models ineffective at learning such polynomials due to their designs. To mitigate this issue, we perform an eigendecomposition of the graph and propose to learn multiple adaptive polynomial filters acting on different subsets of the spectrum. We theoretically and empirically show that our proposed model learns a better filter, thereby improving classification accuracy. We study various aspects of our proposed model including, dependency on the number of eigencomponents utilized, latent polynomial filters learned, and performance of the individual polynomials on the node classification task. We further show that our model is scalable by evaluating over large graphs. Our model achieves performance gains of up to 5% over the state-of-the-art models and outperforms existing polynomial filter-based approaches in general.
Effective Eigendecomposition based Graph Adaptation for Heterophilic Networks
Jul 28, 2021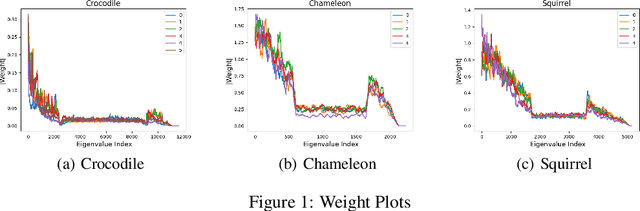
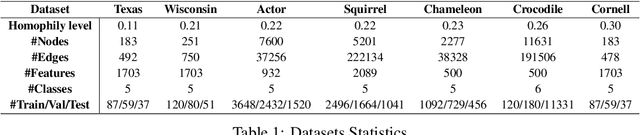
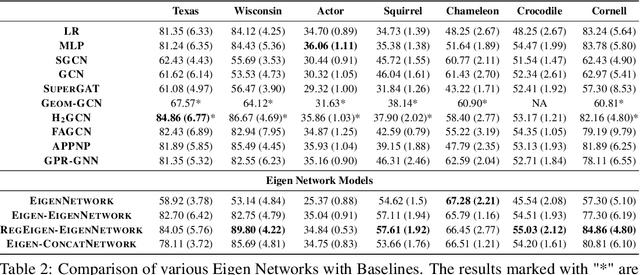
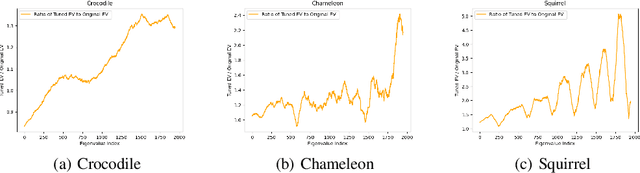
Graph Neural Networks (GNNs) exhibit excellent performance when graphs have strong homophily property, i.e. connected nodes have the same labels. However, they perform poorly on heterophilic graphs. Several approaches address the issue of heterophily by proposing models that adapt the graph by optimizing task-specific loss function using labelled data. These adaptations are made either via attention or by attenuating or enhancing various low-frequency/high-frequency signals, as needed for the task at hand. More recent approaches adapt the eigenvalues of the graph. One important interpretation of this adaptation is that these models select/weigh the eigenvectors of the graph. Based on this interpretation, we present an eigendecomposition based approach and propose EigenNetwork models that improve the performance of GNNs on heterophilic graphs. Performance improvement is achieved by learning flexible graph adaptation functions that modulate the eigenvalues of the graph. Regularization of these functions via parameter sharing helps to improve the performance even more. Our approach achieves up to 11% improvement in performance over the state-of-the-art methods on heterophilic graphs.
Simple Truncated SVD based Model for Node Classification on Heterophilic Graphs
Jun 24, 2021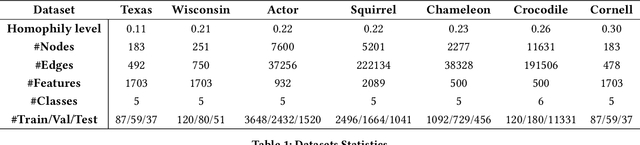
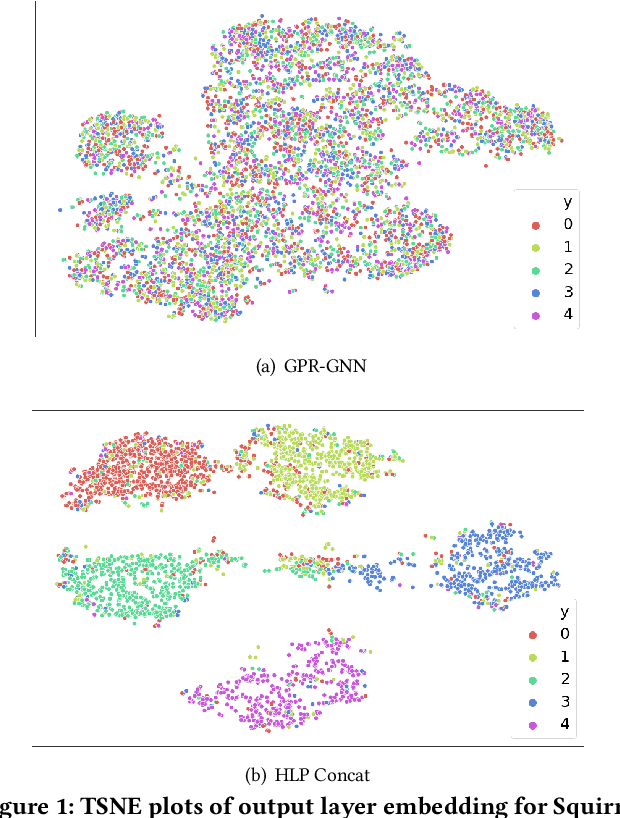
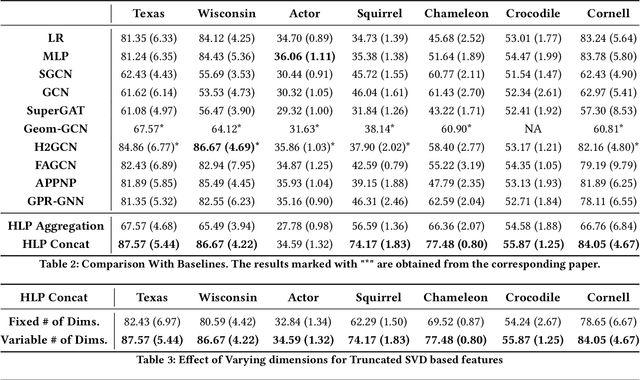
Graph Neural Networks (GNNs) have shown excellent performance on graphs that exhibit strong homophily with respect to the node labels i.e. connected nodes have same labels. However, they perform poorly on heterophilic graphs. Recent approaches have typically modified aggregation schemes, designed adaptive graph filters, etc. to address this limitation. In spite of this, the performance on heterophilic graphs can still be poor. We propose a simple alternative method that exploits Truncated Singular Value Decomposition (TSVD) of topological structure and node features. Our approach achieves up to ~30% improvement in performance over state-of-the-art methods on heterophilic graphs. This work is an early investigation into methods that differ from aggregation based approaches. Our experimental results suggest that it might be important to explore other alternatives to aggregation methods for heterophilic setting.