 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTACKFEED: Structured Textual Actor-Critic Knowledge Base Editing with FeedBack
Oct 14, 2024Large Language Models (LLMs) often generate incorrect or outdated information, especially in low-resource settings or when dealing with private data. To address this, Retrieval-Augmented Generation (RAG) uses external knowledge bases (KBs), but these can also suffer from inaccuracies. We introduce STACKFEED, a novel Structured Textual Actor-Critic Knowledge base editing with FEEDback approach that iteratively refines the KB based on expert feedback using a multi-actor, centralized critic reinforcement learning framework. Each document is assigned to an actor, modeled as a ReACT agent, which performs structured edits based on document-specific targeted instructions from a centralized critic. Experimental results show that STACKFEED significantly improves KB quality and RAG system performance, enhancing accuracy by up to 8% over baselines.
Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository
Apr 22, 2024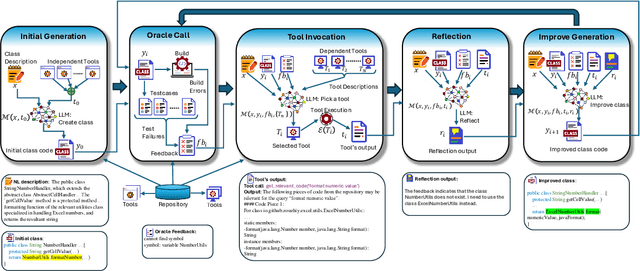
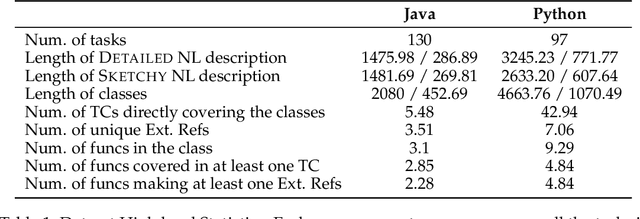

LLMs have demonstrated significant potential in code generation tasks, achieving promising results at the function or statement level in various benchmarks. However, the complexities associated with creating code artifacts like classes, particularly within the context of real-world software repositories, remain underexplored. Existing research often treats class-level generation as an isolated task, neglecting the intricate dependencies and interactions that characterize real-world software development environments. To address this gap, we introduce RepoClassBench, a benchmark designed to rigorously evaluate LLMs in generating complex, class-level code within real-world repositories. RepoClassBench includes natural language to class generation tasks across Java and Python, from a selection of public repositories. We ensure that each class in our dataset not only has cross-file dependencies within the repository but also includes corresponding test cases to verify its functionality. We find that current models struggle with the realistic challenges posed by our benchmark, primarily due to their limited exposure to relevant repository contexts. To address this shortcoming, we introduce Retrieve-Repotools-Reflect (RRR), a novel approach that equips LLMs with static analysis tools to iteratively navigate & reason about repository-level context in an agent-based framework. Our experiments demonstrate that RRR significantly outperforms existing baselines on RepoClassBench, showcasing its effectiveness across programming languages and in various settings. Our findings emphasize the need for benchmarks that incorporate repository-level dependencies to more accurately reflect the complexities of software development. Our work illustrates the benefits of leveraging specialized tools to enhance LLMs understanding of repository context. We plan to make our dataset and evaluation harness public.
Frustrated with Code Quality Issues? LLMs can Help!
Sep 22, 2023As software projects progress, quality of code assumes paramount importance as it affects reliability, maintainability and security of software. For this reason, static analysis tools are used in developer workflows to flag code quality issues. However, developers need to spend extra efforts to revise their code to improve code quality based on the tool findings. In this work, we investigate the use of (instruction-following) large language models (LLMs) to assist developers in revising code to resolve code quality issues. We present a tool, CORE (short for COde REvisions), architected using a pair of LLMs organized as a duo comprised of a proposer and a ranker. Providers of static analysis tools recommend ways to mitigate the tool warnings and developers follow them to revise their code. The \emph{proposer LLM} of CORE takes the same set of recommendations and applies them to generate candidate code revisions. The candidates which pass the static quality checks are retained. However, the LLM may introduce subtle, unintended functionality changes which may go un-detected by the static analysis. The \emph{ranker LLM} evaluates the changes made by the proposer using a rubric that closely follows the acceptance criteria that a developer would enforce. CORE uses the scores assigned by the ranker LLM to rank the candidate revisions before presenting them to the developer. CORE could revise 59.2% Python files (across 52 quality checks) so that they pass scrutiny by both a tool and a human reviewer. The ranker LLM is able to reduce false positives by 25.8% in these cases. CORE produced revisions that passed the static analysis tool in 76.8% Java files (across 10 quality checks) comparable to 78.3% of a specialized program repair tool, with significantly much less engineering efforts.
Landmarks and Regions: A Robust Approach to Data Extraction
Apr 11, 2022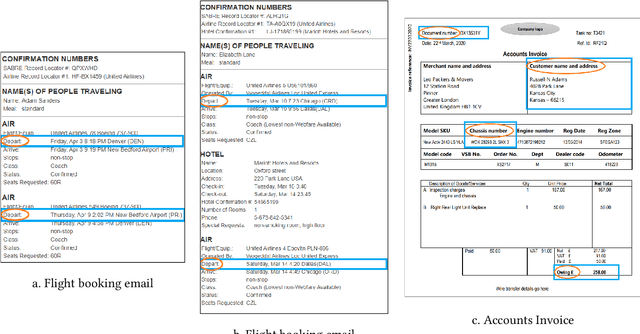
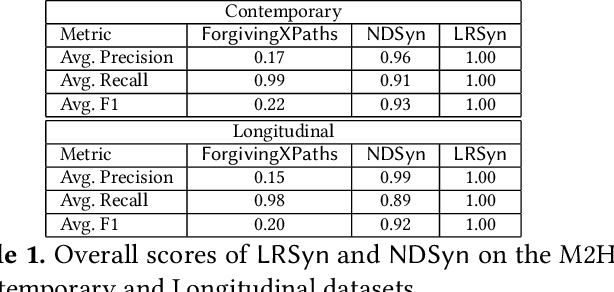
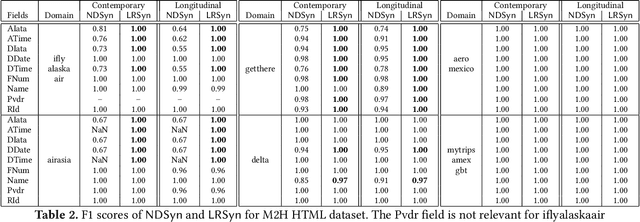
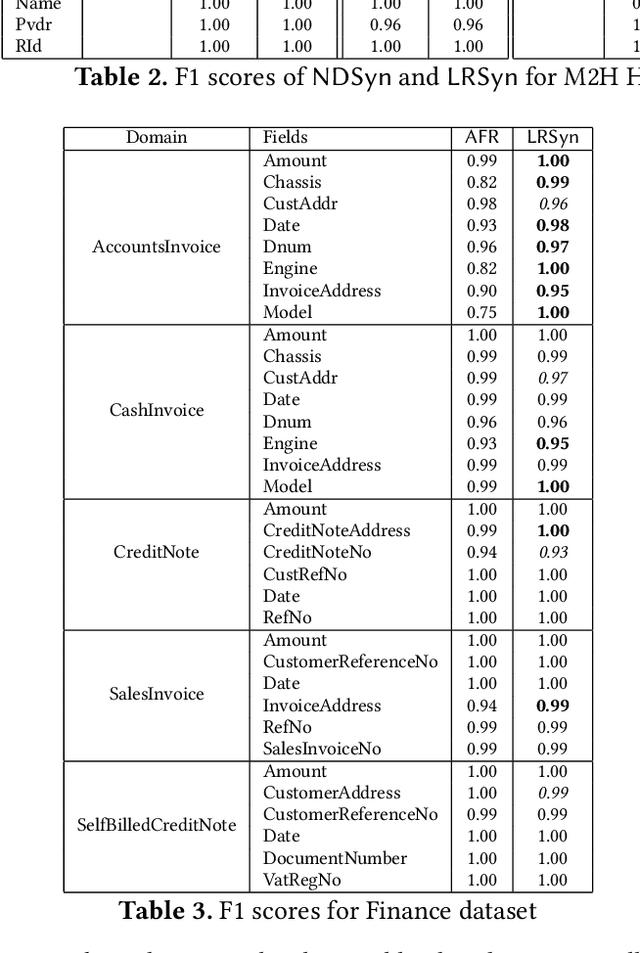
We propose a new approach to extracting data items or field values from semi-structured documents. Examples of such problems include extracting passenger name, departure time and departure airport from a travel itinerary, or extracting price of an item from a purchase receipt. Traditional approaches to data extraction use machine learning or program synthesis to process the whole document to extract the desired fields. Such approaches are not robust to format changes in the document, and the extraction process typically fails even if changes are made to parts of the document that are unrelated to the desired fields of interest. We propose a new approach to data extraction based on the concepts of landmarks and regions. Humans routinely use landmarks in manual processing of documents to zoom in and focus their attention on small regions of interest in the document. Inspired by this human intuition, we use the notion of landmarks in program synthesis to automatically synthesize extraction programs that first extract a small region of interest, and then automatically extract the desired value from the region in a subsequent step. We have implemented our landmark-based extraction approach in a tool LRSyn, and show extensive evaluation on documents in HTML as well as scanned images of invoices and receipts. Our results show that our approach is robust to various types of format changes that routinely happen in real-world settings.