 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nash Equilibrium Framework For Training-Free Multimodal Step Verification
May 19, 2026Multimodal large language models often generate reasoning chains containing subtle errors that lead to incorrect answers. Current verification approaches have notable limitations. Learned critics need extensive labeled data and show inconsistent performance across different tasks. Meanwhile, existing training-free methods simply average scores from different sources, missing a key insight: when these scores disagree, that disagreement itself carries important information about whether a reasoning step is truly valid or not. We propose a training-free verification approach that treats step-wise verification as a coordination problem among specialized judges. We formalize these judges' interaction as a Nash equilibrium game where agreement signals valid steps while disagreement reveals instability. Our method computes equilibrium scores through a closed-form solution, enabling both disagreement-aware filtering and stability-conscious ranking of reasoning steps. Evaluated across six benchmarks, our approach achieves consistent improvements of 2.4% to 5.2% over baseline models and shows competitive performance against learned critics, demonstrating that cross-modal agreement (not just average confidence) provides robust verification signals without task-specific adaptation.
interwhen: A Generalizable Framework for Verifiable Reasoning with Test-time Monitors
Feb 05, 2026We present a test-time verification framework, interwhen, that ensures that the output of a reasoning model is valid wrt. a given set of verifiers. Verified reasoning is an important goal in high-stakes scenarios such as deploying agents in the physical world or in domains such as law and finance. However, current techniques either rely on the generate-test paradigm that verifies only after the final answer is produced, or verify partial output through a step-extraction paradigm where the task execution is externally broken down into structured steps. The former is inefficient while the latter artificially restricts a model's problem solving strategies. Instead, we propose to verify a model's reasoning trace as-is, taking full advantage of a model's reasoning capabilities while verifying and steering the model's output only when needed. The key idea is meta-prompting, identifying the verifiable properties that any partial solution should satisfy and then prompting the model to follow a custom format in its trace such that partial outputs can be easily parsed and checked. We consider both self-verification and external verification and find that interwhen provides a useful abstraction to provide feedback and steer reasoning models in each case. Using self-verification, interwhen obtains state-of-the-art results on early stopping reasoning models, without any loss in accuracy. Using external verifiers, interwhen obtains 10 p.p. improvement in accuracy over test-time scaling methods, while ensuring 100% soundness and being 4x more efficient. The code for interwhen is available at https://github.com/microsoft/interwhen
Characterizing Deep Research: A Benchmark and Formal Definition
Aug 06, 2025Information tasks such as writing surveys or analytical reports require complex search and reasoning, and have recently been grouped under the umbrella of \textit{deep research} -- a term also adopted by recent models targeting these capabilities. Despite growing interest, the scope of the deep research task remains underdefined and its distinction from other reasoning-intensive problems is poorly understood. In this paper, we propose a formal characterization of the deep research (DR) task and introduce a benchmark to evaluate the performance of DR systems. We argue that the core defining feature of deep research is not the production of lengthy report-style outputs, but rather the high fan-out over concepts required during the search process, i.e., broad and reasoning-intensive exploration. To enable objective evaluation, we define DR using an intermediate output representation that encodes key claims uncovered during search-separating the reasoning challenge from surface-level report generation. Based on this formulation, we propose a diverse, challenging benchmark LiveDRBench with 100 challenging tasks over scientific topics (e.g., datasets, materials discovery, prior art search) and public interest events (e.g., flight incidents, movie awards). Across state-of-the-art DR systems, F1 score ranges between 0.02 and 0.72 for any sub-category. OpenAI's model performs the best with an overall F1 score of 0.55. Analysis of reasoning traces reveals the distribution over the number of referenced sources, branching, and backtracking events executed by current DR systems, motivating future directions for improving their search mechanisms and grounding capabilities. The benchmark is available at https://github.com/microsoft/LiveDRBench.
FrugalRAG: Learning to retrieve and reason for multi-hop QA
Jul 10, 2025We consider the problem of answering complex questions, given access to a large unstructured document corpus. The de facto approach to solving the problem is to leverage language models that (iteratively) retrieve and reason through the retrieved documents, until the model has sufficient information to generate an answer. Attempts at improving this approach focus on retrieval-augmented generation (RAG) metrics such as accuracy and recall and can be categorized into two types: (a) fine-tuning on large question answering (QA) datasets augmented with chain-of-thought traces, and (b) leveraging RL-based fine-tuning techniques that rely on question-document relevance signals. However, efficiency in the number of retrieval searches is an equally important metric, which has received less attention. In this work, we show that: (1) Large-scale fine-tuning is not needed to improve RAG metrics, contrary to popular claims in recent literature. Specifically, a standard ReAct pipeline with improved prompts can outperform state-of-the-art methods on benchmarks such as HotPotQA. (2) Supervised and RL-based fine-tuning can help RAG from the perspective of frugality, i.e., the latency due to number of searches at inference time. For example, we show that we can achieve competitive RAG metrics at nearly half the cost (in terms of number of searches) on popular RAG benchmarks, using the same base model, and at a small training cost (1000 examples).
Robust Learning of Diverse Code Edits
Mar 05, 2025Software engineering activities frequently involve edits to existing code. However, contemporary code language models (LMs) lack the ability to handle diverse types of code-edit requirements. In this work, we attempt to overcome this shortcoming through (1) a novel synthetic data generation pipeline and (2) a robust model adaptation algorithm. Starting with seed code examples and diverse editing criteria, our pipeline generates high-quality samples comprising original and modified code, along with natural language instructions in different styles and verbosity. Today's code LMs come bundled with strong abilities, such as code generation and instruction following, which should not be lost due to fine-tuning. To ensure this, we propose a novel adaptation algorithm, SeleKT, that (a) leverages a dense gradient-based step to identify the weights that are most important for code editing, and (b) does a sparse projection onto the base model to avoid overfitting. Using our approach, we obtain a new series of models NextCoder (adapted from QwenCoder-2.5) that achieves strong results on five code-editing benchmarks, outperforming comparable size models and even several larger ones. We show the generality of our approach on two model families (DeepSeekCoder and QwenCoder), compare against other fine-tuning approaches, and demonstrate robustness by showing retention of code generation abilities post adaptation.
Plan$\times$RAG: Planning-guided Retrieval Augmented Generation
Oct 28, 2024



We introduce Planning-guided Retrieval Augmented Generation (Plan$\times$RAG), a novel framework that augments the \emph{retrieve-then-reason} paradigm of existing RAG frameworks to \emph{plan-then-retrieve}. Plan$\times$RAG formulates a reasoning plan as a directed acyclic graph (DAG), decomposing queries into interrelated atomic sub-queries. Answer generation follows the DAG structure, allowing significant gains in efficiency through parallelized retrieval and generation. While state-of-the-art RAG solutions require extensive data generation and fine-tuning of language models (LMs), Plan$\times$RAG incorporates frozen LMs as plug-and-play experts to generate high-quality answers. Compared to existing RAG solutions, Plan$\times$RAG demonstrates significant improvements in reducing hallucinations and bolstering attribution due to its structured sub-query decomposition. Overall, Plan$\times$RAG offers a new perspective on integrating external knowledge in LMs while ensuring attribution by design, contributing towards more reliable LM-based systems.
ASTRA: Accurate and Scalable ANNS-based Training of Extreme Classifiers
Sep 30, 2024`Extreme Classification'' (or XC) is the task of annotating data points (queries) with relevant labels (documents), from an extremely large set of $L$ possible labels, arising in search and recommendations. The most successful deep learning paradigm that has emerged over the last decade or so for XC is to embed the queries (and labels) using a deep encoder (e.g. DistilBERT), and use linear classifiers on top of the query embeddings. This architecture is of appeal because it enables millisecond-time inference using approximate nearest neighbor search (ANNS). The key question is how do we design training algorithms that are accurate as well as scale to $O(100M)$ labels on a limited number of GPUs. State-of-the-art XC techniques that demonstrate high accuracies (e.g., DEXML, Ren\'ee, DEXA) on standard datasets have per-epoch training time that scales as $O(L)$ or employ expensive negative sampling strategies, which are prohibitive in XC scenarios. In this work, we develop an accurate and scalable XC algorithm ASTRA with two key observations: (a) building ANNS index on the classifier vectors and retrieving hard negatives using the classifiers aligns the negative sampling strategy to the loss function optimized; (b) keeping the ANNS indices current as the classifiers change through the epochs is prohibitively expensive while using stale negatives (refreshed periodically) results in poor accuracy; to remedy this, we propose a negative sampling strategy that uses a mixture of importance sampling and uniform sampling. By extensive evaluation on standard XC as well as proprietary datasets with 120M labels, we demonstrate that ASTRA achieves SOTA precision, while reducing training time by 4x-15x relative to the second best.
CROSS-JEM: Accurate and Efficient Cross-encoders for Short-text Ranking Tasks
Sep 15, 2024Ranking a set of items based on their relevance to a given query is a core problem in search and recommendation. Transformer-based ranking models are the state-of-the-art approaches for such tasks, but they score each query-item independently, ignoring the joint context of other relevant items. This leads to sub-optimal ranking accuracy and high computational costs. In response, we propose Cross-encoders with Joint Efficient Modeling (CROSS-JEM), a novel ranking approach that enables transformer-based models to jointly score multiple items for a query, maximizing parameter utilization. CROSS-JEM leverages (a) redundancies and token overlaps to jointly score multiple items, that are typically short-text phrases arising in search and recommendations, and (b) a novel training objective that models ranking probabilities. CROSS-JEM achieves state-of-the-art accuracy and over 4x lower ranking latency over standard cross-encoders. Our contributions are threefold: (i) we highlight the gap between the ranking application's need for scoring thousands of items per query and the limited capabilities of current cross-encoders; (ii) we introduce CROSS-JEM for joint efficient scoring of multiple items per query; and (iii) we demonstrate state-of-the-art accuracy on standard public datasets and a proprietary dataset. CROSS-JEM opens up new directions for designing tailored early-attention-based ranking models that incorporate strict production constraints such as item multiplicity and latency.
MASAI: Modular Architecture for Software-engineering AI Agents
Jun 17, 2024A common method to solve complex problems in software engineering, is to divide the problem into multiple sub-problems. Inspired by this, we propose a Modular Architecture for Software-engineering AI (MASAI) agents, where different LLM-powered sub-agents are instantiated with well-defined objectives and strategies tuned to achieve those objectives. Our modular architecture offers several advantages: (1) employing and tuning different problem-solving strategies across sub-agents, (2) enabling sub-agents to gather information from different sources scattered throughout a repository, and (3) avoiding unnecessarily long trajectories which inflate costs and add extraneous context. MASAI enabled us to achieve the highest performance (28.33% resolution rate) on the popular and highly challenging SWE-bench Lite dataset consisting of 300 GitHub issues from 11 Python repositories. We conduct a comprehensive evaluation of MASAI relative to other agentic methods and analyze the effects of our design decisions and their contribution to the success of MASAI.
Task Facet Learning: A Structured Approach to Prompt Optimization
Jun 15, 2024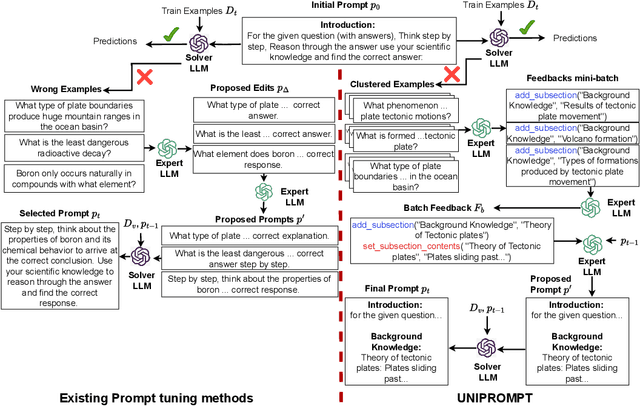
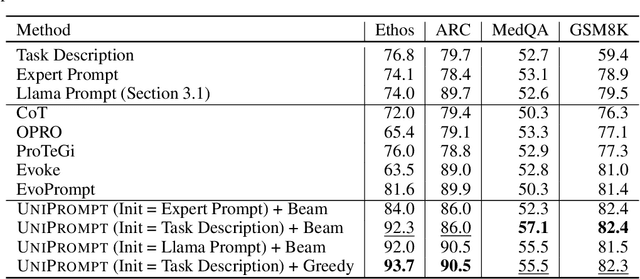
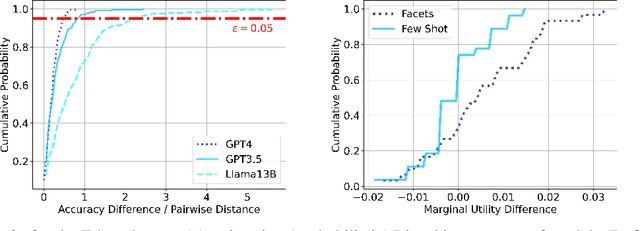

Given a task in the form of a basic description and its training examples, prompt optimization is the problem of synthesizing the given information into a text prompt for a large language model (LLM). Humans solve this problem by also considering the different facets that define a task (e.g., counter-examples, explanations, analogies) and including them in the prompt. However, it is unclear whether existing algorithmic approaches, based on iteratively editing a given prompt or automatically selecting a few in-context examples, can cover the multiple facets required to solve a complex task. In this work, we view prompt optimization as that of learning multiple facets of a task from a set of training examples. We identify and exploit structure in the prompt optimization problem -- first, we find that prompts can be broken down into loosely coupled semantic sections that have a relatively independent effect on the prompt's performance; second, we cluster the input space and use clustered batches so that the optimization procedure can learn the different facets of a task across batches. The resulting algorithm, UniPrompt, consists of a generative model to generate initial candidates for each prompt section; and a feedback mechanism that aggregates suggested edits from multiple mini-batches into a conceptual description for the section. Empirical evaluation on multiple datasets and a real-world task shows that prompts generated using UniPrompt obtain higher accuracy than human-tuned prompts and those from state-of-the-art methods. In particular, our algorithm can generate long, complex prompts that existing methods are unable to generate. Code for UniPrompt will be available at \url{https://aka.ms/uniprompt}.