 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Facet Learning: A Structured Approach to Prompt Optimization
Paper and Code
Jun 15, 2024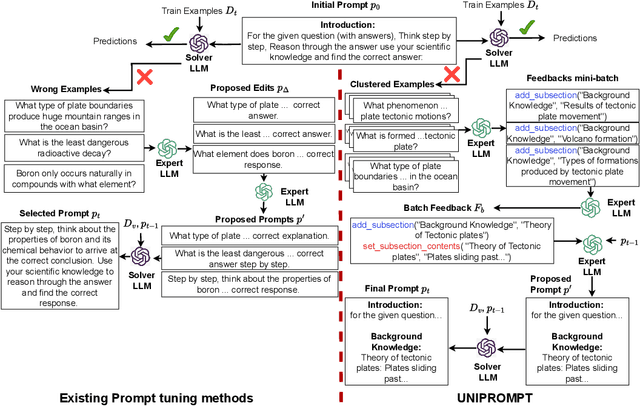
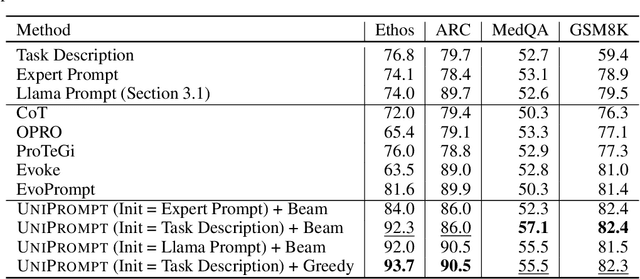
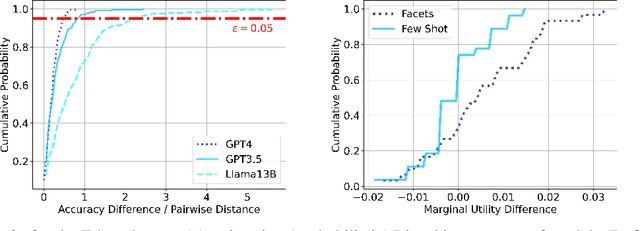

Given a task in the form of a basic description and its training examples, prompt optimization is the problem of synthesizing the given information into a text prompt for a large language model (LLM). Humans solve this problem by also considering the different facets that define a task (e.g., counter-examples, explanations, analogies) and including them in the prompt. However, it is unclear whether existing algorithmic approaches, based on iteratively editing a given prompt or automatically selecting a few in-context examples, can cover the multiple facets required to solve a complex task. In this work, we view prompt optimization as that of learning multiple facets of a task from a set of training examples. We identify and exploit structure in the prompt optimization problem -- first, we find that prompts can be broken down into loosely coupled semantic sections that have a relatively independent effect on the prompt's performance; second, we cluster the input space and use clustered batches so that the optimization procedure can learn the different facets of a task across batches. The resulting algorithm, UniPrompt, consists of a generative model to generate initial candidates for each prompt section; and a feedback mechanism that aggregates suggested edits from multiple mini-batches into a conceptual description for the section. Empirical evaluation on multiple datasets and a real-world task shows that prompts generated using UniPrompt obtain higher accuracy than human-tuned prompts and those from state-of-the-art methods. In particular, our algorithm can generate long, complex prompts that existing methods are unable to generate. Code for UniPrompt will be available at \url{https://aka.ms/uniprompt}.