 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Perturbation: Learning to Perturb Gradients for Adaptive Training
May 28, 2026Deep neural network training involves both forward propagation (from features through logits to loss) and backward propagation (from loss through gradients to parameter updates). While perturbations along the forward chain, including feature perturbation, logit perturbation, and label perturbation, have been extensively studied, the backward chain's gradient perturbation has received little systematic investigation. In this paper, we establish a unified framework for gradient perturbation, revealing that existing methods such as Sharpness-Aware Minimization (SAM), gradient clipping, and gradient noise injection can all be interpreted as imposing specific forms of gradient perturbation. Analogous to the recently proposed Logit Perturbation Learning (LPL), we conjecture that amplifying the gradient norm for a class acts as positive augmentation (enhancing learning), while dampening it acts as negative augmentation (suppressing overfitting). Based on these observations, we propose Learning to Perturb Gradients (LPG), which adaptively perturbs logit-level gradients at the class level to achieve category-aware training. We also establish theoretical connections between gradient perturbation bounds and generalization guarantees via PAC-Bayesian analysis. Experiments on balanced classification, long-tail classification, and noisy label learning demonstrate that LPG consistently outperforms existing methods and can be combined with them as a plug-in module.
Learning to Perturb Hidden Representations for Generalizable Deep Learning
May 28, 2026Deep neural networks process data through a cascade of representations: input features, hidden activations, logits, and loss. While perturbations at the input, logit, and label levels have been systematically studied, the intermediate hidden activations, which constitute the bulk of the network's computation, have received no unified perturbation analysis. In this paper, we establish a unified framework for hidden activation perturbation, revealing that Dropout, Manifold Mixup, adversarial feature perturbation, and related methods all impose specific forms of activation perturbation but with class-agnostic or random strategies. We conjecture that expansive perturbation (increasing activation norm) acts as positive augmentation, while contractive perturbation (decreasing activation norm) acts as negative augmentation, and that the perturbation layer determines whether the effect resembles input-level augmentation (shallow layers) or logit-level manipulation (deep layers). We propose Learning to Perturb Activations (LPA), which adaptively perturbs activations at a selected hidden layer with class-level perturbations learned via PGD. We further provide theoretical analysis connecting activation perturbation to flat minima and perturbation amplification through layers. Experiments on balanced classification, long-tail classification, and domain generalization demonstrate that LPA consistently outperforms existing methods and provides complementary benefits to logit perturbation methods such as LPL.
Clustering based on Stochastic Dominance with application for risk averters and risk seekers
May 23, 2026Stochastic Dominance (SD) theory provides a rigorous framework for selecting superior assets tailored to the asset allocation needs of investors with varying risk preferences (i.e., risk-averse, risk-seeking, and risk-neutral). However, traditional stock clustering methods typically rely on geometric metrics such as Euclidean distance, which often fail to effectively capture the intrinsic risk dominance relationships among assets. To address this limitation, this paper proposes an innovative clustering analysis framework based on SD test statistics. Methodologically, this study deeply integrates SD theory with machine learning algorithms. Transcending the limitations of traditional reliance on geometric distance, we innovatively utilize test statistics from first-, second-, and third-order SD to construct a "Stochastic Dominance Coefficient Matrix." Building upon this matrix, we modify the classic K-means and Hierarchical Clustering algorithms. Specifically, we derive 12 distinct algorithm variants tailored to different orders of SD relationships. Simultaneously, we construct the SD-SC coefficient and the SD-DBI index as specialized validity indices to evaluate the clustering performance. Empirically, we analyze constituent stock data from a representative developed market (the US NASDAQ Index) and an emerging market (China's CSI 100 Index). The results verify the effectiveness and robustness of the proposed method. Furthermore, we apply the clustering results to the modification of the Single Index Model and the construction of Global Minimum Variance Portfolios (GMVP). The findings demonstrate that the proposed method effectively facilitates customized asset allocation for investors, holding significant theoretical value and practical implications.
DongYuan: An LLM-Based Framework for Integrative Chinese and Western Medicine Spleen-Stomach Disorders Diagnosis
Mar 30, 2026The clinical burden of spleen-stomach disorders is substantial. While large language models (LLMs) offer new potential for medical applications, they face three major challenges in the context of integrative Chinese and Western medicine (ICWM): a lack of high-quality data, the absence of models capable of effectively integrating the reasoning logic of traditional Chinese medicine (TCM) syndrome differentiation with that of Western medical (WM) disease diagnosis, and the shortage of a standardized evaluation benchmark. To address these interrelated challenges, we propose DongYuan, an ICWM spleen-stomach diagnostic framework. Specifically, three ICWM datasets (SSDF-Syndrome, SSDF-Dialogue, and SSDF-PD) were curated to fill the gap in high-quality data for spleen-stomach disorders. We then developed SSDF-Core, a core diagnostic LLM that acquires robust ICWM reasoning capabilities through a two-stage training regimen of supervised fine-tuning. tuning (SFT) and direct preference optimization (DPO), and complemented it with SSDF-Navigator, a pluggable consultation navigation model designed to optimize clinical inquiry strategies. Additionally, we established SSDF-Bench, a comprehensive evaluation benchmark focused on ICWM diagnosis of spleen-stomach disorders. Experimental results demonstrate that SSDF-Core significantly outperforms 12 mainstream baselines on SSDF-Bench. DongYuan lays a solid methodological foundation and provides practical technical references for the future development of intelligent ICWM diagnostic systems.
PerformRecast: Expression and Head Pose Disentanglement for Portrait Video Editing
Mar 20, 2026This paper primarily investigates the task of expression-only portrait video performance editing based on a driving video, which plays a crucial role in animation and film industries. Most existing research mainly focuses on portrait animation, which aims to animate a static portrait image according to the facial motion from the driving video. As a consequence, it remains challenging for them to disentangle the facial expression from head pose rotation and thus lack the ability to edit facial expression independently. In this paper, we propose PerformRecast, a versatile expression-only video editing method which is dedicated to recast the performance in existing film and animation. The key insight of our method comes from the characteristics of 3D Morphable Face Model (3DMM), which models the face identity, facial expression and head pose of 3D face mesh with separate parameters. Therefore, we improve the keypoints transformation formula in previous methods to make it more consistent with 3DMM model, which achieves a better disentanglement and provides users with much more fine-grained control. Furthermore, to avoid the misalignment around the boundary of face in generated results, we decouple the facial and non-facial regions of input portrait images and pre-train a teacher model to provide separate supervision for them. Extensive experiments show that our method produces high-quality results which are more faithful to the driving video, outperforming existing methods in both controllability and efficiency. Our code, data and trained models are available at https://youku-aigc.github.io/PerformRecast.
Fine-Tuning Diffusion-Based Recommender Systems via Reinforcement Learning with Reward Function Optimization
Nov 10, 2025Diffusion models recently emerged as a powerful paradigm for recommender systems, offering state-of-the-art performance by modeling the generative process of user-item interactions. However, training such models from scratch is both computationally expensive and yields diminishing returns once convergence is reached. To remedy these challenges, we propose ReFiT, a new framework that integrates Reinforcement learning (RL)-based Fine-Tuning into diffusion-based recommender systems. In contrast to prior RL approaches for diffusion models depending on external reward models, ReFiT adopts a task-aligned design: it formulates the denoising trajectory as a Markov decision process (MDP) and incorporates a collaborative signal-aware reward function that directly reflects recommendation quality. By tightly coupling the MDP structure with this reward signal, ReFiT empowers the RL agent to exploit high-order connectivity for fine-grained optimization, while avoiding the noisy or uninformative feedback common in naive reward designs. Leveraging policy gradient optimization, ReFiT maximizes exact log-likelihood of observed interactions, thereby enabling effective post hoc fine-tuning of diffusion recommenders. Comprehensive experiments on wide-ranging real-world datasets demonstrate that the proposed ReFiT framework (a) exhibits substantial performance gains over strong competitors (up to 36.3% on sequential recommendation), (b) demonstrates strong efficiency with linear complexity in the number of users or items, and (c) generalizes well across multiple diffusion-based recommendation scenarios. The source code and datasets are publicly available at https://anonymous.4open.science/r/ReFiT-4C60.
WaterFlow: Explicit Physics-Prior Rectified Flow for Underwater Saliency Mask Generation
Oct 14, 2025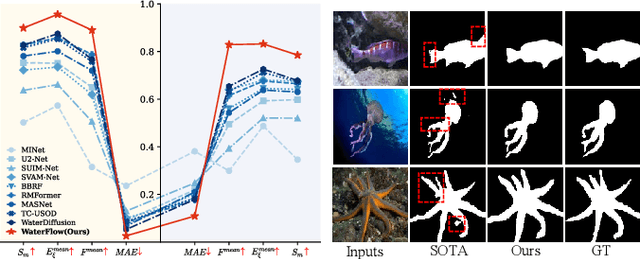
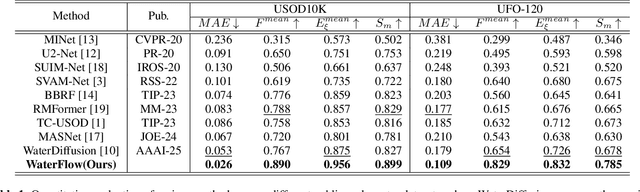
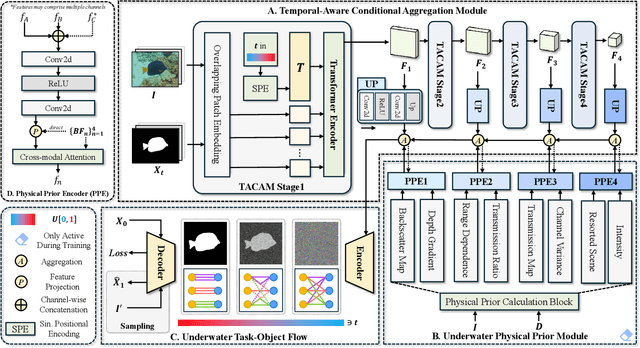

Underwater Salient Object Detection (USOD) faces significant challenges, including underwater image quality degradation and domain gaps. Existing methods tend to ignore the physical principles of underwater imaging or simply treat degradation phenomena in underwater images as interference factors that must be eliminated, failing to fully exploit the valuable information they contain. We propose WaterFlow, a rectified flow-based framework for underwater salient object detection that innovatively incorporates underwater physical imaging information as explicit priors directly into the network training process and introduces temporal dimension modeling, significantly enhancing the model's capability for salient object identification. On the USOD10K dataset, WaterFlow achieves a 0.072 gain in S_m, demonstrating the effectiveness and superiority of our method. The code will be published after the acceptance.
UWSAM: Segment Anything Model Guided Underwater Instance Segmentation and A Large-scale Benchmark Dataset
May 21, 2025With recent breakthroughs in large-scale modeling, the Segment Anything Model (SAM) has demonstrated significant potential in a variety of visual applications. However, due to the lack of underwater domain expertise, SAM and its variants face performance limitations in end-to-end underwater instance segmentation tasks, while their higher computational requirements further hinder their application in underwater scenarios. To address this challenge, we propose a large-scale underwater instance segmentation dataset, UIIS10K, which includes 10,048 images with pixel-level annotations for 10 categories. Then, we introduce UWSAM, an efficient model designed for automatic and accurate segmentation of underwater instances. UWSAM efficiently distills knowledge from the SAM ViT-Huge image encoder into the smaller ViT-Small image encoder via the Mask GAT-based Underwater Knowledge Distillation (MG-UKD) method for effective visual representation learning. Furthermore, we design an End-to-end Underwater Prompt Generator (EUPG) for UWSAM, which automatically generates underwater prompts instead of explicitly providing foreground points or boxes as prompts, thus enabling the network to locate underwater instances accurately for efficient segmentation. Comprehensive experimental results show that our model is effective, achieving significant performance improvements over state-of-the-art methods on multiple underwater instance datasets. Datasets and codes are available at https://github.com/LiamLian0727/UIIS10K.
TUGS: Physics-based Compact Representation of Underwater Scenes by Tensorized Gaussian
May 12, 2025Underwater 3D scene reconstruction is crucial for undewater robotic perception and navigation. However, the task is significantly challenged by the complex interplay between light propagation, water medium, and object surfaces, with existing methods unable to model their interactions accurately. Additionally, expensive training and rendering costs limit their practical application in underwater robotic systems. Therefore, we propose Tensorized Underwater Gaussian Splatting (TUGS), which can effectively solve the modeling challenges of the complex interactions between object geometries and water media while achieving significant parameter reduction. TUGS employs lightweight tensorized higher-order Gaussians with a physics-based underwater Adaptive Medium Estimation (AME) module, enabling accurate simulation of both light attenuation and backscatter effects in underwater environments. Compared to other NeRF-based and GS-based methods designed for underwater, TUGS is able to render high-quality underwater images with faster rendering speeds and less memory usage. Extensive experiments on real-world underwater datasets have demonstrated that TUGS can efficiently achieve superior reconstruction quality using a limited number of parameters, making it particularly suitable for memory-constrained underwater UAV applications
Mamba Based Feature Extraction And Adaptive Multilevel Feature Fusion For 3D Tumor Segmentation From Multi-modal Medical Image
Apr 30, 2025Multi-modal 3D medical image segmentation aims to accurately identify tumor regions across different modalities, facing challenges from variations in image intensity and tumor morphology. Traditional convolutional neural network (CNN)-based methods struggle with capturing global features, while Transformers-based methods, despite effectively capturing global context, encounter high computational costs in 3D medical image segmentation. The Mamba model combines linear scalability with long-distance modeling, making it a promising approach for visual representation learning. However, Mamba-based 3D multi-modal segmentation still struggles to leverage modality-specific features and fuse complementary information effectively. In this paper, we propose a Mamba based feature extraction and adaptive multilevel feature fusion for 3D tumor segmentation using multi-modal medical image. We first develop the specific modality Mamba encoder to efficiently extract long-range relevant features that represent anatomical and pathological structures present in each modality. Moreover, we design an bi-level synergistic integration block that dynamically merges multi-modal and multi-level complementary features by the modality attention and channel attention learning. Lastly, the decoder combines deep semantic information with fine-grained details to generate the tumor segmentation map. Experimental results on medical image datasets (PET/CT and MRI multi-sequence) show that our approach achieve competitive performance compared to the state-of-the-art CNN, Transformer, and Mamba-based approaches.